推荐系统是一个技术驱动但是远不能满足产品需求的方案。是有极大的改良空间的。这种改良未必来自于技术本身,可以来自产品,规则等多个非技术相关的维度。
推荐系统的一些坑
-
评价指标——推荐本身的误差与妥协
评价指标难以评选和量化。推荐本身并不是一个充分定义和约束的过程,ta更像是宏观调控。进而在实践和落实到指标设计时,会有严重的妥协和设计误差。- 高CTR——擦边球、软色情、标题党、封面党 的问题就会快速浮现出来。
- 高Staytime——视频+文章Feed流会在自然选择中成为视频feed流 + 超长文章Feed流。
- 高read/U——短文章就会有分发优势。
这些指标相互依赖,此消彼长,目前主流是沿用计算广告的老路,按照CTR作为最广泛使用的评价指标来优化,这个指标的劣根性是显而易见的,然而至今并没有很好地指标来指导系统。
今日头条的做法是,优化CTR同时关注其他指标的变动;也有的从CTR开始,优化到瓶颈后进行Staytime的优化等等…
Medium的做法是,优化一个F(CTR, staytime,…)的多指标加权的综合指标,但这个加权的系数,还是一个magic number,是人拍脑门定的。
Pornhub的做法是,优化一个-staytime的指标,用户停留时长越短,则越好,其基本假设就是“撸完嫌人丑”。很多人对这个指标拍案叫绝,但是其实这给公司的商业化部门带来很大压力,因为如果用户停留时间短,则流量变现会变得很困难。大家都在探索, 也并没有一个定论,究竟推荐系统该优化一些什么。相信很多人刚入行的时候对单纯优化CTR都是有疑惑的,日子久了,也就都麻木了。
-
推荐本身的矛盾性——好的算法与不那么好的效果
有的算法确实很好,好到推荐的每个我都想点,但是算法越精准,在用户体验上未必是越好的。
举个例子,我喜欢汽车,电竞和科技。好的推荐算法真的就推荐汽车电竞和科技,都是根据我的历史记录推荐的我确实喜欢的。但也就只有汽车电竞和科技而已。
换句话说,好的推荐算法毫无疑问地会局限你的视野。那他还是好的推荐算法么?——推荐需要随机性
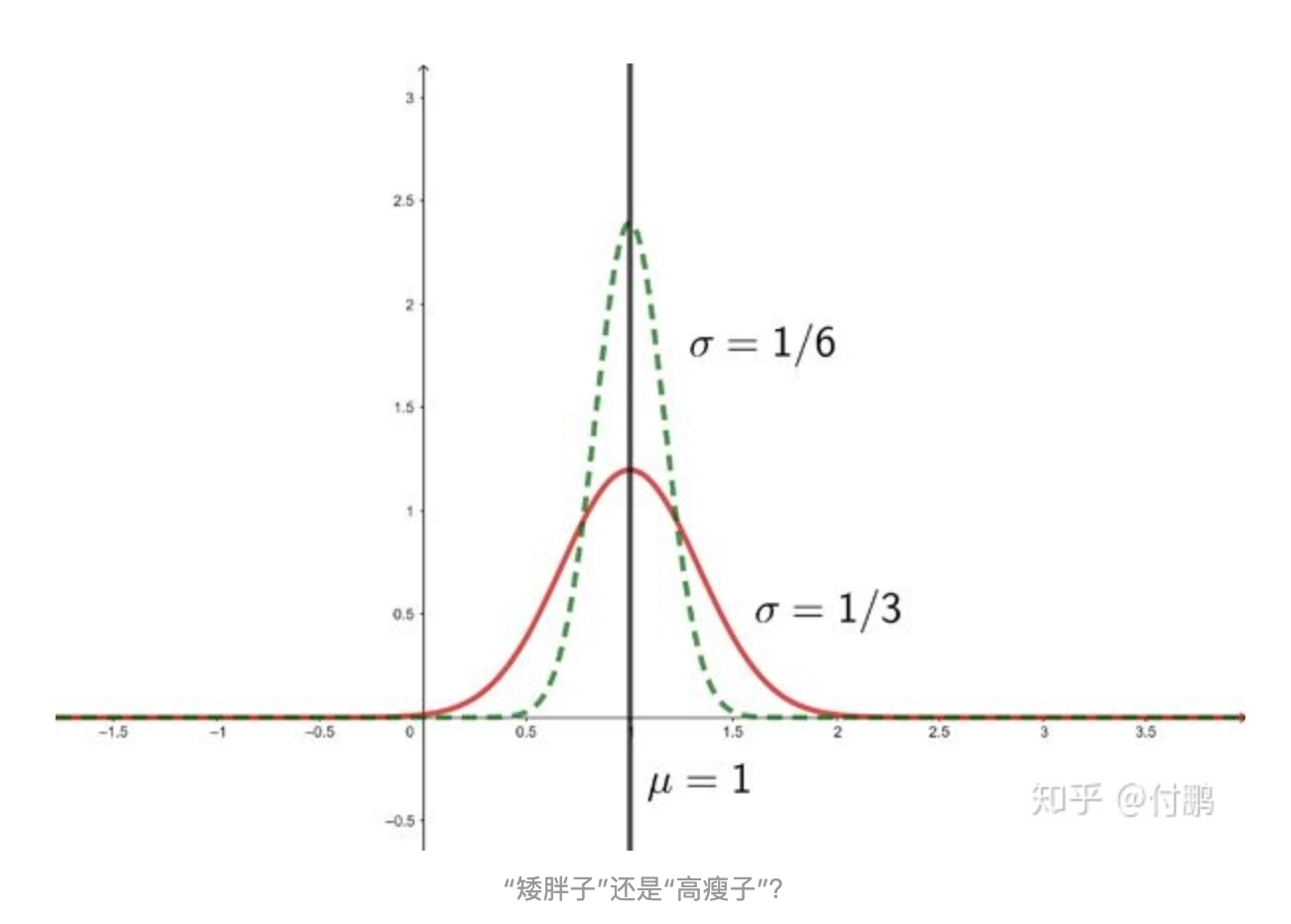
推荐本身是很矛盾的,因为用户没有明确说明自己要看什么,也没有明确表示自己不愿意看什么。一个稍微差一点的推荐算法,是不是反而长期看是体验更好的?因为它不仅照顾了用户的核心兴趣,也稍稍辐射了一些边缘领域,在感兴趣和不感兴趣的边缘试探着。就像下面这个高斯分布的图,绿色的“高瘦子”毫无疑问要优于红色的“矮胖子”,因为它像一把尖刀,更精准地直插兴趣点,但是究竟“精准的高瘦子”是不是真的好呢?
-
E&E
E&E, exploration & exploitation,这个真的是天问。
E&E,简单说,就是保证精准推荐的同时,进行兴趣探索。所有推荐系统做的最差的地方——我看了一个东西,就使劲出一个东西,App明明很多东西,我却越用越窄。
EE要不要做?肯定要做,你不能让用户只能看到一类Feed,这样久了他的feed 流只会越来越小,自己也觉得没劲,所以一定要做兴趣探索。但是做,就势必牺牲指标,探索的过程是艰难的,大部分时间用户体验上也是负向的。
那么问题来了。
那么,- 牺牲多少CTR来保EE才算是合适的?
- EE的ROI什么时候算是>1的?
- 怎么样确定EE的效果?
- EE要E到什么程度?
-
线下auc涨,线上ctr/cpm跌
- 特征/数据出现穿越。
一般就是使用了和label强相关的特征导致的数据泄漏。这种问题一般相对好查,很多时候在离线阶段就能发现。明显的表现就是训练集和测试集差异比较大。 - 线上线下特征不一致
这种情况是导致离线涨在线跌或者没效果的最常见情况。
首先是代码不一致,例如,离线对用户特征的加工处理采用scala/python处理,抽取用户最近的50个行为,在线特征抽取用c++实现只用了30个。只要离线和在线用不同的代码抽取就很容易存在这种代码带来的不一致。
另外一种线上线下不一致,是由于数据的不一致导致。这在离线拼接样本和特征的pipeline中比较常见。一般离线特征都是按照天处理的,考虑各种数据pipeline的流程,处理时间一般都会有延迟,离线特征处理完之后导到线上供线上模型预估时请求使用。
要严格保证线上线下的特征一致性,最根本的方法就是同一套代码和数据源抽取特征,业内目前通用的方法就是,在线实时请求打分的时候落地实时特征,训练的时候就没有特征拼接的流程,只需要关联label,生成正负样本即可
- 数据分布的不一致
如果仔细排查,既不存在数据泄漏,也没有出现不一致的问题,离线auc明明就是涨了很多,线上就是下降,而且是离线涨的越多,线上下降越多,还有一种可能就是数据的不一致,也就是数据的“冰山效应”----离线训练用的是有偏的冰山上的数据,而在线上预估的时候,需要预测的是整个冰山的数据,包括大量冰面以下的数据!
- 特征/数据出现穿越。
-
工程相关的问题
-
数据工程
日志去重问题,日志中正例丢失分析和处理的问题,作弊流量清洗的问题,样本迁移学习的问题等等。 -
特征工程
用户行为特征如何结构化。session内用户行为特征如何设计。
长尾item CTR预估偏高,如何设计特征进行打压的问题。
高阶特征如何自动挖掘的问题 -
模型工程
- 如何优化计算框架和算法,支持千亿特征规模的问题
- 如何优化召回算法和排序算法不一致性带来的信息损失
- 如何把多样性控制、打散、疲劳控制等机制策略融入到模型训练中去的问题
- 如何优化FTRL来更好地刻画最新样本的问题
- 还有很多,像CF怎么优化的问题。
-
系统工程
没有强大的工程系统支持的算法都是实验室的玩具。- 实时样本流中日志如何对齐的问题
- 如何保证样本流稳定性和拼接正确性
- 调研样本如何获取动态特征的问题:服务端落快照和离线挖出实时特征
- 基于fealib保证线上线下特征抽取的一致性问题
- 在线预估服务怎么优化特征抽取的性能。如何支持超大规模模型的分布式存储,主流的模型通常在100G以上规模了
- 内容系统进行如何实时内容理解,如何实时构建索引,以及高维索引等相关问题
多样性怎么保证,E&E怎么去做,内容质量怎么评级,低俗内容如何打压。如何做全场景化的推荐引擎使得各页面各栏位能更好地配合推荐。
-
Youtube推荐系统
其实我一直觉得YouTube的推荐有点弱智。。。
Deep Neural Networks for YouTube Recommendations (2016)