C++11 新增特性
空指针 nullptr
nullptr 出现的目的是为了替代 NULL。
C++11之前官方标准对NULL、0没有严格的区分,更多的是取决于不同编译器的选择,有些编译器会将 NULL 定义为 ((void*)0),有些则会直接将其定义为 0。
C++ 不允许直接将 void * 隐式转换到其他类型,但如果 NULL 被定义为 ((void*)0),那么当编译char *ch = NULL;时,NULL 只好被定义为 0。
这显然会产生问题,导致了 C++ 中重载特性会发生混乱,如:
1 | void foo(char *); |
2 | void foo(int); |
如果 NULL 又被定义为了 0 那么 foo(NULL)将会去调用 foo(int),从而导致代码违反直观。
为了解决这个问题,C++11 引入了 nullptr 关键字,专门用来区分__空指针、0__。
nullptr 的类型为 nullptr_t,能够隐式的转换为任何指针或成员指针的类型,也能和他们进行相等或者不等运算。
当需要使用 NULL 时候,养成直接使用 nullptr 的习惯
智能指针 Smart Pointer
C++11中引入了智能指针的概念,方便管理堆内存。使用普通指针,容易造成堆内存泄露(忘记释放),二次释放,程序发生异常时内存泄露等问题等,使用智能指针能更好的管理堆内存。
理解智能指针:
- 从较浅的层面看,智能指针是利用了一种叫做RAII(资源获取即初始化)的技术对普通的指针进行封装,这使得智能指针实质是一个对象,行为表现的却像一个指针。
- 智能指针的作用是防止忘记调用delete释放内存和程序异常的进入catch块忘记释放内存。另外指针的释放时机也是非常有考究的,多次释放同一个指针会造成程序崩溃,这些都可以通过智能指针来解决。
- 智能指针还有一个作用是把值语义转换成引用语义。C++和Java有一处最大的区别在于语义不同。
1 | Animal a = new Animal(); |
2 | Animal b = a; |
3 | |
4 | //java这里其实只生成了一个对象,a和b仅仅是把持对象的引用而已。但在C++中不是这样, |
5 | Animal a; |
6 | Animal b = a; //这里却是就是生成了两个对象。 |
C++11标准引入智能指针,包含在头文件
shared_ptr
shared_ptr多个指针指向相同的对象。shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。每使用他一次,内部的引用计数加1,每析构一次,内部的引用计数减1,减为0时,自动删除所指向的堆内存。shared_ptr内部的引用计数是线程安全的,但是对象的读取需要加锁。
- 初始化。
智能指针是个模板类,可以指定类型,传入指针通过构造函数初始化。也可以使用make_shared函数初始化。不能将指针直接赋值给一个智能指针,一个是类,一个是指针。例如std::shared_ptrp4 = new int(1);的写法是错误的 - 拷贝和赋值。
拷贝使得对象的引用计数增加1,赋值使得原对象引用计数减1,当计数为0时,自动释放内存。后来指向的对象引用计数加1,指向后来的对象。 - get函数获取原始指针。
- 不要用一个原始指针初始化多个shared_ptr,否则会造成二次释放同一内存
- 避免循环引用。
shared_ptr的一个最大的陷阱是循环引用,循环引用会导致堆内存无法正确释放,导致内存泄漏。
循环引用在weak_ptr中介绍。
1 | |
2 | |
3 | |
4 | int main() { |
5 | { |
6 | int a = 10; |
7 | std::shared_ptr<int> ptra = std::make_shared<int>(a); |
8 | std::shared_ptr<int> ptra2(ptra); //copy |
9 | std::cout << ptra.use_count() << std::endl; |
10 | |
11 | int b = 20; |
12 | int *pb = &a; |
13 | //std::shared_ptr<int> ptrb = pb; //error |
14 | std::shared_ptr<int> ptrb = std::make_shared<int>(b); |
15 | ptra2 = ptrb; //assign |
16 | pb = ptrb.get(); //获取原始指针 |
17 | |
18 | std::cout << ptra.use_count() << std::endl; |
19 | std::cout << ptrb.use_count() << std::endl; |
20 | } |
21 | } |
unique_ptr
unique_ptr“唯一”拥有其所指对象,同一时刻只能有一个unique_ptr指向给定对象(通过禁止拷贝语义、只有移动语义来实现)。
相比与原始指针unique_ptr用于其RAII的特性,使得在出现异常的情况下,动态资源能得到释放。
unique_ptr指针本身的生命周期:从unique_ptr指针创建时开始,直到离开作用域。离开作用域时,若其指向对象,则将其所指对象销毁(默认使用delete操作符,用户可指定其他操作)。
unique_ptr指针与其所指对象的关系:在智能指针生命周期内,可以改变智能指针所指对象,如创建智能指针时通过构造函数指定、通过reset方法重新指定、通过release方法释放所有权、通过移动语义转移所有权。
1 | |
2 | |
3 | |
4 | int main() |
5 | { |
6 | { |
7 | std::unique_ptr<int> uptr(new int(10)); //绑定动态对象 |
8 | //std::unique_ptr<int> uptr2 = uptr; //不能賦值 |
9 | //std::unique_ptr<int> uptr2(uptr); //不能拷貝 |
10 | std::unique_ptr<int> uptr2 = std::move(uptr); //轉換所有權 |
11 | uptr2.release(); //释放所有权 |
12 | } |
13 | //超過uptr的作用域,內存釋放 |
14 | } |
weak_ptr
weak_ptr是为了配合shared_ptr而引入的一种智能指针,因为它不具有普通指针的行为,没有重载operator*和->,它的最大作用在于协助shared_ptr工作,像旁观者那样观测资源的使用情况。
weak_ptr可以从一个shared_ptr或者另一个weak_ptr对象构造,获得资源的观测权。
但weak_ptr没有共享资源,它的构造不会引起指针引用计数的增加。使用weak_ptr的成员函数use_count()可以观测资源的引用计数,另一个成员函数expired()的功能等价于use_count() == 0,但更快,表示被观测的资源(也就是shared_ptr的管理的资源)已经不复存在。
weak_ptr可以使用一个非常重要的成员函数lock()从被观测的shared_ptr获得一个可用的shared_ptr对象, 从而操作资源。但当expired()==true的时候,lock()函数将返回一个存储空指针的shared_ptr。
1 | |
2 | |
3 | |
4 | int main() { |
5 | { |
6 | std::shared_ptr<int> sh_ptr = std::make_shared<int>(10); |
7 | std::cout << sh_ptr.use_count() << std::endl; |
8 | |
9 | std::weak_ptr<int> wp(sh_ptr); |
10 | std::cout << wp.use_count() << std::endl; |
11 | |
12 | if(!wp.expired()){ |
13 | std::shared_ptr<int> sh_ptr2 = wp.lock(); //get another shared_ptr |
14 | *sh_ptr = 100; |
15 | std::cout << wp.use_count() << std::endl; |
16 | } |
17 | } |
18 | //delete memory |
19 | } |
循环引用
考虑一个简单的对象建模——家长与子女:a Parent has a Child, a Child knows his/her Parent。在Java 里边很好写,不用担心内存泄漏,也不用担心空悬指针,只要正确初始化myChild 和myParent,那么Java 程序员就不用担心出现访问错误。一个handle 是否有效,只需要判断其是否non null。
1 | public class Parent |
2 | { |
3 | private Child myChild; |
4 | } |
5 | public class Child |
6 | { |
7 | private Parent myParent; |
8 | } |
在C++ 里边就要为资源管理费一番脑筋。如果使用原始指针作为成员,Child和Parent由谁释放?那么如何保证指针的有效性?如何防止出现空悬指针?这些问题是C++面向对象编程麻烦的问题,现在可以借助smart pointer把对象语义(pointer)转变为值(value)语义,shared_ptr轻松解决生命周期的问题,不必担心空悬指针。但是这个模型存在循环引用的问题,注意其中一个指针应该为weak_ptr。
1 | //原始指针的做法,容易出错 |
2 | |
3 | |
4 | |
5 | |
6 | class Child; |
7 | class Parent; |
8 | |
9 | class Parent { |
10 | private: |
11 | Child* myChild; |
12 | public: |
13 | void setChild(Child* ch) { |
14 | this->myChild = ch; |
15 | } |
16 | |
17 | void doSomething() { |
18 | if (this->myChild) { |
19 | } |
20 | } |
21 | |
22 | ~Parent() { |
23 | delete myChild; |
24 | } |
25 | }; |
26 | |
27 | class Child { |
28 | private: |
29 | Parent* myParent; |
30 | public: |
31 | void setPartent(Parent* p) { |
32 | this->myParent = p; |
33 | } |
34 | void doSomething() { |
35 | if (this->myParent) { |
36 | } |
37 | } |
38 | ~Child() { |
39 | delete myParent; |
40 | } |
41 | }; |
42 | |
43 | int main() { |
44 | { |
45 | Parent* p = new Parent; |
46 | Child* c = new Child; |
47 | p->setChild(c); |
48 | c->setPartent(p); |
49 | delete c; //only delete one |
50 | } |
51 | return 0; |
52 | } |
循环引用内存泄露的问题
1 | |
2 | |
3 | |
4 | class Child; |
5 | class Parent; |
6 | |
7 | class Parent { |
8 | private: |
9 | std::shared_ptr<Child> ChildPtr; |
10 | public: |
11 | void setChild(std::shared_ptr<Child> child) { |
12 | this->ChildPtr = child; |
13 | } |
14 | |
15 | void doSomething() { |
16 | if (this->ChildPtr.use_count()) { |
17 | |
18 | } |
19 | } |
20 | |
21 | ~Parent() { |
22 | } |
23 | }; |
24 | |
25 | class Child { |
26 | private: |
27 | std::shared_ptr<Parent> ParentPtr; |
28 | public: |
29 | void setPartent(std::shared_ptr<Parent> parent) { |
30 | this->ParentPtr = parent; |
31 | } |
32 | void doSomething() { |
33 | if (this->ParentPtr.use_count()) { |
34 | |
35 | } |
36 | } |
37 | ~Child() { |
38 | } |
39 | }; |
40 | |
41 | int main() { |
42 | std::weak_ptr<Parent> wpp; |
43 | std::weak_ptr<Child> wpc; |
44 | { |
45 | std::shared_ptr<Parent> p(new Parent); |
46 | std::shared_ptr<Child> c(new Child); |
47 | p->setChild(c); |
48 | c->setPartent(p); |
49 | wpp = p; |
50 | wpc = c; |
51 | std::cout << p.use_count() << std::endl; // 2 |
52 | std::cout << c.use_count() << std::endl; // 2 |
53 | } |
54 | std::cout << wpp.use_count() << std::endl; // 1 |
55 | std::cout << wpc.use_count() << std::endl; // 1 |
56 | return 0; |
57 | } |
正确的做法
1 | |
2 | |
3 | |
4 | class Child; |
5 | class Parent; |
6 | |
7 | class Parent { |
8 | private: |
9 | //std::shared_ptr<Child> ChildPtr; |
10 | std::weak_ptr<Child> ChildPtr; |
11 | public: |
12 | void setChild(std::shared_ptr<Child> child) { |
13 | this->ChildPtr = child; |
14 | } |
15 | |
16 | void doSomething() { |
17 | //new shared_ptr |
18 | if (this->ChildPtr.lock()) { |
19 | |
20 | } |
21 | } |
22 | |
23 | ~Parent() { |
24 | } |
25 | }; |
26 | |
27 | class Child { |
28 | private: |
29 | std::shared_ptr<Parent> ParentPtr; |
30 | public: |
31 | void setPartent(std::shared_ptr<Parent> parent) { |
32 | this->ParentPtr = parent; |
33 | } |
34 | void doSomething() { |
35 | if (this->ParentPtr.use_count()) { |
36 | |
37 | } |
38 | } |
39 | ~Child() { |
40 | } |
41 | }; |
42 | |
43 | int main() { |
44 | std::weak_ptr<Parent> wpp; |
45 | std::weak_ptr<Child> wpc; |
46 | { |
47 | std::shared_ptr<Parent> p(new Parent); |
48 | std::shared_ptr<Child> c(new Child); |
49 | p->setChild(c); |
50 | c->setPartent(p); |
51 | wpp = p; |
52 | wpc = c; |
53 | std::cout << p.use_count() << std::endl; // 2 |
54 | std::cout << c.use_count() << std::endl; // 1 |
55 | } |
56 | std::cout << wpp.use_count() << std::endl; // 0 |
57 | std::cout << wpc.use_count() << std::endl; // 0 |
58 | return 0; |
59 | } |
智能指针的设计和实现
简单探究智能指针的设计实现。
- 智能指针类将一个计数器与类指向的对象相关联,引用计数跟踪该类有多少个对象共享同一指针。
- 每次创建类的新对象时,初始化指针并将引用计数置为1;
- 当对象作为另一对象的副本而创建时,拷贝构造函数拷贝指针并增加与之相应的引用计数;
- 对一个对象进行赋值时,赋值操作符减少左操作数所指对象的引用计数(如果引用计数为减至0,则删除对象),并增加右操作数所指对象的引用计数;
- 调用析构函数时,构造函数减少引用计数(如果引用计数减至0,则删除基础对象)。
智能指针就是模拟指针动作的类。所有的智能指针都会重载 -> 和 * 操作符。智能指针还有许多其他功能,比较有用的是自动销毁。这主要是利用栈对象的有限作用域以及临时对象(有限作用域实现)析构函数释放内存。
1 | |
2 | |
3 | |
4 | template<typename T> |
5 | class SmartPointer { |
6 | private: |
7 | T* _ptr; |
8 | size_t* _count; |
9 | public: |
10 | SmartPointer(T* ptr = nullptr) : |
11 | _ptr(ptr) { |
12 | if (_ptr) { |
13 | _count = new size_t(1); |
14 | } else { |
15 | _count = new size_t(0); |
16 | } |
17 | } |
18 | |
19 | SmartPointer(const SmartPointer& ptr) { |
20 | if (this != &ptr) { |
21 | this->_ptr = ptr._ptr; |
22 | this->_count = ptr._count; |
23 | (*this->_count)++; |
24 | } |
25 | } |
26 | |
27 | SmartPointer& operator=(const SmartPointer& ptr) { |
28 | if (this->_ptr == ptr._ptr) { |
29 | return *this; |
30 | } |
31 | |
32 | if (this->_ptr) { |
33 | (*this->_count)--; |
34 | if (this->_count == 0) { |
35 | delete this->_ptr; |
36 | delete this->_count; |
37 | } |
38 | } |
39 | |
40 | this->_ptr = ptr._ptr; |
41 | this->_count = ptr._count; |
42 | (*this->_count)++; |
43 | return *this; |
44 | } |
45 | |
46 | T& operator*() { |
47 | assert(this->_ptr == nullptr); |
48 | return *(this->_ptr); |
49 | |
50 | } |
51 | |
52 | T* operator->() { |
53 | assert(this->_ptr == nullptr); |
54 | return this->_ptr; |
55 | } |
56 | |
57 | ~SmartPointer() { |
58 | (*this->_count)--; |
59 | if (*this->_count == 0) { |
60 | delete this->_ptr; |
61 | delete this->_count; |
62 | } |
63 | } |
64 | |
65 | size_t use_count(){ |
66 | return *this->_count; |
67 | } |
68 | }; |
69 | |
70 | int main() |
71 | { |
72 | { |
73 | SmartPointer<int> sp(new int(10)); |
74 | SmartPointer<int> sp2(sp); |
75 | SmartPointer<int> sp3(new int(20)); |
76 | sp2 = sp3; |
77 | std::cout << sp.use_count() << std::endl; |
78 | std::cout << sp3.use_count() << std::endl; |
79 | } |
80 | //delete operator |
81 | } |
强枚举类型 Strongly-typed enums
为了解决c/c98中的enum类型的一系列缺点,比如:全局作用域,非强类型,允许隐式转换为int型,占用存储空间及符号性不确定。c11引入了枚举类(又称为:强枚举类型strong-typed enum)
语法格式:
1 | enum class 类型名 {枚举值表}; |
2 | |
3 | enum class People{yellow,black,white}; |
4 | //这样就成功的定义了一个强类型的枚举People。 |
5 | |
6 | 注意:等价于 enum struct 类型名{枚举值表}; |
7 | (enum class中的成员没有公有私有之分,也不会使用模板来支持泛化的功能) |
强枚举类型的优点
- 强作用域 强类型的枚举成员的名称不会被输出到其父作用域空间;
- 转换限制 强类型枚举成员的值不可以与int隐式的相互转换
- 指定底层类型 强类型枚举底层类型为int,但是也可以显示的指定底层类型。
具体方法:在enum名称后面加:“:type”,其中type可以是除wchar_t以外的任何int
1 | enum class People: char{yellow,black,white}; |
静态断言 static assert
static_assert这个关键字,用来做编译期间的断言,因此叫做静态断言。
语法格式:
1 | static_assert(常量表达式,提示字符串) |
如果第一个参数常量表达式的值为false,会产生一条编译错误,错误位置就是该static_assert语句所在行,第二个参数就是错误提示字符串。
使用static_assert,我们可以在编译期间发现更多的错误,用编译器来强制保证一些契约,并帮助我们改善编译信息的可读性,尤其是用于模板的时候。
static_assert可以用在全局作用域中,命名空间中,类作用域中,函数作用域中,几乎可以不受限制的使用。由于是static_assert编译期间断言,不生成目标代码,因此static_assert不会造成任何运行期性能损失。
编译器在遇到一个static_assert语句时,通常立刻将其第一个参数作为常量表达式进行演算,但如果该常量表达式依赖于某些模板参数,则延迟到模板实例化时再进行演算,这就让检查模板参数成为了可能。
C++03标准中,就有assert、#error两个设施,也是用来检查错误的,还有一些第三方的静态断言实现。
assert
assert是运行期断言,它用来发现运行期间的错误,不能提前到编译期发现错误,也不具有强制性,也谈不上改善编译信息的可读性,既然是运行期检查,对性能当然是有影响的,所以经常在发行版本中,assert都会被关掉。
#error
#error可看做预编译期断言,甚至都算不上断言,仅仅能在预编译时显示一个错误信息,它能做的不多,可以配合#ifdef/ifndef参与预编译的条件检查,由于它无法获得编译信息,当然就做不了更进一步分析了。
noexcept
C++98中,在函数声明时,我们使用throw指定一个函数可以抛出异常的类型。例如:
1 | class Ex { |
2 | public: |
3 | double getVal(); |
4 | void display() throw(); |
5 | void setVal(int i) throw (char*, double); |
6 | private: |
7 | int m_val; |
8 | }; |
上述函数的声明指定了该函数可以抛出异常的类型:
- getVal() 可以抛出任何异常(默认);
- display() 不可以抛出任何异常;
- setVal() 只可以抛出char* 和 double类型异常。
从功能上来说,C98中的异常处理机制完全能满足我们的需要,正确的处理异常。
然而,编译器为了遵守C语言标准,在编译时,只检查部分函数的异常规格(exception specification)。
注意: exception specification: 函数名字后面的throw表达式,或者noexcept
1 | // declaration |
2 | extern void funAny(void); //May throw ANY exception. |
3 | void check(void) throw (std::out_of_range); // May throw only std::out_of_range. |
4 | |
5 | // implementation |
6 | void check(void) throw(std::out_of_range) { |
7 | funAny(); // Compiler does not check if |
8 | ... // funAny(), or one of its |
9 | } // subordinates, only throws std::out_of_range! |
程序在运行时,如果funAny()抛出一个异常,
但是它的类型不是std::out_of_range, 异常处理机制将调用std::unexpected()(该函数自己也可能抛出异常),
这个函数默认情况下会调用std::teminate()。
编译器在编译时能过做的检测非常有限,因此在C++11中异常声明被简化为以下两种情况:
- 函数可以抛出任何异常(和之前的默认情况相同)
- 函数不可以抛出任何异常
在C++11中,声明一个函数不可以抛出任何异常使用关键字noexcept。
1 | void mightThrow(); // 可以抛出任意异常 |
2 | void doesNotThrow() noexcept; //不抛出任何异常 |
3 | |
4 | //下面两个函数声明的异常规格在语义上是相同的,都表示函数不抛出任何异常。 |
5 | void old_stytle() throw(); |
6 | void new_style() noexcept; |
它们的区别在于程序运行时的行为和编译器优化的结果。
使用throw(), 如果函数抛出异常,异常处理机制会进行栈回退,寻找(一个或多个)catch语句。
此时,检测catch可以捕捉的类型,如果没有匹配的类型,std::unexpected()会被调用。
但是std::unexpected()本身也可能抛出异常。
如果std::unexpected()抛出的异常对于当前的异常规格是有效的,
异常传递和栈回退会像以前那样继续进行。
这意味着,如果使用throw, 编译器几乎没有机会做优化。
事实上,编译器甚至会让代码变得更臃肿、庞大:
- 栈必须被保存在回退表中;
- 所有对象的析构函数必须被正确的调用(按照对象构建相反的顺序析构对象);
- 编译器可能引入新的传播栅栏(propagation barriers)、引入新的异常表入口,使得异常处理的代码变得更庞大;
- 内联函数的异常规格(exception specification)可能无效的。
当使用noexcept时,std::teminate()函数会被立即调用,而不是调用std::unexpected();
因此,在异常处理的过程中,编译器不会回退栈,这为编译器的优化提供了更大的空间。
简而言之,如果你知道你的函数绝对不会抛出任何异常,应该使用noexcept, 而不是throw().
仿函数 functor
仿函数(functor)又称为函数对象(function object),是一个能行使函数功能的类。仿函数的语法几乎和我们普通的函数调用一样,不过作为仿函数的类,都必须重载operator()运算符
1 | class Func |
2 | { |
3 | public: |
4 | void operator() (const string& str) const { |
5 | cout<<str<<endl; |
6 | } |
7 | } |
8 | |
9 | // this is a functor |
10 | struct add_x |
11 | { |
12 | add_x(int x) : x(x) {} |
13 | int operator()(int y) { return x + y; } |
14 | private: |
15 | int x; |
16 | }; |
17 | |
18 | // usage: |
19 | add_x add42(42); // create an instance of the functor class |
20 | int i = add42(8); // and "call" it |
21 | assert(i == 50); // and it added 42 to its argument |
22 | std::vector<int> in; // assume this contains a bunch of values) |
23 | std::vector<int> out; |
24 | // Pass a functor to std::transform, which calls the functor on every element |
25 | // in the input sequence, and stores the result to the output sequence |
26 | std::transform(in.begin(), in.end(), out.begin(), add_x(1)); |
27 | assert(out[i] == in[i] + 1); // for all i |
仿函数的优点
- 迭代和计算逻辑分离
使用仿函数可以使迭代和计算分离开来。因而你的functor可以应用于不同场合,在STL的算法中就大量使用了functor,下面是STL中for_each中使用functor的示例
1 | struct sum |
2 | { |
3 | sum(int * t):total(t){}; |
4 | int * total; |
5 | void operator()(int element) |
6 | { |
7 | *total+=element; |
8 | } |
9 | }; |
10 | int main() |
11 | { |
12 | int total = 0; |
13 | sum s(&total); |
14 | int arr[] = {0, 1, 2, 3, 4, 5}; |
15 | std::for_each(arr, arr+6, s); |
16 | cout << total << endl; // prints total = 15; |
17 | } |
- 参数可设置
可以很容易通过给仿函数(functor)设置参数,来实现原本函数指针才能实现的功能
1 | class CalculateAverageOfPowers |
2 | { |
3 | public: |
4 | CalculateAverageOfPowers(float p) : acc(0), n(0), p(p) {} |
5 | void operator() (float x) { acc += pow(x, p); n++; } |
6 | float getAverage() const { return acc / n; } |
7 | private: |
8 | float acc; |
9 | int n; |
10 | float p; |
11 | }; |
12 | //这个仿函数的功能是求给定值平方或立方运算的平均值。只需要这样来声明一个对象即可: |
13 | CalculateAverageOfPowers my_cal(2); |
- 有状态
与普通函数另一个区别是仿函数(functor)是有状态的,所以可以进行诸如下面这种操作
1 | CalculateAverage avg; |
2 | avg = std::for_each(dataA.begin(), dataA.end(), avg); |
3 | avg = std::for_each(dataB.begin(), dataB.end(), avg); |
4 | avg = std::for_each(dataC.begin(), dataC.end(), avg); |
- 性能
前例中std::transform(in.begin(), in.end(), out.begin(), add_x(1));
编译器可以准确知道std::transform需要调用哪个函数(add_x::operator)。这意味着它可以内联这个函数调用。而如果使用函数指针,编译器不能直接确定指针指向的函数,而这必须在程序运行时才能得到并调用。
一个例子就是比较std::sort 和qsort ,STL的版本一般要快5-10倍。
总结:前述3点都可以使用传统的函数和指针实现,但是用仿函数(functor)可以让这种实现变的更加简单
仿函数 VS 指针函数
假设有一个vector<string>,你的任务是统计长度小于5的string的个数,如果使用count_if函数
1 | bool LengthIsLessThanFive(const string& str) { |
2 | return str.length() < 5; |
3 | } |
4 | int res = count_if(vec.begin(), vec.end(), LengthIsLessThanFive); |
其中count_if函数的第三个参数是一个函数指针,返回一个bool类型的值。一般的,如果需要将特定的阈值长度也传入的话
1 | bool LenthIsLessThan(const string& str, int len) { |
2 | return str.length()<len; |
3 | } |
这个函数看起来比前面一个版本更具有一般性,但是他不能满足count_if函数的参数要求:
count_if要求的是unary function(仅带有一个参数)作为它的最后一个参数。
所以问题来了,怎么样找到以上两个函数的一个折中的解决方案呢?
这个问题其实可以归结于一个data flow的问题,要设计这样一个函数,使其能够access这个特定的length值,回顾我们已有的知识,有三种解决方案可以考虑:
- 函数的局部变量
局部变量不能在函数调用中传递,而且caller无法访问。 - 函数的参数
多个参数不适用于count_if - 全局变量
我们可以将长度阈值设置成一个全局变量
1 | int maxLength; |
2 | bool LengthIsLessThan(const string& str) { |
3 | return str.length() < maxLength; |
4 | } |
5 | int res = count_if(vec.begiin(), vec.end(), LengthIsLessThan); |
这段代码看似很不错,实则不符合规范,尤其是不优雅
1. 容易出错
必须先初始化maxLength的值,才能继续接下来的工作,如果忘了,则可能无法得到正确答案。
此外,变量maxLength和函数LengthIsLessThan之间是没有必然联系的,编译器无法确定在调用该函数前是否将变量初始化。
2. 不可扩展
每遇到一个类似的问题就新建一个全局变量,很容易引起命名空间污染(namespace polution)的问题;当范围域内有多个变量时,我们用到的可能不是我们想要的那个。
3. 应该尽可能减少使用全局变量
我们的初衷是想设计一个unary function,使其能做binary function的工作,这看起来并不容易,但是仿函数能解决这个问题。
仿函数其实是上述解决方案中的第四种方案:成员变量。
成员函数可以很自然的访问成员变量:
1 | class ShorterThan { |
2 | public: |
3 | explicit ShorterThan(int maxLength) : length(maxLength) {} |
4 | bool operator() (const string& str) const { |
5 | return str.length() < length; |
6 | } |
7 | private: |
8 | const int length; |
9 | }; |
10 | |
11 | count_if(myVector.begin(), myVector.end(), ShorterThan(length));//直接调用即可 |
仿函数 std::bind 实现闭包
std::bind ,仿函数functor 都可以用于实现闭包功能:
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | class MyFunctor |
11 | { |
12 | public: |
13 | MyFunctor(int temp): round(temp) {} |
14 | int operator()(int temp) {return temp + round; } |
15 | private: |
16 | int round; |
17 | }; |
18 | |
19 | |
20 | void mytest() |
21 | { |
22 | int round = 2; |
23 | MyFunctor f(round); |
24 | std::cout << "result: " << f(1) << std::endl; // operator()(int temp) |
25 | |
26 | return; |
27 | } |
28 | |
29 | int main() |
30 | { |
31 | mytest(); |
32 | |
33 | system("pause"); |
34 | return 0; |
35 | } |
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | void func(int x, int y) |
9 | { |
10 | std::cout << x << " " << y << std::endl; |
11 | } |
12 | |
13 | void mytest() |
14 | { |
15 | std::bind(func, 1, 2)(); |
16 | std::bind(func, std::placeholders::_1, 2)(1); |
17 | func(1, 2); |
18 | |
19 | // std::placeholders 表示的是占位符 |
20 | // std::placeholders::_1是一个占位符,代表这个位置将在函数调用时,被传入的第一个参数所替代。 |
21 | std::bind(func, 2, std::placeholders::_1)(1); |
22 | std::bind(func, 2, std::placeholders::_2)(1, 2); |
23 | std::bind(func, std::placeholders::_1, std::placeholders::_2)(1, 2); |
24 | std::bind(func, std::placeholders::_3, std::placeholders::_2)(1, 2, 3); |
25 | |
26 | //std::bind(func, 2, std::placeholders::_2)(1); // err, 调用时没有第二个参数 |
27 | |
28 | return; |
29 | } |
30 | |
31 | int main() |
32 | { |
33 | mytest(); |
34 | |
35 | system("pause"); |
36 | return 0; |
37 | } |
1 | |
2 | |
3 | |
4 | |
5 | |
6 | |
7 | |
8 | |
9 | |
10 | |
11 | class Test |
12 | { |
13 | public: |
14 | int i; // 非静态成员变量 |
15 | |
16 | void func(int x, int y) |
17 | { // 非静态成员函数 |
18 | std::cout << x << " " << y << std::endl; |
19 | } |
20 | }; |
21 | |
22 | void mytest() |
23 | { |
24 | Test obj; // 创建对象 |
25 | // 绑定非静态成员函数 |
26 | std::function<void(int, int)> f1 = std::bind(&Test::func, &obj, std::placeholders::_1, std::placeholders::_2); |
27 | f1(1, 2); // 输出: 1 2 |
28 | |
29 | obj.i = 10; |
30 | // 绑定非静态成员变量 |
31 | std::function<int &()> f2 = std::bind(&Test::i, &obj); |
32 | f2() = 123; // obj.i = 123; |
33 | std::cout << "obj.i: " << obj.i << std::endl; |
34 | |
35 | return; |
36 | } |
37 | |
38 | int main() |
39 | { |
40 | mytest(); |
41 | |
42 | system("pause"); |
43 | return 0; |
44 | } |
自定义字面量 user-defined literals
c++11支持为内置类型提供新的自定义字面量的形式,比如
1 | “Hi!”s // std::string |
2 | 1.2i // imaginary of Complex |
3 | 10110000b // binary |
4 | 10s // 10 seconds |
5 | 100.0km // kilometers |
6 | 12345678901234567890123456789x // extentend-precision |
这种形式是通过重载operator “”(双引号)后缀运算符实现的(称为literal operator,字面量运算符)。
1 | string operator""s(const char * sz, size_t n) |
2 | { |
3 | return string{sz, n}; |
4 | } |
5 | |
6 | constexpr complex<double> operator""i(double d) |
7 | { |
8 | return {0.0, d}; |
9 | } |
10 | |
11 | auto str = "test literal"s; |
12 | auto cp = 1.6i; |
这种形式的后缀重载可以使用任意标准未规定的后缀,但是不能重载或重定义已经使用的后缀形式,比如前面提到的d、u、f、l等后缀。operator""支持四种格式的重载:
-
整型字面量
重载literal运算符时使用unsigned long long、const char *、或者模板literal运算符,比如:123m,1234567890123456789x。 -
浮点型字面量
重载literal运算符时使用long double、const char *、或者模板literal运算符,比如:10.0s, 4567.891234567x。 -
字符串字面量
重载literal运算符时使用(const char*, size_t)参数,比如:"string"s, “Foobar”_path。 -
字符
重载literal运算符时使用char, wchar_t, char16_t, char32_t参数,比如: ‘f’_runic, u’BEEF’_w。
注意c++标准规定保留所有非下划线开头的字面量后缀形式,重载literal运算符时建议使用下划线开头。
如果使用了非下划线开头的literal运算符重载形式,在GCC编译器中也会有警告信息。
c11中提供literal运算符的重载形式,给字面常量的处理带来很大的便利性和可定制化处理,比如可以在c中支持任意进制的数据输入、支持大数处理(不用通过先保存为字符串,然后预处理的机制)等。
显式类型转换运算符 explicit conversion operators
C中,有时可以将构造函数用作自动类型转换函数。但这种自动特性并非总是合乎要求的,有时会导致意外的类型转换。因此C11新增了关键字explicit,用于关闭这种自动特性。
即被explicit关键字修饰的类构造函数,不能进行自动地隐式类型转换,只能显式地进行类型转换。
注意:只有一个参数的构造函数,或者构造函数有n个参数,但有n-1个参数提供了默认值,这样的情况才能进行隐式类型转换。
1 | /* 示例代码1 */ |
2 | class Demo |
3 | { |
4 | public: |
5 | Demo(); // 构造函数1 |
6 | Demo(double a); // 示例代码2 |
7 | //explicit Demo(double a) |
8 | Demo(int a,double b); // 示例代码3 |
9 | Demo(int a,int b=10,double c=1.6); // 示例代码4 |
10 | ~Demo(); |
11 | void Func(void); |
12 | |
13 | private: |
14 | int value1; |
15 | int value2; |
16 | }; |
- 构造函数1没有参数,无法进行类型转换!
- 构造函数2有一个参数,可以进行类型转换
如:Demo test; test = 12.2;这样的调用就相当于把12.2隐式转换为Demo类型。 - 构造函数3有两个参数,且无默认值,故无法使用类型转换!
- 构造函数4有3个参数,其中两个参数有默认值,故可以进行隐式转换
如:Demo test;test = 10; - 如果使用了explicit关键字,则无法进行隐式转换。
即:Demo test;test = 12.2;是无效的!但是我们可以进行显示类型转换,如:
1 | Demo test; |
2 | test = Demo(12.2); |
3 | test = (Demo)12.2; |
扩展阅读:
constexpr
C++11 引入 constexpr 生成常量表达式。
常量表达式主要是允许一些计算发生在编译时,即发生在代码编译而不是运行的时候。这是很大的优化:假如有些事情可以在编译时做,它将只做一次,而不是每次程序运行时。需要计算一个编译时已知的常量,比如特定值的sine或cosin?确实你亦可以使用库函数sin或cos,但那样你必须花费运行时的开销。使用constexpr,你可以创建一个编译时的函数,它将为你计算出你需要的数值。用户的电脑将不需要做这些工作。
为了使函数获取编译时计算的能力,你必须指定constexpr关键字到这个函数。
1 | constexpr int multiply (int x, int y) |
2 | { |
3 | return x * y; |
4 | } |
5 | |
6 | // 将在编译时计算 |
7 | const int val = multiply( 10, 10 ); |
constexpr允许函数被应用在以前调用宏的所有场合。例如,你想要一个计算数组size的函数,size是10的倍数。如果不用constexpr,你需要创建一个宏或者使用模板,因为你不能用函数的返回值去声明数组的大小。但是用constexpr,你就可以调用一个constexpr函数去声明一个数组。
1 | constexpr int getDefaultArraySize (int multiplier) |
2 | { |
3 | return 10 * multiplier; |
4 | } |
5 | |
6 | int my_array[ getDefaultArraySize( 3 ) ]; |
constexpr 实现字符串 switch
- 定义一个hash函数,计算出字符串的hash值,将字符串转换为1个整数。
- 利用c++11自定义文字常量的语法,定义一个constexpr函数,switch的case标签处调用constexpr函数。
1 | typedef std::uint64_t hash_t; |
2 | |
3 | constexpr hash_t prime = 0x100000001B3ull; |
4 | constexpr hash_t basis = 0xCBF29CE484222325ull; |
5 | |
6 | hash_t hash_(char const* str) |
7 | { |
8 | hash_t ret{basis}; |
9 | |
10 | while(*str) |
11 | { |
12 | ret ^= *str; |
13 | ret *= prime; |
14 | str++; |
15 | } |
16 | |
17 | return ret; |
18 | } |
19 | |
20 | //利用递归得到了与上面hash_函数得到的同样值 |
21 | //用constexpr声明了函数,因此编译器可以在编译期得出一个字符串的hash值 |
22 | constexpr hash_t hash_compile_time(char const* str, hash_t last_value = basis) |
23 | { |
24 | return *str ? hash_compile_time(str+1, (*str ^ last_value) * prime) : last_value; |
25 | } |
26 | |
27 | /** |
28 | ** 编译器就可以得到的整型常量,自然可以放到switch的case标签处了 |
29 | ** hash_compile_time("first")是编译器计算出来的一个常量,因此可以用作case标签; |
30 | ** 而且如果出现了hash值冲突,编译器回给出错误提示。 |
31 | **/ |
32 | void simple_switch2(char const* str) |
33 | { |
34 | using namespace std; |
35 | switch(hash_(str)) |
36 | { |
37 | case hash_compile_time("first"): |
38 | cout << "1st one" << endl; |
39 | break; |
40 | case hash_compile_time("second"): |
41 | cout << "2nd one" << endl; |
42 | break; |
43 | case hash_compile_time("third"): |
44 | cout << "3rd one" << endl; |
45 | break; |
46 | default: |
47 | cout << "Default..." << endl; |
48 | } |
49 | } |
50 | |
51 | //利用自定义文字常量,重载一个operator |
52 | constexpr unsigned long long operator "" _hash(char const* p, size_t) |
53 | { |
54 | return hash_compile_time(p); |
55 | } |
56 | |
57 | //用“_hash”作为自定义文字常量的后缀,编译器调用我们重载的operator |
58 | void simple_switch(char const* str) |
59 | { |
60 | using namespace std; |
61 | switch(hash_(str)) |
62 | { |
63 | case "first"_hash: |
64 | cout << "1st one" << endl; |
65 | break; |
66 | case "second"_hash: |
67 | cout << "2nd one" << endl; |
68 | break; |
69 | case "third"_hash: |
70 | cout << "3rd one" << endl; |
71 | break; |
72 | default: |
73 | cout << "Default..." << endl; |
74 | } |
75 | } |
default deleted
C++ 的类有四个特殊成员函数,它们分别是:
- 默认构造函数
- 析构函数
- 拷贝构造函数
- 拷贝赋值运算符。
这些类的特殊成员函数负责创建、初始化、销毁,或者拷贝类的对象。
如果程序员没有显式地为一个类定义某个特殊成员函数,而又需要用到该特殊成员函数时,则编译器会隐式的为这个类生成一个默认的特殊成员函数。但是,如果程序员为类显式的自定义了非默认构造函数,编译器将不再会为它隐式的生成默认构造函数。
手动编写的特殊成员函数的代码执行效率比编译器自动生成的特殊成员函数低。
default
C++11 标准引入:defaulted 函数。程序员只需在函数声明后加上__“=default;”__,就可将该函数声明为 defaulted 函数,编译器将为显式声明的 defaulted 函数自动生成函数体。
- Defaulted 函数特性仅适用于类的__特殊成员函数__,且该特殊成员函数__没有默认参数__。
- Defaulted 函数既可以在类体里(inline)定义,也可以在类体外(out-of-line)定义。
1 | class X{ |
2 | public: |
3 | X() = default; //Inline defaulted 默认构造函数 |
4 | X(const X&); |
5 | X& operator = (const X&); |
6 | ~X() = default; //Inline defaulted 析构函数 |
7 | }; |
8 | |
9 | X::X(const X&) = default; //Out-of-line defaulted 拷贝构造函数 |
10 | X& X::operator = (const X&) = default; //Out-of-line defaulted 拷贝赋值操作符 |
deleted
C++11 标准引入:deleted 函数。程序员只需在函数声明后加上__“=delete;”__,就可将该函数禁用。
我们可以将类 X 的拷贝构造函数以及拷贝赋值操作符声明为 deleted 函数,就可以禁止类 X 对象之间的拷贝和赋值。
1 | class X{ |
2 | public: |
3 | X(); |
4 | X(const X&) = delete; // 声明拷贝构造函数为 deleted 函数 |
5 | X& operator = (const X &) = delete; // 声明拷贝赋值操作符为 deleted 函数 |
6 | }; |
7 | |
8 | int main(){ |
9 | X x1; |
10 | X x2=x1; // 错误,拷贝构造函数被禁用 |
11 | X x3; |
12 | x3=x1; // 错误,拷贝赋值操作符被禁用 |
13 | } |
注意:
- defaulted 函数特性规定了只有类的特殊成员函数才能被声明为 defaulted 函数
- deleted 函数特性没有此限制。类的成员函数,非成员函数,即普通函数也可以被声明为 deleted 函数
- deleted 函数必须在函数第一次声明的时候将其声明,否则编译器会报错。
即对类的成员函数而言,deleted 函数必须在类体里(inline)定义,不能在类体外(out-of-line)定义
Deleted 函数特性还可用于禁用类的某些转换构造函数,从而避免不期望的类型转换。在清单 12 中,假设类 X 只支持参数为双精度浮点数 double 类型的转换构造函数,而不支持参数为整数 int 类型的转换构造函数,则可以将参数为 int 类型的转换构造函数声明为 deleted 函数。
1 | |
2 | using namespace std; |
3 | |
4 | class X |
5 | { |
6 | public: |
7 | X(int) = delete; |
8 | X(double); |
9 | X() = default; |
10 | |
11 | int add(int a, int b) = delete; |
12 | double add(double a, double b) { |
13 | return a + b; |
14 | } |
15 | |
16 | void show() = delete; |
17 | |
18 | void *operator new(size_t) = delete; |
19 | void *operator new[](size_t) = delete; |
20 | }; |
21 | |
22 | int main() |
23 | { |
24 | //X *pa = new X(1); //错误,操作符被禁用 |
25 | //X *pb = new X[10]; //错误,操作符被禁用 |
26 | X x; |
27 | //x.add(1, 4); //错误,已被禁止 |
28 | x.add(1.0, 4.0); |
29 | |
30 | return 0; |
31 | } |
值得一提的是,在上述示例中,虽然 add(int, int)函数被禁用了,但是禁用的仅是函数的定义,即该函数不能被调用。但是函数标示符 add 仍是有效的,在名字查找和函数重载解析时仍会查找到该函数标示符。
如果编译器在解析重载函数时,解析结果为 deleted 函数,则会出现编译错误。
重载 Override
公有继承
公有继承包含两部分:
- “函数接口” (interface)
- “函数实现” (implementation)
如 Shape 类中,三个成员函数,表示三种继承方式:
1 | class Shape { |
2 | public: |
3 | virtual void Draw() const = 0; // 1) 纯虚函数 |
4 | virtual void Error(const string& msg); // 2) 普通虚函数 |
5 | int ObjectID() const; // 3) 非虚函数 |
6 | }; |
7 | |
8 | class Rectangle: public Shape { ... }; |
9 | class Ellipse: public Shape { ... }; |
纯虚函数 (pure virtual)
纯虚函数,继承的是基类中,成员函数的接口,且要在派生类中,重写成员函数的实现
1 | Shape *ps1 = new Rectangle; |
2 | ps1->Draw(); // calls Rectangle::Draw |
3 | |
4 | Shape *ps2 = new Ellipse; |
5 | ps2->Draw(); // calls Ellipse::Draw |
调用基类的 Draw(),须加 类作用域操作符 ::
1 | ps1->Shape::Draw(); // calls Shape::draw |
普通虚函数
普通虚函数,会在基类中,定义一个缺省的实现 (default implementation),表示继承的是基类成员函数接口和缺省实现,由派生类选择是否重写该函数。
实际上,允许普通虚函数 同时继承接口和缺省实现是危险的。 如下, ModelA 和 ModelB 是 Airplane 的两种飞机类型,且二者的飞行方式完全相同
1 | class Airplane { |
2 | public: |
3 | virtual void Fly(const string& destination); |
4 | }; |
5 | class ModelA: public Airplane { ... }; |
6 | class ModelB: public Airplane { ... }; |
这是典型的面向对象设计,两个类共享一个特性 – Fly,则 Fly 可在基类中实现,并由两个派生类继承之
现增加另一个飞机型号 ModelC,其飞行方式与 ModelA,ModelB 不相同,如果不小心忘记在 ModelC 中重写新的 Fly 函数
1 | class ModelC: public Airplane { |
2 | ... // no fly function is declared |
3 | }; |
则调用 ModelC 中的 fly 函数,就是调用 Airplane::Fly,但是 ModelC 的飞行方式和缺省的并不相同
1 | Airplane *pa = new ModelC; |
2 | pa->Fly(Qingdao); // calls Airplane::fly! |
即前面所说的,普通虚函数同时继承接口和缺省实现是危险的,最好是基类中实现缺省行为 (behavior),但只有在派生类要求时才提供该缺省行为。
纯虚函数 + 缺省实现
因为是纯虚函数,所以只有接口被继承,其缺省的实现不会被继承。派生类要想使用该缺省的实现,必须显式的调用。
1 | class Airplane { |
2 | public: |
3 | virtual void Fly(const string& destination) = 0; |
4 | }; |
5 | |
6 | void Airplane::Fly(const string& destination) |
7 | { |
8 | // a pure virtual function default code for flying an airplane to the given destination |
9 | } |
10 | |
11 | class ModelA: public Airplane { |
12 | public: |
13 | virtual void Fly(const string& destination) { Airplane::Fly(destination); } |
14 | }; |
这样在派生类 ModelC 中,即使一不小心忘记重写 Fly 函数,也不会调用 Airplane 的缺省实现
1 | class ModelC: public Airplane { |
2 | public: |
3 | virtual void Fly(const string& destination); |
4 | }; |
5 | |
6 | void ModelC::Fly(const string& destination) |
7 | { |
8 | // code for flying a ModelC airplane to the given destination |
9 | } |
Override
可以看到,上面问题的关键就在于,一不小心在派生类 ModelC 中忘记重写 fly 函数,C++11 中使用关键字 override,可以避免这样的“一不小心”
非虚函数
非虚成员函数没有 virtual 关键字,表示派生类不但继承了接口,而且继承了一个强制实现 (mandatory implementation)
既然继承了一个强制的实现,则在派生类中,无须重新定义 (redefine) 继承自基类的成员函数,如下使用指针调用 ObjectID 函数,则都是调用的 Shape::ObjectID()
1 | Rectangel rc; // rc is an object of type Rectangle |
2 | |
3 | Shape *pB = &rc; // get pointer to rc |
4 | pB->ObjectID(); // call ObjectID() through pointer |
5 | |
6 | Rectangle *pD = &rc; // get pointer to rc |
7 | pD->ObjectID(); // call ObjectID() through pointer |
如果在派生类中重新定义了继承自基类的成员函数 ObjectID 呢?
1 | class Rectangel : public Shape { |
2 | public: |
3 | int ObjectID() const; // hides Shape::ObjectID |
4 | }; |
5 | |
6 | pB->ObjectID(); // calls Shape::ObjectID() |
7 | pD->ObjectID(); // calls Rectagle::ObjectID() |
此时,派生类中重新定义的成员函数会 “隐藏” (hide) 继承自基类的成员函数
这是因为非虚函数是 “静态绑定” 的,pB 被声明的是 Shape* 类型的指针,则通过 pB 调用的非虚函数都是基类中的,既使 pB 指向的是派生类
与“静态绑定”相对的是虚函数的“动态绑定”,即无论 pB 被声明为 Shape* 还是 Rectangle* 类型,其调用的虚函数取决于 pB 实际指向的对象类型。
Override
以重写虚函数时,容易犯的四个错误为例,详细阐述
1 | class Base { |
2 | public: |
3 | virtual void mf1() const; |
4 | virtual void mf2(int x); |
5 | virtual void mf3() &; |
6 | void mf4() const; // is not declared virtual in Base |
7 | }; |
8 | |
9 | class Derived: public Base { |
10 | public: |
11 | virtual void mf1(); // declared const in Base, but not in Derived. |
12 | virtual void mf2(unsigned int x); // takes an int in Base, but an unsigned int in Derived |
13 | virtual void mf3() &&; // is lvalue-qualified in Base, but rvalue-qualified in Derived. |
14 | void mf4() const; |
15 | }; |
在派生类中,重写 (override) 继承自基类成员函数的实现 (implementation) 时,要满足如下条件:
- 虚:基类中,成员函数声明为虚拟的 (virtual)
- 容:基类和派生类中,成员函数的返回类型和异常规格 (exception specification) 必须兼容
- 同:基类和派生类中,成员函数名、形参类型、常量属性 (constness) 和 引用限定符 (reference qualifier) 必须完全相同
如此多的限制条件,导致了虚函数重写如上述代码,极容易因为一个不小心而出错。
C++11 中的 override 关键字,可以显式的在派生类中声明,哪些成员函数需要被重写,如果没被重写,则编译器会报错。
1 | class Derived: public Base { |
2 | public: |
3 | virtual void mf1() override; |
4 | virtual void mf2(unsigned int x) override; |
5 | virtual void mf3() && override; |
6 | virtual void mf4() const override; |
7 | }; |
即使不小心漏写了虚函数重写的某个苛刻条件,也可以通过编译器的报错,快速改正错误。
1 | class Derived: public Base { |
2 | public: |
3 | virtual void mf1() const override; // adding "virtual" is OK, but not necessary |
4 | virtual void mf2(int x) override; |
5 | void mf3() & override; |
6 | void mf4() const override; |
7 | }; |
小结
- 公有继承
- 纯虚函数 => 继承的是:接口 (interface)
- 普通虚函数 => 继承的是:接口 + 缺省实现 (default implementation)
- 非虚成员函数 => 继承的是:接口 + 强制实现 (mandatory implementation)
- 不要重新定义一个继承自基类的非虚函数 (never redefine an inherited non-virtual function)
- 在声明需要重写的函数后,加关键字 override
类型推导 auto、decltype
auto
c11之前,auto、register作为存储类型的指示符存在,一个变量没有声明为 register 变量,将自动被视为一个 auto 变量。c11标准中 register 被弃用,auto 语义重定义。
使用 auto 进行类型推导的一个最为常见而且显著的例子就是迭代器。
1 | //without auto |
2 | for (vector<int>::const_iterator itr = vec.cbegin(); itr != vec.cend(); ++ itr) |
3 | |
4 | // 由于 cbegin() 将返回 vector<int>::const_iterator |
5 | // 所以 itr 也应该是 vector<int>::const_iterator 类型 |
6 | for(auto itr = vec.cbegin(); itr != vec.cend(); ++itr); |
auto 不能用于函数传参,因此下面的做法是无法通过编译的(考虑重载的问题,我们应该使用模板)
1 | int add(auto x, auto y); |
auto 不能用于推导数组类型
decltype
decltype 关键字是为了解决 auto 关键字只能对变量进行类型推导的缺陷而出现的。它的用法和 sizeof 很相似。
1 | decltype(expression) |
2 | |
3 | auto x = 1; |
4 | auto y = 2; |
5 | |
6 | //编译器分析表达式并得到它的类型,却不实际计算表达式的值。 |
7 | decltype(x+y) z; |
拖尾返回类型、auto 与 decltype 配合
auto 推导函数的返回类型。考虑这样一个例子加法函数的例子。
1 | //before c++11 |
2 | template<typename R, typename T, typename U> |
3 | R add(T x, U y) { |
4 | return x+y |
5 | } |
在使用这个模板函数的时候,必须明确指出返回类型。但事实上我们并不知道 add() 这个函数会做什么样的操作,获得一个什么样的返回类型
C++11 中这个问题得到解决。但不是通过下面这种方式
1 | decltype(x+y) add(T x, U y); |
这样的写法并不能通过编译。这是因为在编译器读到 decltype(x+y) 时,x 和 y 尚未被定义。为了解决这个问题,C++11 还引入了一个叫做__拖尾返回类型__(trailing return type),利用 auto 关键字将返回类型后置。
1 | template<typename T, typename U> |
2 | auto add(T x, U y) -> decltype(x+y) { |
3 | return x+y; |
4 | } |
C++14 甚至可以直接让普通函数具备返回值推导,因此下面的写法变得合法:
1 | template<typename T, typename U> |
2 | auto add(T x, U y) { |
3 | return x+y; |
4 | } |
区间迭代 Iterator by for
1 | std::vector<int> arr(5, 100); |
2 | for(std::vector<int>::iterator i = arr.begin(); i != arr.end(); ++i) { |
3 | std::cout << *i << std::endl; |
4 | } |
5 | //==> convert to |
6 | for(auto &i : arr) { |
7 | std::cout << i << std::endl; |
8 | } |
初始化列表 initialization list
initialization list
C++11 提供了统一的语法来初始化任意的对象
1 | struct A { |
2 | int a; |
3 | float b; |
4 | }; |
5 | |
6 | struct B { |
7 | B(int _a, float _b): a(_a), b(_b) {} |
8 | private: |
9 | int a; |
10 | float b; |
11 | }; |
12 | |
13 | A a {1, 1.1}; // 统一的初始化语法 |
14 | B b {2, 2.2}; |
C++11 初始化列表的概念也绑定到了类型上,即 std::initializer_list,允许构造函数或其他函数像参数一样使用初始化列表,这就为类对象的初始化与普通数组和 POD 的初始化方法提供了统一的方式
1 | |
2 | |
3 | class Magic { |
4 | public: |
5 | Magic(std::initializer_list<int> list) {} |
6 | }; |
7 | |
8 | Magic magic = {1,2,3,4,5}; |
9 | std::vector<int> v = {1, 2, 3, 4}; |
成员变量快速初始化
C++98支持就地声明成员变量,在类中使用 “=” 来初始化静态成员常量。
- 类中的该静态成员变量需要满足“常量性”,如果不满足静态变量常量性,则不可以进行就地声明。
- 需要满足该静态常量成员必须是:整型或者是枚举类型。
C11标准除了支持C98中的就地声明初始化方式外,还支持非静态成员变量的初始化方式有多种。即除了“初始化列表”之外,C++11还允许使用 “等号=”和 “花括号{}”来进行就地的非静态成员变量初始化操作。
1 | |
2 | using namespace std; |
3 | |
4 | class Base |
5 | { |
6 | public: |
7 | Base() = default; |
8 | Base(int _a,double _b, float _c):a(_a),b(_b),c(_c){} |
9 | Base(const Base&) = delete; |
10 | Base& operator=(const Base&) = delete; |
11 | ~Base(){} |
12 | |
13 | void DisplayMem()const{ |
14 | std::cout<<"a: "<<a<<", b: "<<b<< \ |
15 | ",c: "<<c<<std::endl; |
16 | } |
17 | private: |
18 | int a = 1; //c++11新特性,使用等号“=”初始化非静态常量的成员变量 |
19 | double b{2.0}; //c++11新特性,使用花括号“{}”初始化非静态常量的成员变量 |
20 | float c{3.0}; //c++11新特性,使用花括号“{}”初始化非静态常量的成员变量 |
21 | }; |
22 | |
23 | int main(int argc,char **argv) |
24 | { |
25 | Base b; |
26 | b.DisplayMem(); |
27 | return 0; |
28 | } |
注意区别C98中使用()初始化 和 C11 使用 {} 初始化的区别
1 | |
2 | |
3 | using namespace std; |
4 | |
5 | class Human |
6 | { |
7 | public: |
8 | Human() = default; |
9 | Human(int _a):m_a(_a){} |
10 | ~Human(){} |
11 | protected: |
12 | int m_a; |
13 | }; |
14 | |
15 | class Man |
16 | { |
17 | public: |
18 | Man() {} |
19 | ~Man(){} |
20 | public: |
21 | int f = 10; |
22 | //std::string m_msg1("lxg"); //编译报错 |
23 | std::string m_msg2 = std::string("lxg");//编译通过 |
24 | std::string m_msg3{"lxg"}; //编译通过 |
25 | Human h1 = Human(20); //编译通过 |
26 | //Human h2(20); //编译报错 |
27 | Human h3{20}; //编译通过 |
28 | }; |
29 | int main(int argc,char **argv) |
30 | { |
31 | |
32 | return 0; |
33 | } |
随机数 random
随机数由生成器和分布器结合产生
- 生成器generator:能够产生离散的等可能分布数值(需要种子,不然每次生存的随机数都一样)
- 分布器distributions: 能够把generator产生的均匀分布值映射到其他常见分布,如
1. 均匀分布uniform
2. 正态分布normal
3. 二项分布binomial
4. 泊松分布poisson- 种子:相当于外部传给随机数生成器的诱因。
如果每次传入的种子一样,则每次生成的随机数还是一样
default_random_engine
1 | //std::default_random_engine engine(); //没有设置种子,每次生存的随机数都一样 |
2 | std::default_random_engine engine(time(nullptr)); //设置了种子,每次种子都不一样 |
3 | std::uniform_int_distribution<> dis(1, 10); |
4 | for (int n = 0; n < 10; n++) |
5 | std::cout << dis(engine) << " " << std::endl; |
default_random_engine 结合uniform_int_distribution生成的随机数是闭环[begin, end]
如果嫌每次调用都要传入generator对象麻烦,可以使用std::bind,要包含头文件functional,以后就可以直接调用dice()产生复合均匀分布的随机数。
1 | //std::default_random_engine engine(); //没有设置种子,每次生存的随机数都一样 |
2 | std::default_random_engine engine(time(nullptr)); |
3 | std::uniform_int_distribution<> dis(1, 10); |
4 | |
5 | auto dice = std::bind(dis,generator); |
6 | for (int n = 0; n < 10; n++) |
7 | std::cout << dice() << " " << std::endl; |
random_device
标准库提供了一个非确定性随机数生成设备。在Linux的实现中,是读取/dev/urandom设备;Windows的实现是用rand_s(尴尬)
random_device提供()操作符,用来返回一个min()到max()之间的一个数字。如果是Linux(Unix Like或者Unix)下,都可以使用这个来产生高质量的随机数,可以理解为真随机数。
1 | |
2 | |
3 | int main() |
4 | { |
5 | std::random_device rd; |
6 | for(int n=0; n<20000; ++n) |
7 | std::cout << rd() << std::endl; |
8 | return 0; |
9 | } |
10 | |
11 | //结合:default_random_engine使用生成指定范围内的真随机数 |
12 | int main() |
13 | { |
14 | std::random_device rd; |
15 | std::default_random_engine engine(rd()); |
16 | std::uniform_int_distribution<> dis(10, 20); |
17 | auto dice = std::bind(dis, engine); |
18 | for (int n = 0; n < 10; n++) |
19 | std::cout << dice() << " " << std::endl; |
20 | } |
C++11标准把随机数抽象成随机数引擎和分布两部分 。引擎用来产生随机数,分布产生特定分布的随机数(比如平均分布,正太分布等)。
C++11标准提供三种常用的引擎:
linear_congruential_engine,mersenne_twister_engine和subtract_with_carry_engine。
第一种是线性同余算法,
第二种是梅森旋转算法,
第三种带进位的线性同余算法.
第一种是最常用的,而且速度也是非常快的; 第二种号称是最好的伪随机数生成器;第三种没用过…
随机数引擎接受一个整形参数当作种子,不提供的话,会使用默认值。推荐使用random_device来产生一个随机数当作种子。
1 | |
2 | |
3 | |
4 | int main() |
5 | { |
6 | std::random_device rd; |
7 | std::mt19937 mt(rd()); |
8 | for(int n = 0; n < 10; n++) |
9 | std::cout << mt() << std::endl; |
10 | return 0; |
11 | } |
random number distributions
C++11标准提供各种各样的分布,不过我们经常用的比较少,比如平均分布,正太分布…使用也很简单
1 | |
2 | |
3 | int main() |
4 | { |
5 | std::random_device rd; |
6 | std::mt19937 gen(rd()); |
7 | std::uniform_int_distribution<> dis(1, 6); |
8 | for(int n=0; n<10; ++n) |
9 | std::cout << dis(gen) << ' '; |
10 | std::cout << '\n'; |
11 | } |
12 | |
13 | //正太分布 |
14 | |
15 | |
16 | |
17 | |
18 | |
19 | |
20 | int main() |
21 | { |
22 | std::random_device rd; |
23 | std::mt19937 gen(rd()); |
24 | |
25 | // values near the mean are the most likely |
26 | // standard deviation affects the dispersion of generated values from the mean |
27 | std::normal_distribution<> d(5,2); |
28 | |
29 | std::map<int, int> hist; |
30 | for(int n=0; n<10000; ++n) { |
31 | ++hist[std::round(d(gen))]; |
32 | } |
33 | for(auto p : hist) { |
34 | std::cout << std::fixed << std::setprecision(1) << std::setw(2) |
35 | << p.first << ' ' << std::string(p.second/200, '*') << '\n'; |
36 | } |
37 | } |
类型特征 type traits
C++11标准中通过模板元基础库type_traits可以实现在编译期计算、查询、判断、转换和选择,增强了泛型编程的能力,也增强了程序的弹性,使得我们在编译期就能做到优化改进甚至排错,能进一步提高代码质量。
定义了一个名为is_pod的函数模板。该函数模板只是type_traits中模板类is_pod的简单包装。通过该函数,我们可以判断一个类型的数据是否为POD类型的。
1 | |
2 | template<typename T> |
3 | constexpr bool is_pod(T) { |
4 | return std::is_pod<T>::value; |
5 | } |
6 | |
7 | int main(){ |
8 | int a; |
9 | std::cout << is_pod(a) << std::endl; |
10 | } |
扩展阅读: C++111预定义Type traits。
除去判断类型的特性,type_traits 标准库中我们也可以找到is_same这样的比较两个类型是否相等的类模板,以及enable_if这样的根据bool值选择类型的类模板。
从实现上讲,这些Type Traits通常是通过模板特化的元编程手段来完成的,比如在g++ 4.8.1的type_traits 头文件中我们可以找到以下代码
1 | /// is_const |
2 | template<typename> |
3 | struct is_const |
4 | : public false_type { }; // 版本 1 |
5 | |
6 | template<typename _Tp> |
7 | struct is_const<_Tp const> |
8 | : public true_type { }; // 版本 2 |
这里的false_type和true_type则是两个helper class,其定义如下
1 | /// integral_constant |
2 | template<typename _Tp, _Tp __v> |
3 | struct integral_constant |
4 | { |
5 | static constexpr _Tp value = __v; |
6 | typedef _Tp value_type; |
7 | typedef integral_constant<_Tp, __v> type; |
8 | constexpr operator value_type() { return value; } |
9 | }; |
10 | |
11 | template<typename _Tp, _Tp __v> |
12 | constexpr _Tp integral_constant<_Tp, __v>::value; |
13 | |
14 | /// The type used as a compile-time boolean with true value. |
15 | typedef integral_constant<bool, true> true_type; |
16 | |
17 | /// The type used as a compile-time boolean with false value. |
18 | typedef integral_constant<bool, false> false_type; |
简单地说,true_type和false_type就是包含一个静态类成员value的类模板,其静态成员一个为true,一个为false。这样一来,通过特化,如果我们使用const类型作为模板is_const类型参数,则可以获得其常量静态成员value的值为true(1)。这是因为模板在实例化的时候选择了“版本2”。反过来,如果模板实例化到“版本1”,则value常量静态成员为false(0)。
1 | |
2 | |
3 | |
4 | int main(){ |
5 | int a; |
6 | const int b = 3; |
7 | std::cout << std::is_const<decltype(a)>::value << std::endl; // 1 |
8 | std::cout << std::is_const<decltype(b)>::value << std::endl; // 0 |
9 | } |
并非所有的Type Traits都能够使用上面的元编程的手段来实现。C语言设计者在实践中进行了一些考量,让部分的Type Traits实现为了intrinsic,简单地说,就是要编译器辅助来计算出其值。我们可以看看g4.8.1中POD的定义:
1 | /// is_pod |
2 | // Could use is_standard_layout && is_trivial instead of the builtin. |
3 | template<typename _Tp> |
4 | struct is_pod: public integral_constant<bool, __is_pod(_Tp)> |
5 | {}; |
这里的__is_pod就是编译器内部的intrinsic。事实上,在C11中,编译器必须辅助实现很多Type Traits的模板类,C11标准中这些Type Traits模板类如下所示:
1 | template <class T> struct is_class; |
2 | template <class T> struct is_union; |
3 | template <class T> struct is_enum; |
4 | template <class T> struct is_polymorphic; |
5 | template <class T> struct is_empty; |
6 | template <class T> struct has_trivial_constructor; |
7 | template <class T> struct has_trivial_copy; |
8 | template <class T> struct has_trivial_assign; |
9 | template <class T> struct has_trivial_destructor; |
10 | template <class T> struct has_nothrow_constructor; |
11 | template <class T> struct has_nothrow_copy; |
12 | template <class T> struct has_nothrow_assign; |
13 | template <class T> struct is_pod; |
14 | template <class T> struct is_abstract; |
总的来说,Type Traits就是通过元编程的手段,以及编译器的辅助来实现的
模板增强
外部模板
C++11之前,模板只有在使用时才会被编译器实例化。只要在每个编译单元(文件)中编译的代码中遇到了被完整定义的模板,都会实例化。这就产生了重复实例化而导致的编译时间的增加。并且,我们没有办法通知编译器不要触发模板实例化。
C++11 引入了外部模板,扩充了原来的强制编译器在特定位置实例化模板的语法,使得能够显式的告诉编译器何时进行模板的实例化。
1 | template class std::vector<bool>; // 强行实例化 |
2 | extern template class std::vector<double>; // 不在该编译文件中实例化模板 |
尖括号 >
C++11 之前,>> 一律被当做右移运算符来进行处理。但实际上我们很容易就写出了嵌套模板的代码
1 | std::vector<std::vector<int>> wow; |
这在传统C编译器下是不能够被编译的,而 C11 开始,连续的右尖括号将变得合法,并且能够顺利通过编译。
类型别名模板 using
C++11之前,typedef 可以为类型定义一个新的名称,但是却没有办法为模板定义一个新的名称。因为,模板不是类型。
1 | template< typename T, typename U, int value> |
2 | class SuckType { |
3 | public: |
4 | T a; |
5 | U b; |
6 | SuckType():a(value),b(value){} |
7 | }; |
8 | template< typename U> |
9 | typedef SuckType<std::vector<int>, U, 1> NewType; // 不合法 |
C++11 使用 using 引入了下面这种形式的写法,并且同时支持对传统 typedef 相同的功效:
1 | emplate <typename T> |
2 | using NewType = SuckType<int, T, 1>; // 合法 |
默认模板参数
我们定义一个加法函数:
1 | template<typename T, typename U> |
2 | auto add(T x, U y) -> decltype(x+y) { |
3 | return x+y |
4 | } |
要使用 add,就必须每次都指定其模板参数的类型。
在 C++11 中提供了一种便利,可以指定模板的默认参数:
1 | template<typename T = int, typename U = int> |
2 | auto add(T x, U y) -> decltype(x+y) { |
3 | return x+y; |
4 | } |
可变参数模板 Variadic Template
Variadic Functions
C99中使用宏进行可变参数编程: va_list, va_start, va_end, va_arg
1 | int printf(const char* format, ... ); |
2 | |
3 | |
4 | void PrintDoubles (int n, ...) |
5 | { |
6 | va_list vl; |
7 | va_start( vl , n ); |
8 | for ( int i=0 ; i<n ; i++) |
9 | { |
10 | double val = va_arg( vl , double ); |
11 | std::cout<< val << std::endl; |
12 | } |
13 | va_end( vl ); |
14 | } |
C++11 引入可变参数模板(Variadic Template),模板编程更容易,且运行时更少占用内存。
在C++11之前,实现函数对象(functors)或元组(tuple)工具的时候局限性非常大,往往需要不断重复编写代码实现多参数支持。有了可变参数模板,代码可以得到大量简化。
函数式
1 | template<typename... Arguments> |
2 | void SampleFunction(Arguments... parameters); |
类式
1 | template<typename... Arguments> |
2 | class SampleClass{ |
3 | ... |
4 | SampleClass(Arguments&&... parameters) : data{std::forward<T>(t)...}{ |
5 | } |
6 | ... |
7 | }; |
8 | |
9 | template<typename ...Element> class tuple; |
10 | tuple<int, string> a; // use it like this |
C++11 引入__parameter pack(参数包)__概念。
在模板参数 Element 左边出现省略号 … ,就是表示 Element 是一个模板参数包(template type parameter pack)。
在上面例子中,Element 表示是一连串任意的参数打成的一个包。
第10行中,Element 就是 int, string这个参数的合集。
不仅“类型”的模板参数(也就是typename定义的参数)可以这样做,非类型的模板参数也可以这样做。
1 | template<typename T, unsigned PrimaryDimesion, unsigned...Dimesions> |
2 | class array { /**/ }; |
3 | |
4 | array<double, 3, 3> rotation_matrix; //3x3 ratiation matrix |
C11标准中并没有提供 get_param<1>(Element)这样的内建"参数抽取函数"来访问和操作参数包。
C11标准中使用 unpack 和类似函数重载的 “模板特化” 来抽取参数,通过 “递归” 类展开。
1 | template<typename... Elements> class tuple; |
2 | template<typename Head, typename... Tail> |
3 | class tuple<Head, Tail...> : private tuple<Tail...> { |
4 | Head head; |
5 | public: |
6 | /* implementation */ |
7 | }; |
8 | template<> |
9 | class tuple<> { |
10 | /* zero-tuple implementation */ |
11 | }; |
第1行声明了一个可以对应任意参数的tuple类.
第2行到7行声明了这个类的一个部分特化,注意,这就是抽取参数的典型方法了。
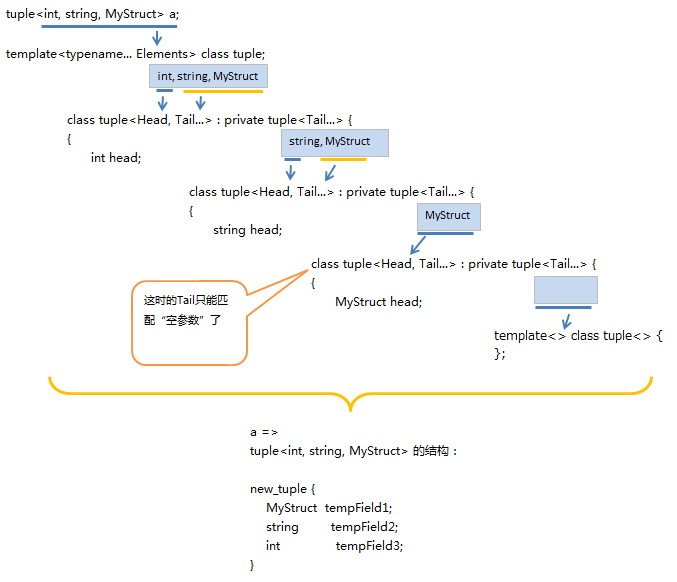
只说明一下针对 parameter pack 相对的另一个概念,模板参数后面带省略号 … 就是一个解包(unpack),会把这个参数所表示的参数列表解开后去匹配新的模板,或是进行模板展开。
C11新的标准库里,有很多个库都直接依赖于 variadic template 这个语言特性,比如,tuple,bind,function。 C11 的 FQA 和 Wikipedia 的例子都是“类型安全”的printf:
1 | void printf(const char *s) |
2 | { |
3 | while (*s) { |
4 | if (*s == '%') { |
5 | if (*(s + 1) == '%') { |
6 | ++s; |
7 | } |
8 | else { |
9 | throw std::runtime_error("invalid format string: missing arguments"); |
10 | } |
11 | } |
12 | std::cout << *s++; |
13 | } |
14 | } |
15 | |
16 | template<typename T, typename... Args> |
17 | void printf(const char *s, T value, Args... args) |
18 | { |
19 | while (*s) { |
20 | if (*s == '%') { |
21 | if (*(s + 1) == '%') { |
22 | ++s; |
23 | } |
24 | else { |
25 | std::cout << value; |
26 | // call even when *s == 0 to detect extra arguments |
27 | printf(s + 1, args...); |
28 | return; |
29 | } |
30 | } |
31 | std::cout << *s++; |
32 | } |
33 | throw std::logic_error("extra arguments provided to printf"); |
34 | } |
类继承
1 | template<typename... BaseClasses> |
2 | class SampleClass : BaseClasses... { |
3 | }; |
sizeof…运算符
sizeof…(parameter_pack) 返回参数包元素个数
扩展阅读: Variadic Templates for GCC
November 1, 2006: Version 1.5 of the variadic templates implementation in GCC is now available for download. This version introduces several bug fixes, new features, and one syntax change, including:
The syntax for determining the length of a parameter pack has changed. Instead of sizeof(Args…) we now use sizeof…(Args), which should be less confusing.
One can now expand parameter packs in base classes and initializers of those base classes, e.g.,
template
1 | struct myclass : public Mixins... { |
2 | myclass(const Mixins&... mixins) |
3 | : Mixins(mixins)... { } |
4 | }; |
One can now expand parameter packs in a throw specifier.
One can now expand parameter packs in initializer list., e.g.,
template
1 | void foo(const Values&... values) { |
2 | boost::any array[sizeof...(Values)] = { values... }; |
3 | // ... |
4 | } |
构造函数 Constructor Delegate
委托构造
C++11 引入了委托构造的概念,这使得构造函数可以在同一个类中一个构造函数调用另一个构造函数,从而达到简化代码的目的
1 | class Base { |
2 | public: |
3 | int value1; |
4 | int value2; |
5 | Base() { |
6 | value1 = 1; |
7 | } |
8 | Base(int value) : Base() { // 委托 Base() 构造函数 |
9 | value2 = 2; |
10 | } |
11 | }; |
继承构造
继承体系中,如果派生类想要使用基类的构造函数,需要在构造函数中显式声明。
假若基类拥有为数众多的不同版本的构造函数,这样,在派生类中得写很多对应的“透传”构造函数。
1 | struct A |
2 | { |
3 | A(int i) {} |
4 | A(double d,int i){} |
5 | A(float f,int i,const char* c){} |
6 | //...等等系列的构造函数版本 |
7 | }; |
8 | |
9 | struct B:A |
10 | { |
11 | B(int i):A(i){} |
12 | B(double d,int i):A(d,i){} |
13 | B(folat f,int i,const char* c):A(f,i,e){} |
14 | //...等等好多个和基类构造函数对应的构造函数 |
15 | }; |
C++11的继承构造:
1 | struct A |
2 | { |
3 | A(int i) {} |
4 | A(double d,int i){} |
5 | A(float f,int i,const char* c){} |
6 | //...等等系列的构造函数版本 |
7 | }; |
8 | struct B:A |
9 | { |
10 | using A::A; |
11 | //关于基类各构造函数的继承一句话搞定 |
12 | //...... |
13 | }; |
如果一个继承构造函数不被相关的代码使用,编译器不会为之产生真正的函数代码,这样比透传基类各种构造函数更加节省目标代码空间。
std::function 、std::bind
可调用对象
可调用对象几种定义:
- 是一个函数指针
- 一个类成员函数指针
- 可被转换成函数指针的类对象
- 是一个具有operator()成员函数的类的对象
C++11中提供了std::function和std::bind统一了可调用对象的各种操作。
1 | // 普通函数 |
2 | int add(int a, int b){return a+b;} |
3 | |
4 | // lambda表达式 |
5 | auto mod = [](int a, int b){ return a % b;} |
6 | |
7 | // 函数对象类 |
8 | struct divide{ |
9 | int operator()(int denominator, int divisor){ |
10 | return denominator/divisor; |
11 | } |
12 | }; |
上述三种可调用对象虽然类型不同,但是共享了一种调用形式:
1 | int(int ,int) |
std::function就可以将上述类型保存起来,如下:
1 | std::function<int(int ,int)> a = add; |
2 | std::function<int(int ,int)> b = mod ; |
3 | std::function<int(int ,int)> c = divide(); |
std::function
std::function 是一个可调用对象包装器,是一个类模板,可以容纳__除类成员函数指针之外__的所有可调用对象 。它可以用统一的方式处理下列可调用对象并允许保存和延迟它们的执行
- 函数
- 函数对象
- 函数指针
定义格式:std::function<函数类型>。
std::function可以取代函数指针的作用,且比普通函数指针更加的灵活和便利,因为它可以延迟函数的执行,特别适合作为回调函数使用。
std::bind
可将std::bind函数看作一个通用的函数适配器,它接受一个可调用对象,生成一个新的可调用对象来“适应”原对象的参数列表。
std::bind将可调用对象与其参数一起进行绑定,绑定后的结果可以使用std::function保存。
std::bind主要有以下两个作用:
- 将可调用对象和其参数绑定成一个防函数;
- 只绑定部分参数,减少可调用对象传入的参数。
std::bind绑定普通函数
1 | double my_divide (double x, double y) {return x/y;} |
2 | auto fn_half = std::bind (my_divide,_1,2); |
3 | std::cout << fn_half(10) << '\n'; // output 5 |
- bind的第一个参数是函数名,普通函数做实参时,会__隐式转换成函数指针__。
因此std::bind (my_divide,_1,2)等价于std::bind (&my_divide,_1,2); - _1表示占位符,位于<functional>中,_std:: placeholders::1;
std::bind绑定一个成员函数
1 | struct Foo |
2 | { |
3 | void print_sum(int n1, int n2) |
4 | { |
5 | std::cout << n1+n2 << '\n'; |
6 | } |
7 | int data = 10; |
8 | }; |
9 | int main() |
10 | { |
11 | Foo foo; |
12 | auto f = std::bind(&Foo::print_sum, &foo, 95, std::placeholders::_1); |
13 | f(5); // 100 |
14 | } |
- bind绑定类成员函数时,第一个参数表示对象的成员函数的指针,第二个参数表示对象的地址。
- 必须显示的指定&Foo::print_sum,因为编译器__不会将对象的成员函数隐式转换成函数指针__,所以必须在Foo::print_sum前添加_&_;
- 使用对象成员函数的指针时,必须要知道该指针属于哪个对象,因此第二个参数为对象的地址 &foo;
std::bind绑定一个引用参数
默认情况下,bind的那些不是占位符的参数被拷贝到bind返回的可调用对象中。但是,与lambda类似,有时对有些绑定的参数希望以引用的方式传递,或是要绑定参数的类型无法拷贝。
1 | |
2 | |
3 | |
4 | |
5 | |
6 | using namespace std::placeholders; |
7 | using namespace std; |
8 | |
9 | ostream & print(ostream &os, const string& s, char c) |
10 | { |
11 | os << s << c; |
12 | return os; |
13 | } |
14 | |
15 | int main() |
16 | { |
17 | vector<string> words{"helo", "world", "this", "is", "C++11"}; |
18 | ostringstream os; |
19 | char c = ' '; |
20 | for_each(words.begin(), words.end(), |
21 | [&os, c](const string & s){os << s << c;} ); |
22 | cout << os.str() << endl; |
23 | |
24 | ostringstream os1; |
25 | // ostream不能拷贝,若希望传递给bind一个对象, |
26 | // 而不拷贝它,就必须使用标准库提供的ref函数 |
27 | for_each(words.begin(), words.end(), |
28 | bind(print, ref(os1), _1, c)); |
29 | cout << os1.str() << endl; |
30 | } |
指向成员函数的指针
1 | |
2 | struct Foo { |
3 | int value; |
4 | void f() { std::cout << "f(" << this->value << ")\n"; } |
5 | void g() { std::cout << "g(" << this->value << ")\n"; } |
6 | }; |
7 | void apply(Foo* foo1, Foo* foo2, void (Foo::*fun)()) { |
8 | (foo1->*fun)(); // call fun on the object foo1 |
9 | (foo2->*fun)(); // call fun on the object foo2 |
10 | } |
11 | int main() { |
12 | Foo foo1{1}; |
13 | Foo foo2{2}; |
14 | apply(&foo1, &foo2, &Foo::f); |
15 | apply(&foo1, &foo2, &Foo::g); |
16 | } |
- 成员函数指针的定义:void (Foo::*fun)(),调用是传递的实参: &Foo::f;
- fun为类成员函数指针,所以调用是要通过解引用的方式获取成员函数*fun,即(foo1->*fun)();
函数指针指向的是函数而非对象。和其他指针类型一样,函数指针指向某种特定类型。
函数类型由它的返回值和参数类型决定,与函数名无关。
1 | bool length_compare(const string &, const string &); |
- 上述函数类型是:bool (const string &, const string &);
- 上述函数指针pf:bool (*pf)(const string &, const string &);
当把函数名作为一个值使用时,该函数自动的转换成指针。
1 | pf = length_compare <=> 等价于pf = &length_compare |
- 函数类型不能定义为形参,但是形参可以是指向函数的指针;
- 函数作为实参使用时,会自动的转换成函数指针;
1 | typedef bool Func(const string &, const string &) // Func是函数类型; |
2 | typedef bool (*FuncP)(const string &, const string &) // FuncP是函数指针类型; |
3 | |
4 | typedef decltype(length_compare) Func2 // Func2是函数类型; |
5 | typedef decltype(length_compare) *Func2P // Func2P是函数指针类型; |
注意decltype(length_compare)返回的是函数类型,而不是函数指针类型;
1 | using FTtype = int(int,int); //函数类型 |
2 | typedef int (*pf)(int, int); //函数指针 |
3 | |
4 | int func(int a, int b){return a+b;} |
5 | void print(int a, int b, FTtype fn){ |
6 | // 编译器将其隐式转化成函数指针 |
7 | cout << fn(a,b) << endl; |
8 | } |
9 | |
10 | int main() |
11 | { |
12 | print(1,2,func); |
13 | cout << typeid(FTtype).name() << endl; // FiiiE |
14 | cout << typeid(func).name() << endl; // FiiiE |
15 | cout << typeid(decltype(func)).name() << endl; // FiiiE |
16 | cout << typeid(pf).name() << endl; // PFiiiE |
17 | return 0; |
18 | } |
下面两个声明语句是同一个函数,因为编译器会自动的将FTtype 转换成函数指针类型。
1 | void print(int a, int b, FTtype fn); |
2 | void print(int a, int b, pf fn); |
虽然不能返回一个函数,但是能返回执行函数类型的指针。和函数参数不同,编译器不会自动地将函数返回类型当作指针类型处理,必须显示的将返回类型指定为指针。如:
1 | using F = int(int*, int); |
2 | using PF = int(*)(int*,int); |
3 | F f1(int); //错误: F是函数类型 |
4 | PF f1(int); //正确: PF是函数指针类型 |
f1也可以写出下面两种形式:
1 | int (*f1(int))(int*, int); |
2 | auto f1(int)->int(*)(int*, int); |
Lambda 表达式
Lambda 表达式,实际上就是提供了一个类似匿名函数的特性,而匿名函数则是在需要一个函数,但是又不想费力去命名一个函数的情况下去使用的。
Lambda 表达式的基本语法如下:
[ caputrue ] ( params ) opt -> ret { body; };
- capture是捕获列表;
- params是参数表;
- opt是函数选项,mutable,exception,attribute
- mutable说明lambda表达式体内的代码可以修改被捕获的变量,并且可以访问被捕获的对象的non-const方法。
- exception说明lambda表达式是否抛出异常以及何种异常。
- attribute用来声明属性。
- ret是返回值类型(拖尾返回类型)。
- body是函数体。
__捕获列表:__lambda表达式的捕获列表精细控制了lambda表达式能够访问的外部变量,以及如何访问这些变量。
- []不捕获任何变量。
- [&]捕获外部作用域中所有变量,并作为引用在函数体中使用(按引用捕获)。
- [=]捕获外部作用域中所有变量,并作为副本在函数体中使用(按值捕获)。注意__值捕获的前提是变量可以拷贝,且被捕获的变量在 lambda 表达式被创建时拷贝,而非调用时才拷贝__。如果希望lambda表达式在调用时能即时访问外部变量,我们应当使用引用方式捕获。
- [=,&foo]按值捕获外部作用域中所有变量,并按引用捕获foo变量。
- [bar]按值捕获bar变量,同时不捕获其他变量。
- [this]捕获当前类中的this指针,让lambda表达式拥有和当前类成员函数同样的访问权限。如果已经使用了&或者=,就默认添加此选项。捕获this的目的是可以在lamda中使用当前类的成员函数和成员变量。
值捕获的前提是变量可以拷贝,且被捕获的变量在 lambda 表达式被创建时拷贝,而非调用时才拷贝
捕获this的目的是可以在lamda中使用当前类的成员函数和成员变量。
1 | int a = 0; |
2 | auto f = [=] { return a; }; |
3 | |
4 | a+=1; |
5 | |
6 | cout << f() << endl; //输出0 |
7 | |
8 | int a = 0; |
9 | auto f = [&a] { return a; }; |
10 | |
11 | a+=1; |
12 | |
13 | cout << f() <<endl; //输出1 |
1 | class A |
2 | { |
3 | public: |
4 | int i_ = 0; |
5 | |
6 | void func(int x,int y){ |
7 | auto x1 = [] { return i_; }; //error,没有捕获外部变量 |
8 | auto x2 = [=] { return i_ + x + y; }; //OK |
9 | auto x3 = [&] { return i_ + x + y; }; //OK |
10 | auto x4 = [this] { return i_; }; //OK |
11 | auto x5 = [this] { return i_ + x + y; }; //error,没有捕获x,y |
12 | auto x6 = [this, x, y] { return i_ + x + y; }; //OK |
13 | auto x7 = [this] { return i_++; }; //OK |
14 | }; |
15 | |
16 | int a=0 , b=1; |
17 | auto f1 = [] { return a; }; //error,没有捕获外部变量 |
18 | auto f2 = [&] { return a++ }; //OK |
19 | auto f3 = [=] { return a; }; //OK |
20 | auto f4 = [=] {return a++; }; //error,a是以复制方式捕获的,无法修改 |
21 | auto f5 = [a] { return a+b; }; //error,没有捕获变量b |
22 | auto f6 = [a, &b] { return a + (b++); }; //OK |
23 | auto f7 = [=, &b] { return a + (b++); }; //OK |
注意f4,虽然按值捕获的变量值均复制一份存储在lambda表达式变量中,修改他们也并不会真正影响到外部,但我们却仍然无法修改它们。如果希望去__修改按值捕获的外部变量,需要显示指明lambda表达式为mutable__。被mutable修饰的lambda表达式就算没有参数也要写明参数列表。
原因:lambda表达式可以说是就地定义仿函数闭包的“语法糖”。它的捕获列表捕获住的任何外部变量,最终会变为闭包类型的成员变量。按照C++标准,lambda表达式的operator()默认是const的,一个const成员函数是无法修改成员变量的值的。mutable的作用,就在于取消operator()的const。
1 | int a = 0; |
2 | auto f1 = [=] { return a++; }; //error |
3 | auto f2 = [=] () mutable { return a++; }; //OK |
lambda表达式的大致原理:每当你定义一个lambda表达式后,编译器会自动生成一个匿名类(这个类重载了()运算符),我们称为__闭包类型(closure type)。那么在运行时,这个lambda表达式就会返回一个匿名的闭包实例,是一个__右值。所以,我们上面的lambda表达式的结果就是一个个闭包。对于复制传值捕捉方式,类中会相应添加对应类型的非静态数据成员。在运行时,会用复制的值初始化这些成员变量,从而生成闭包。对于引用捕获方式,无论是否标记mutable,都可以在lambda表达式中修改捕获的值。至于闭包类中是否有对应成员,C++标准中给出的答案是:不清楚的,与具体实现有关。
lambda表达式是不能被赋值的
1 | auto a = [] { cout << "A" << endl; }; |
2 | auto b = [] { cout << "B" << endl; }; |
3 | |
4 | a = b; // 非法,lambda无法赋值 |
5 | auto c = a; // 合法,生成一个副本 |
闭包类型禁用了赋值操作符,但是没有禁用复制构造函数,所以你仍然可以__用一个lambda表达式去初始化另外一个lambda表达式而产生副本__。
在多种捕获方式中,最好不要使用[=]和[&]默认捕获所有变量。
默认引用捕获所有变量,你有很大可能会出现__悬挂引用(Dangling references)__,因为引用捕获不会延长引用的变量的生命周期:
1 | std::function<int(int)> add_x(int x) |
2 | { |
3 | return [&](int a) { return x + a; }; |
4 | } |
上面函数返回了一个lambda表达式,参数x仅是一个临时变量,函数add_x调用后就被销毁了,但是返回的lambda表达式却引用了该变量,当调用这个表达式时,引用的是一个垃圾值,会产生没有意义的结果。上面这种情况,使用默认传值方式可以避免悬挂引用问题。
但是采用默认值捕获所有变量仍然有风险,看下面的例子:
1 | class Filter |
2 | { |
3 | public: |
4 | Filter(int divisorVal): |
5 | divisor{divisorVal} |
6 | {} |
7 | |
8 | std::function<bool(int)> getFilter() |
9 | { |
10 | return [=](int value) {return value % divisor == 0; }; |
11 | } |
12 | |
13 | private: |
14 | int divisor; |
15 | }; |
这个类中有一个成员方法,可以返回一个lambda表达式,这个表达式使用了类的数据成员divisor。而且采用默认值方式捕捉所有变量。你可能认为这个lambda表达式也捕捉了divisor的一份副本,但是实际上并没有。因为数据成员divisor对lambda表达式并不可见,你可以用下面的代码验证:
1 | // 类的方法,下面无法编译,因为divisor并不在lambda捕捉的范围 |
2 | std::function<bool(int)> getFilter() |
3 | { |
4 | return [divisor](int value) {return value % divisor == 0; }; |
5 | } |
原代码中,lambda表达式实际上捕捉的是this指针的副本,所以原来的代码等价于:
1 | std::function<bool(int)> getFilter() |
2 | { |
3 | return [this](int value) {return value % this->divisor == 0; }; |
4 | } |
尽管还是以值方式捕获,但是捕获的是指针,其实相当于以引用的方式捕获了当前类对象,所以lambda表达式的闭包与一个类对象绑定在一起了,这很危险,因为你仍然有可能在类对象析构后使用这个lambda表达式,那么类似“悬挂引用”的问题也会产生。所以,采用默认值捕捉所有变量仍然是不安全的,主要是由于__指针变量的复制,实际上还是按引用传值__。
lambda表达式可以赋值给对应类型的函数指针。但是使用函数指针并不是那么方便。所以STL定义在< functional >头文件提供了一个多态的函数对象封装std::function,其类似于函数指针。它可以绑定任何类函数对象,只要参数与返回类型相同。如下面的返回一个bool且接收两个int的函数包装器:
1 | std::function<bool(int, int)> wrapper = [](int x, int y) { return x < y; }; |
lambda表达式一个更重要的应用是其可以用于函数的参数,通过这种方式可以实现回调函数。
最常用的是在STL算法中,比如你要统计一个数组中满足特定条件的元素数量,通过lambda表达式给出条件,传递给count_if函数:
1 | nt value = 3; |
2 | vector<int> v {1, 3, 5, 2, 6, 10}; |
3 | int count = std::count_if(v.beigin(), v.end(), [value](int x) { return x > value; }); |
再比如你想生成斐波那契数列,然后保存在数组中,此时你可以使用generate函数,并辅助lambda表达式:
1 | vector<int> v(10); |
2 | int a = 0; |
3 | int b = 1; |
4 | std::generate(v.begin(), v.end(), [&a, &b] { int value = b; b = b + a; a = value; return value; }); |
5 | // 此时v {1, 1, 2, 3, 5, 8, 13, 21, 34, 55} |
当需要遍历容器并对每个元素进行操作时:
1 | std::vector<int> v = { 1, 2, 3, 4, 5, 6 }; |
2 | int even_count = 0; |
3 | for_each(v.begin(), v.end(), [&even_count](int val){ |
4 | if(!(val & 1)){ |
5 | ++ even_count; |
6 | } |
7 | }); |
8 | std::cout << "The number of even is " << even_count << std::endl; |
大部分STL算法,可以非常灵活地搭配lambda表达式来实现想要的效果。
新增容器
std::array
std::array 保存在__栈内存__中,相比__堆内存__中的 std::vector,我们能够灵活的访问这里面的元素,从而获得更高的性能。
std::array 会在编译时创建一个固定大小的数组,std::array 不能够被隐式的转换成指针,使用 std::array只需指定其类型和大小即可:
1 | std::array<int, 4> arr= {1,2,3,4}; |
2 | |
3 | int len = 4; |
4 | std::array<int, len> arr = {1,2,3,4}; // 非法, 数组大小参数必须是常量表达式 |
当我们开始用上了 std::array 时,难免会遇到要将其兼容 C 风格的接口,这里有三种做法:
1 | void foo(int *p, int len) { |
2 | return; |
3 | } |
4 | |
5 | std::array<int 4> arr = {1,2,3,4}; |
6 | |
7 | // C 风格接口传参 |
8 | // foo(arr, arr.size()); // 非法, 无法隐式转换 |
9 | foo(&arr[0], arr.size()); |
10 | foo(arr.data(), arr.size()); |
11 | |
12 | // 使用 `std::sort` |
13 | std::sort(arr.begin(), arr.end()); |
std::forward_list
std::forward_list 是一个列表容器,使用方法和 std::list 基本类似。
和 std::list 的双向链表的实现不同,std::forward_list 使用单向链表进行实现,提供了 O(1) 复杂度的元素插入,不支持快速随机访问(这也是链表的特点),也是标准库容器中唯一一个不提供 size() 方法的容器。当不需要双向迭代时,具有比 std::list 更高的空间利用率。
unorder container
C++11 引入了两组无序容器:
- std::unordered_map、std::unordered_multimap
- std::unordered_set、std::unordered_multiset
无序容器中的元素是不进行排序的,内部通过 Hash 表实现,插入和搜索元素的平均复杂度为 O(constant)。
- 使用标准类型时,可以不提供hash_key算法. unordered_map<T1, T2> vars;
- 使用自定义类型时,需要提供hash_key算法. unordered_map<T1, T2, hash_key> vars;
1 | struct hash_key //定制返回哈希值的仿函数 |
2 | { |
3 | //BKDRHash |
4 | size_t operator()(const Store& s) const |
5 | { |
6 | size_t seed = 131; /* 31 131 1313 13131 131313 etc.. */ |
7 | size_t hash = 0; |
8 | size_t i = 0; |
9 | for( i = 0; i < s.name.size(); ++i) |
10 | { |
11 | hash = ( hash * seed) + s.name[i]; |
12 | } |
13 | |
14 | std::cout << "hash:" << hash << endl; |
15 | return hash; |
16 | } |
17 | }; |
18 | |
19 | typedef unordered_map<Store, int, hash_key>::iterator MyIte; |
20 | |
21 | void test_unordered_map( ) |
22 | { |
23 | unordered_map<Store, int, hash_key> umap; |
24 | Store s1("火锅店", "重庆"); |
25 | Store s2("凉皮店", "西安"); |
26 | Store s3("烤鸭店", "北京"); |
27 | |
28 | umap.insert(make_pair(s1, 1)); |
29 | umap.insert(make_pair(s2, 1)); |
30 | umap.insert(make_pair(s3, 1)); |
31 | // umap[s3] = 1; |
32 | |
33 | MyIte it = umap.begin( ); |
34 | while( it != umap.end( )) |
35 | { |
36 | cout<<it->first.name<<"[" << it->first.addr << "]:" <<it->second<<endl; |
37 | ++it; |
38 | } |
39 | } |
std::tuple
元组的使用有三个核心的函数:
1 | std::make_tuple // 构造元组 |
2 | std::get //获得元组某个位置的值 |
3 | std::tie //元组拆包 |
1 | |
2 | |
3 | |
4 | auto get_student(int id) |
5 | { |
6 | // 返回类型被推断为 std::tuple<double, char, std::string> |
7 | if (id == 0) |
8 | return std::make_tuple(3.8, 'A', "张三"); |
9 | if (id == 1) |
10 | return std::make_tuple(2.9, 'C', "李四"); |
11 | if (id == 2) |
12 | return std::make_tuple(1.7, 'D', "王五"); |
13 | return std::make_tuple(0.0, 'D', "null"); |
14 | // 如果只写 0 会出现推断错误, 编译失败 |
15 | } |
16 | |
17 | int main() |
18 | { |
19 | auto student = get_student(0); |
20 | std::cout << "ID: 0, " |
21 | << "GPA: " << std::get<0>(student) << ", " |
22 | << "成绩: " << std::get<1>(student) << ", " |
23 | << "姓名: " << std::get<2>(student) << '\n'; |
24 | |
25 | double gpa; |
26 | char grade; |
27 | std::string name; |
28 | |
29 | // 元组进行拆包 |
30 | std::tie(gpa, grade, name) = get_student(1); |
31 | std::cout << "ID: 1, " |
32 | << "GPA: " << gpa << ", " |
33 | << "成绩: " << grade << ", " |
34 | << "姓名: " << name << '\n'; |
35 | } |
合并两个元组,可以通过 std::tuple_cat 来实现。
1 | auto new_tuple = std::tuple_cat(get_student(1), std::move(t)); |
std::tuple VS std::pair
std::tuple是类似pair的模板。每个pair的成员类型都不相同,但每个pair都恰好有两个成员。不同std::tuple类型的成员类型也不相同,但一个std::tuple可以有任意数量的成员。每个确定的std::tuple类型的成员数目是固定的,但一个std::tuple类型的成员数目可以与另一个std::tuple类型不同。
但我们希望将一些数据组合成单一对象,但又不想麻烦地定义一个新数据结构来表示这些数据时,std::tuple是非常有用的。我们可以__将std::tuple看作一个”快速而随意”的数据结构__。
当我们定义一个std::tuple时,需要指出每个成员的类型。
当我们创建一个std::tuple对象时,可以使用tuple的默认构造函数,它会对每个成员进行值初始化;
也以为每个成员提供一个初始值,此时的构造函数是explicit的,因此必须使用直接初始化方法。
类似make_pair函数,标准库定义了make_tuple函数,我们还可以使用它来生成std::tuple对象。
类似make_pair,make_tuple函数使用初始值的类型来推断tuple的类型。
一个std::tuple类型的成员数目是没有限制的,因此,tuple的成员都是未命名的。要访问一个tuple的成员,就要使用一个名为get的标准库函数模板。为了使用get,我们必须指定一个显式模板实参,它指出我们想要访问第几个成员。我们传递给get一个tuple对象,它返回指定成员的引用。get尖括号中的值必须是一个整型常量表达式。与往常一样,我们从0开始计数,意味着get<0>是第一个成员。
为了使用tuple_size或tuple_element,我们需要知道一个tuple对象的类型。与往常一样,确定一个对象的类型的最简单方法就是使用decltype。
std::tuple的关系和相等运算符的行为类似容器的对应操作。这些运算符逐对比较左侧tuple和右侧tuple的成员。只有两个tuple具有相同数量的成员时,我们才可以比较它们。而且,为了使用tuple的相等或不等运算符,对每对成员使用==运算符必须都是合法的;为了使用关系运算符,对每对成员使用 < 必须都是合法的。由于tuple定义了< 和 == 运算符,我们可以将tuple序列传递给算法,并且可以在无序容器中将tuple作为关键字类型。
std::tuple的一个常见用途是从一个函数返回多个值。
std::tuple是一个模板,允许我们将多个不同类型的成员捆绑成单一对象。每个tuple包含指定数量的成员,但对一个给定的tuple类型,标准库并未限制我们可以定义的成员数量上限。
std::tuple中元素是被紧密地存储的(位于连续的内存区域),而不是链式结构。
std::tuple实现了多元组,这是一个编译期就确定大小的容器,可以容纳不同类型的元素。多元组类型在当前标准库中被定义为可以用任意数量参数初始化的类模板。每一模板参数确定多元组中一元素的类型。所以,多元组是一个多类型、大小固定的值的集合。
1 | int test_tuple_4() |
2 | { // tuple::tuple: Constructs a tuple object. This involves individually constructing its elements, |
3 | // with an initialization that depends on the constructor form invoke |
4 | std::tuple<int, char> first; // default |
5 | std::tuple<int, char> second(first); // copy |
6 | std::tuple<int, char> third(std::make_tuple(20, 'b')); // move |
7 | std::tuple<long, char> fourth(third); // implicit conversion |
8 | std::tuple<int, char> fifth(10, 'a'); // initialization |
9 | std::tuple<int, char> sixth(std::make_pair(30, 'c')); // from pair / move |
10 | |
11 | std::cout << "sixth contains: " << std::get<0>(sixth); |
12 | std::cout << " and " << std::get<1>(sixth) << '\n'; |
13 | return 0; |
14 | } |
正则表达式
正则表达式描述了一种字符串匹配的模式。一般使用正则表达式主要是实现下面三个需求:
- 检查一个串是否包含某种形式的子串;
- 将匹配的子串替换;
- 从某个串中取出符合条件的子串。
C++11 提供的正则表达式库操作 std::string 对象,对模式 std::regex (本质是 std::basic_regex)进行初始化,通过 std::regex_match进行匹配,从而产生 std::smatch(本质是 std::match_results 对象)。
我们通过一个简单的例子来简单介绍这个库的使用。考虑下面的正则表达式:
[a-z]+.txt: 在这个正则表达式中, [a-z] 表示匹配一个小写字母, + 可以使前面的表达式匹配多次,因此 [a-z]+ 能够匹配一个及以上小写字母组成的字符串。在正则表达式中一个 . 表示匹配任意字符,而 . 转义后则表示匹配字符 . ,最后的 txt 表示严格匹配 txt 这三个字母。因此这个正则表达式的所要匹配的内容就是文件名为纯小写字母的文本文件。
std::regex_match 用于匹配字符串和正则表达式,有很多不同的重载形式。最简单的一个形式就是传入std::string 以及一个 std::regex 进行匹配,当匹配成功时,会返回 true,否则返回 false。例如:
1 | |
2 | |
3 | |
4 | |
5 | int main() { |
6 | std::string fnames[] = {"foo.txt", "bar.txt", "test", "a0.txt", "AAA.txt"}; |
7 | // 在 C++ 中 `\` 会被作为字符串内的转义符,为使 `\.` 作为正则表达式传递进去生效,需要对 `\` 进行二次转义,从而有 `\\.` |
8 | std::regex txt_regex("[a-z]+\\.txt"); |
9 | for (const auto &fname: fnames) |
10 | std::cout << fname << ": " << std::regex_match(fname, txt_regex) << std::endl; |
11 | } |
另一种常用的形式就是依次传入 std::string、std::smatch、std::regex 三个参数,其中 std::smatch 的本质其实是 std::match_results,在标准库中, std::smatch 被定义为了 std::match_results,也就是一个子串迭代器类型的 match_results。使用 std::smatch 可以方便的对匹配的结果进行获取,例如:
1 | std::regex base_regex("([a-z]+)\\.txt"); |
2 | std::smatch base_match; |
3 | for(const auto &fname: fnames) { |
4 | if (std::regex_match(fname, base_match, base_regex)) { |
5 | // sub_match 的第一个元素匹配整个字符串 |
6 | // sub_match 的第二个元素匹配了第一个括号表达式 |
7 | if (base_match.size() == 2) { |
8 | std::string base = base_match[1].str(); |
9 | std::cout << "sub-match[0]: " << base_match[0].str() << std::endl; |
10 | std::cout << fname << " sub-match[1]: " << base << std::endl; |
11 | } |
12 | } |
13 | } |
以上两个代码段的输出结果为:
1 | foo.txt: 1 |
2 | bar.txt: 1 |
3 | test: 0 |
4 | a0.txt: 0 |
5 | AAA.txt: 0 |
6 | sub-match[0]: foo.txt |
7 | foo.txt sub-match[1]: foo |
8 | sub-match[0]: bar.txt |
9 | bar.txt sub-match[1]: bar |
语言级线程支持
- std::thread
- std::mutex/std::unique_lock
- std::future/std::packaged_task
- std::condition_variable
代码编译需要使用 -pthread 选项
右值引用和move语义
以字符串处理为例
1 | string a(x); // line 1 |
2 | string b(x + y); // line 2 |
3 | string c(some_function_returning_a_string()); // line 3 |
如果使用以下拷贝构造函数:
1 | string(const string& that) |
2 | { |
3 | size_t size = strlen(that.data) + 1; |
4 | data = new char[size]; |
5 | memcpy(data, that.data, size); |
6 | } |
以上3行中,只有第一行(line 1)的x深度拷贝是有必要的,因为我们可能会在后边用到x,x是一个左值(lvalues)。
第二行和第三行的参数则是右值,因为表达式产生的string对象是匿名对象,之后没有办法再使用了。
C++ 11引入了一种新的机制叫做“右值引用”,以便我们通过重载直接使用右值参数。我们所要做的就是写一个以右值引用为参数的构造函数:
1 | string(string&& that) // string&& is an rvalue reference to a string |
2 | { |
3 | data = that.data; |
4 | that.data = 0; |
5 | } |
我们__没有深度拷贝堆内存__中的数据,而是仅仅__复制了指针,并把源对象的指针置空__。事实上,我们“偷取”了属于源对象的内存数据。由于__源对象是一个右值,不会再被使用,因此客户并不会觉察到源对象被改变了__。在这里,我们并没有真正的复制,所以我们把这个构造函数叫做 转移构造函数(move constructor),他的工作就是把资源从一个对象转移到另一个对象,而不是复制他们。
有了右值引用,再来看看赋值操作符:
1 | string& operator=(string that) |
2 | { |
3 | std::swap(data, that.data); |
4 | return *this; |
5 | } |
注意到我们是直接对参数that传值,所以that会像其他任何对象一样被初始化,那么确切的说,that是怎样被初始化的呢?对于__C++ 98,是复制构造函数__,但是__对于C++ 11,编译器会依据参数是左值还是右值在复制构造函数和转移构造函数间进行选择__。
如果是a=b,这样就会调用复制构造函数来初始化that(因为b是左值),赋值操作符会与新创建的对象交换数据,深度拷贝。这就是copy and swap 惯用法的定义:构造一个副本,与副本交换数据,并让副本在作用域内自动销毁。这里也一样。
如果是a = x + y,这样就会调用转移构造函数来初始化that(因为x+y是右值),所以这里没有深度拷贝,只有高效的数据转移。相对于参数,that依然是一个独立的对象,但是他的构造函数是无用的(trivial),因此堆中的数据没有必要复制,而仅仅是转移。没有必要复制他,因为x+y是右值,再次,从右值指向的对象中转移是没有问题的。
总结:复制构造函数执行的是深度拷贝,因为源对象本身必须不能被改变。而转移构造函数却可以复制指针,把源对象的指针置空,这种形式下,这是安全的,因为用户不可能再使用这个对象了。
下面我们进一步讨论__右值引用、move语义__。
C98标准库中提供了一种唯一拥有性的智能指针std::auto_ptr,该类型在C11中已被废弃,因为其“复制”行为是危险的。
1 | auto_ptr<Shape> a(new Triangle); |
2 | auto_ptr<Shape> b(a); |
注意b是怎样使用a进行初始化的,它不复制triangle,而是把triangle的所有权从a传递给了b,也可以说成“a 被转移进了b”或者“triangle被从a转移到了b”。
auto_ptr 的复制构造函数可能看起来像这样(简化):
1 | auto_ptr(auto_ptr& source) // note the missing const |
2 | { |
3 | p = source.p; |
4 | source.p = 0; // now the source no longer owns the object |
5 | } |
auto_ptr 的危险之处在于看上去应该是复制,但实际上确是转移。调用被转移过的auto_ptr 的成员函数将会导致不可预知的后果。所以你必须非常谨慎的使用auto_ptr ,如果他被转移过。
1 | auto_ptr<Shape> make_triangle() |
2 | { |
3 | return auto_ptr<Shape>(new Triangle); |
4 | } |
5 | |
6 | auto_ptr<Shape> c(make_triangle()); // move temporary into c |
7 | double area = make_triangle()->area(); // perfectly safe |
8 | |
9 | auto_ptr<Shape> a(new Triangle); // create triangle |
10 | auto_ptr<Shape> b(a); // move a into b |
11 | double area = a->area(); // undefined behavior |
然,在持有auto_ptr 对象的a表达式和持有调用函数返回的auto_ptr值类型的make_triangle()表达式之间一定有一些潜在的区别,每调用一次后者就会创建一个新的auto_ptr对象。这里a 其实就是一个左值(lvalue)的例子,而make_triangle()就是右值(rvalue)的例子。
转移像a这样的左值是非常危险的,因为我们可能调用a的成员函数,这会导致不可预知的行为。另一方面,转移像make_triangle()这样的右值却是非常安全的,因为复制构造函数之后,我们不能再使用这个临时对象了,因为这个转移后的临时对象会在下一行之前销毁掉。
我们现在知道转移左值是十分危险的,但是转移右值却是很安全的。如果C++能从语言级别支持区分左值和右值参数,我就可以完全杜绝对左值转移,或者把转移左值在调用的时候暴露出来,以使我们不会不经意的转移左值。
右值引用
C++ 11对这个问题的答案是__右值引用__。
右值引用是针对右值的新的引用类型,语法是X&&。以前的老的引用类型X& 现在被称作左值引用。
使用右值引用X&&作为参数的最有用的函数之一就是转移构造函数X::X(X&& source),它的主要作用是把源对象的本地资源转移给当前对象。
C++ 11中,std::auto_ptr< T >已经被std::unique_ptr< T >所取代,后者就是利用的右值引用。
其转移构造函数:
1 | unique_ptr(unique_ptr&& source) // note the rvalue reference |
2 | { |
3 | ptr = source.ptr; |
4 | source.ptr = nullptr; |
5 | } |
这个转移构造函数跟auto_ptr中复制构造函数做的事情一样,但是它却只能接受右值作为参数。
1 | unique_ptr<Shape> a(new Triangle); |
2 | unique_ptr<Shape> b(a); // error |
3 | unique_ptr<Shape> c(make_triangle()); // okay |
第二行不能编译通过,因为a是左值,但是参数unique_ptr&& source只能接受右值,这正是我们所需要的,杜绝危险的隐式转移。
第三行编译没有问题,因为make_triangle()是右值,转移构造函数会将临时对象的所有权转移给对象c,这正是我们需要的。
转移左值 std::move
有时候,我们可能想转移左值,也就是说,有时候我们想让编译器把左值当作右值对待,以便能使用转移构造函数,即便这有点不安全。出于这个目的,C++ 11在标准库的头文件< utility >中提供了一个模板函数std::move。
std::move仅仅是简单地将左值转换为右值,它本身并没有转移任何东西。它仅仅是让对象可以转移。
以下是如何正确的转移左值
1 | unique_ptr<Shape> a(new Triangle); |
2 | unique_ptr<Shape> b(a); // still an error |
3 | unique_ptr<Shape> c(std::move(a)); // okay |
注意: 第三行之后,a不再拥有Triangle对象。不过这没有关系,因为通过明确的写出std::move(a),我们很清楚我们的意图:亲爱的转移构造函数,你可以对a做任何想要做的事情来初始化c;我不再需要a了,对于a,您请自便。
当然,如果你在使用了mova(a)之后,还继续使用a,那无疑是搬起石头砸自己的脚,还是会导致严重的运行错误。
总之,std::move(some_lvalue)将左值转换为右值(可以理解为一种类型转换),使接下来的转移成为可能。
1 | class Foo |
2 | { |
3 | unique_ptr<Shape> member; |
4 | |
5 | public: |
6 | |
7 | Foo(unique_ptr<Shape>&& parameter) |
8 | : member(parameter) // error |
9 | {} |
10 | }; |
上面的parameter,其类型是一个右值引用,只能说明parameter是指向右值的引用,而parameter本身是个左值。(Things that are declared as rvalue reference can be lvalues or rvalues. The distinguishing criterion is: if it has a name, then it is an lvalue. Otherwise, it is an rvalue.)
因此以上对parameter的转移是不允许的,需要使用std::move来显示转换成右值
std::forward
std::forward 原型
1 | template <typename T> |
2 | T&& forward(typename std::remove_reference<T>::type& param) //左值引用版本 |
3 | { |
4 | return static_cast<T&&>(param); |
5 | } |
6 | |
7 | template <typename T> |
8 | T&& forward(typename std::remove_reference<T>::type&& param) //右值引用版本 |
9 | { |
10 | //param被右值初始化时,T应为右值引用类型,如果T被绑定为左值引用则报错。 |
11 | static_assert(!std::is_lvalue_reference<_Tp>::value, "template argument" |
12 | " substituting _Tp is an lvalue reference type"); |
13 | |
14 | return static_cast<T&&>(param); |
15 | } |
16 | |
17 | //其中remove_reference的实现如下 |
18 | //1. 特化版本(一般的类) |
19 | template <typename T> |
20 | struct remove_reference |
21 | { |
22 | typedef T type; |
23 | }; |
24 | |
25 | //2. 左值引用版本 |
26 | template <typename T> |
27 | struct remove_reference<T&> |
28 | { |
29 | typedef T type; |
30 | }; |
31 | |
32 | //3. 右值引用版本 |
33 | template <typename T> |
34 | struct remove_reference<T&&> |
35 | { |
36 | typedef T type; |
37 | }; |
完美转发(Perfect Forwarding)
完美转发
是指在函数模板中,完全依照模板的参数类型(即保持实参的左值、右值特性),将实参传递给函数模板中调用的另外一个函数。
原理分析
1 | class Widget{}; |
2 | |
3 | //完美转发 |
4 | template<typename T> |
5 | void func(T&& fparam) //fparam是个Universal引用 |
6 | { |
7 | doSomething(std::forward<T>(fparam)); |
8 | } |
9 | |
10 | //1. 假设传入func是一个左值的Widget对象, T被推导为Widget&,则forward如下: |
11 | Widget& && forward(typename std::remove_reference<Widget&>::type& param) |
12 | { |
13 | return static_cast<Widget& &&>(param); |
14 | } |
15 | //==>引用折叠折后 |
16 | Widget& forward(Widget& param) |
17 | { |
18 | return static_cast<Widget&>(param); |
19 | } |
20 | |
21 | //2. 假设传入func是一个右值的Widget对象, T被推导为Wiget,则forward如下: |
22 | Widget&& forward(typename std::remove_reference<Widget>::type& param) |
23 | { |
24 | return static_cast<Widget&&>(param); |
25 | } |
std::forward VS std::move
- std::move是无条件转换,不管它的参数是左值还是右值,都会被强制转换成右值。就其本身而言,它没有move任何东西。
- std::forward是有条件转换。只有在它的参数绑定到一个右值时,它才转换它的参数到一个右值。当参数绑定到左值时,转换后仍为左值。
- 对右值引用使用std::move,对universal引用则使用std::forward
- 如果局部变量有资格进行RVO优化,不要把std::move或std::forward用在这些局部变量中
- std::move和std::forward在运行期都没有做任何事情。
不完美转发和完美转发示例
1 | |
2 | |
3 | using namespace std; |
4 | |
5 | void print(const int& t) |
6 | { |
7 | cout <<"lvalue" << endl; |
8 | } |
9 | |
10 | void print(int&& t) |
11 | { |
12 | cout <<"rvalue" << endl; |
13 | } |
14 | |
15 | template<typename T> |
16 | void Test(T&& v) //v是Universal引用 |
17 | { |
18 | //不完美转发 |
19 | print(v); //v具有变量,本身是左值,调用print(int& t) |
20 | |
21 | //完美转发 |
22 | print(std::forward<T>(v)); //按v被初始化时的类型转发(左值或右值) |
23 | |
24 | //强制将v转为右值 |
25 | print(std::move(v)); //将v强制转为右值,调用print(int&& t) |
26 | } |
27 | |
28 | int main() |
29 | { |
30 | cout <<"========Test(1)========" << endl; |
31 | Test(1); //传入右值 |
32 | |
33 | int x = 1; |
34 | cout <<"========Test(x)========" << endl; |
35 | Test(x); //传入左值 |
36 | |
37 | cout <<"=====Test(std::forward<int>(1)===" << endl; |
38 | Test(std::forward<int>(1)); //T为int,以右值方式转发1 |
39 | //Test(std::forward<int&>(1)); //T为int&,需转入左值 |
40 | |
41 | cout <<"=====Test(std::forward<int>(x))===" << endl; |
42 | Test(std::forward<int>(x)); //T为int,以右值方式转发x |
43 | cout <<"=====Test(std::forward<int&>(x))===" << endl; |
44 | Test(std::forward<int&>(x)); //T为int,以左值方式转发x |
45 | |
46 | return 0; |
47 | } |
输出结果
1 | ========Test(1)======== |
2 | lvalue |
3 | rvalue |
4 | rvalue |
5 | ========Test(x)======== |
6 | lvalue |
7 | lvalue |
8 | rvalue |
9 | =====Test(std::forward<int>(1)=== |
10 | lvalue |
11 | rvalue |
12 | rvalue |
13 | =====Test(std::forward<int>(x))=== |
14 | lvalue |
15 | rvalue |
16 | rvalue |
17 | =====Test(std::forward<int&>(x))=== |
18 | lvalue |
19 | lvalue |
20 | rvalue |
万能的函数包装器
利用std::forward和可变参数模板实现
- 可将带返回值、不带返回值、带参和不带参的函数委托万能的函数包装器执行。
- Args&&为Universal引用,因为这里的参数可能被左值或右值初始化。Funciont&&也为Universal引用,如被lambda表达式初始化。
- 利用std::forward将参数正确地(保持参数的左、右值属性)转发给原函数
1 | |
2 | using namespace std; |
3 | |
4 | //万能的函数包装器 |
5 | //可将带返回值、不带返回值、带参和不带参的函数委托万能的函数包装器执行 |
6 | |
7 | //注意:Args&&表示Universal引用,因为这里的参数可能被左值或右值初始化 |
8 | // Funciont&&也为Universal引用,如被lambda表达式初始化 |
9 | template<typename Function, class...Args> |
10 | auto FuncWrapper(Function&& func, Args&& ...args)->decltype(func(std::forward<Args>(args)...)) |
11 | { |
12 | return func(std::forward<Args>(args)...); |
13 | } |
14 | |
15 | void test0() |
16 | { |
17 | cout << "void test0()" << endl; |
18 | } |
19 | |
20 | int test1() |
21 | { |
22 | return 1; |
23 | } |
24 | |
25 | int test2(int x) |
26 | { |
27 | return x; |
28 | } |
29 | |
30 | string test3(string s1, string s2) |
31 | { |
32 | return s1 + s2; |
33 | } |
34 | |
35 | int main() |
36 | { |
37 | |
38 | FuncWrapper(test0); |
39 | |
40 | cout << "int test1(): "; |
41 | cout << FuncWrapper(test1) << endl; |
42 | |
43 | cout << "int test2(int x): " ; |
44 | cout << FuncWrapper(test2, 1) << endl; |
45 | |
46 | cout << "string test3(string s1, string s2): "; |
47 | cout << FuncWrapper(test3, "aa", "bb") << endl; |
48 | |
49 | cout << "[](int x, int y){return x + y;}: "; |
50 | cout << FuncWrapper([](int x, int y){return x + y;}, 1, 2) << endl; |
51 | |
52 | return 0; |
53 | } |
输出结果:
1 | void test0() |
2 | int test1(): 1 |
3 | int test2(int x): 1 |
4 | string test3(string s1, string s2): aabb |
5 | [](int x, int y){return x + y}: 3 |
emplace_back减少内存拷贝和移动
- emplace_back的实现原理类似于“万能函数包装器”,将参数std::forward转发给元素类的构造函数。实现上,首先为该元素开辟内存空间,然后在这片空间中调用placement new进行初始化,这相当于“就地”(在元素所在内存空间)调用元素对象的构造函数。
- push_back会先将参数转为相应的元素类型,这需要调用一次构造函数,再将这个临时对象拷贝构造给容器内的元素对象,所以共需要一次构造和一次拷贝构造。从效率上看不如emplace_back,因为后者只需要一次调用一次构造即可。
- 一般传入emplace_back的是构造函数所对应的参数(也只有这样传参才能节省一次拷贝构造),所以要求对象有相应的构造函数,如果没有对应的构造函数,则只能用push_back,否则编译会报错。如emplace_back(int, int),则要求元素对象需要有带两个int型的构造函数。
1 | |
2 | |
3 | |
4 | using namespace std; |
5 | |
6 | class Test |
7 | { |
8 | int m_a; |
9 | public: |
10 | static int m_count; |
11 | |
12 | Test(int a) : m_a(a) |
13 | { |
14 | cout <<"Test(int a)" << endl; |
15 | } |
16 | |
17 | Test(const Test& t) : m_a(t.m_a) |
18 | { |
19 | ++m_count; |
20 | cout << "Test(const Test& t)" << endl; |
21 | } |
22 | |
23 | Test& operator=(const Test& t) |
24 | { |
25 | this->m_a = t.m_a; |
26 | return *this; |
27 | } |
28 | }; |
29 | |
30 | int Test::m_count = 0; |
31 | |
32 | int main() |
33 | { |
34 | //创建10个值为1的元素 |
35 | Test::m_count = 0; |
36 | vector<Test> vec(10, 1); //首先将1转为Test(1),会调用1次Test(int a)。然后,利用Test(1)去拷贝构造10个元素,所以调用10次拷贝构造。 |
37 | cout << "vec.capacity():" << vec.capacity() << ", "; //10 |
38 | cout << "vec.size():" << vec.size() << endl; //10,空间己满 |
39 | |
40 | Test::m_count = 0; |
41 | vec.push_back(Test(1)); |
42 | //由于capacity空间己满。首先调用Test(1),然后再push_back中再拷贝 |
43 | //构造10个元素(而不是1个,为了效率),所以调用10次拷贝构造 |
44 | cout << "vec.capacity():" << vec.capacity() << ", "; //20 |
45 | cout << "vec.size():" << vec.size() << endl; //11,空间未满 |
46 | |
47 | Test::m_count = 0; |
48 | vec.push_back(1); //先调用Test(1),然后调用1次拷贝构造 |
49 | cout << "vec.capacity():" << vec.capacity() << ", "; //20 |
50 | cout << "vec.size():" << vec.size() << endl; //12,空间未满 |
51 | |
52 | Test::m_count = 0; |
53 | vec.emplace_back(1); |
54 | //由于空间未满,直接在第12个元素位置调用placement new初始化那段空间 |
55 | //所以就会调用构造函数,节省了调用拷贝构造的开销 |
56 | cout << "vec.capacity():" << vec.capacity() << ", "; //20 |
57 | cout << "vec.size():" << vec.size() << endl; //13,空间未满 |
58 | |
59 | Test::m_count = 0; |
60 | vec.emplace_back(Test(1)); |
61 | //先调用Test(1),再调用拷贝构造(注意与vec.emplace_back(1)之间差异) |
62 | cout << "vec.capacity():" << vec.capacity() << ", "; //20 |
63 | cout << "vec.size():" << vec.size() << endl; //14,空间未满 |
64 | |
65 | return 0; |
66 | } |
输出结果
1 | Test(int a) |
2 | ... //中间省略了调用10次Test(const Test& t) |
3 | vec.capacity():10, vec.size():10 |
4 | Test(int a) |
5 | ... //中间省略了调用10次Test(const Test& t) |
6 | vec.capacity():20, vec.size():11 |
7 | Test(int a) |
8 | Test(const Test& t) |
9 | vec.capacity():20, vec.size():12 |
10 | Test(int a) |
11 | vec.capacity():20, vec.size():13 |
12 | Test(int a) |
13 | Test(const Test& t) |
14 | vec.capacity():20, vec.size():14 |
数据对齐 alignof、alignas
C++11主要引入两个关键字:操作符alignof、对齐描述符(alignment-specifier) alignas。操作符alignof的操作数表示一个定义完整的自定义类型或者内置类型或者变量,返回的值是一个std:: size_t类型的整型常量。如同sizeof操作符一样,alignof获得的也是一个与平台相关的值
1 | |
2 | using namespace std; |
3 | class InComplete; |
4 | |
5 | struct Completed{}; |
6 | |
7 | int main(){ |
8 | int a; |
9 | long long b; |
10 | auto& c=b; |
11 | char d[1024]; |
12 | //对内置类型和完整类型使用alignof |
13 | cout<<alignof(int)<<endl<<alignof(Completed)<<endl; //4,1 |
14 | //对变量、引用或者数组使用alignof, 数组的对齐值由其元素决定 |
15 | cout<<alignof(a)<<endl<<alignof(b)<<endl<<alignof(c)<<endl<<alignof(d)<<endl;//4,8,8,1 |
16 | //本句无法通过编译,Incomplete类型不完整 |
17 | //cout<<alignof(Incomplete)<<endl; |
18 | } |
对齐描述符alignas,既可以接受常量表达式,也可以接受类型作为参数,比如:c++ alignas(double) char c; 效果跟 c++ alignas(alignof(double)) char c; 是一样的。
注意 在C++11标准之前,我们也可以使用一些编译器的扩展来描述对齐方式,比如GNU格式的attribute((aligned(8))) 就是一个广泛被接受的版本。
C11标准建议用户在声明同一个变量的时候使用同样的对齐方式以免发生意外。不过C11并没有规定声明变量采用了不同的对齐方式就终止编译器的编译。
下面代码实现了一个固定容量但是大小随着所用的数据类型变化的容器类型
1 | |
2 | using namespace std; |
3 | struct alignas(alignof(double)*4) ColorVector{ |
4 | double r; |
5 | double g; |
6 | double b; |
7 | double a; |
8 | }; |
9 | //固定容量的模板数组 |
10 | template<typename T> |
11 | class FixedCapacityArray{ |
12 | public: |
13 | void push_back(T t){/*在data中加入t变量*/} |
14 | //... |
15 | //一些其他成员函数、成员变量等 |
16 | //... |
17 | char alignas(T) data[1024]={0}; |
18 | //int length=1024/sizeof(T); |
19 | }; |
20 | int main(){ |
21 | FixedCapacityArray<char> arrCh; |
22 | cout<<"alignof(char):"<<alignof(char)<<endl; |
23 | cout<<"alignof(arrCh.data):"<<alignof(arrCh.data)<<endl; |
24 | |
25 | FixedCapacityArray<ColorVector> arrCV; |
26 | cout<<"alignof(ColorVector):"<<alignof(ColorVector)<<endl; |
27 | cout<<"alignof(arrCV.data):"<<alignof(arrCV.data)<<endl; |
28 | |
29 | return 1; |
30 | } |
FixedCapacityArray固定使用1024字节的空间,但由于模板的存在,可以实例化为各种版本。这样一来,我们可以在相同的内存使用量的前提下,做出多种(内置或者自定义)版本的数组。对于arrCh,由于数组中的元素都是char类型,所以对齐到1就行了,而对于我们定义的arrCV, 必须使其符合ColorVector的扩展对齐,即对齐到8字节的内存边界上。在这个例子中,起到关键作用的代码是
1 | char alignas(T) data[1024]={0}; |
该句指示data[1024]这个char类型数组必须按照模板参数T的对齐方式进行对齐。
1 | alignof(char):1 |
2 | alignof(arrCh.data):1 |
3 | alignof(ColorVector):32 |
4 | alignof(arrCV.data):32 |
由于char数组默认对齐值为1,会导致data[1024]数组也对齐到1.这肯定不是编写FixedCapacityArray的程序员愿意见到的。
在C++11标准引入alignas修饰符之前,这样的固定容量的泛型数组有时可能遇到因为对齐不佳而导致的性能损失(甚至程序错误),这给库的编写者带来了很大的困扰。而引入alignas能够解决这些移植性的困难
C++11对于对齐的支持并不限于alignof操作符及alignas操作符。在STL库中,还内建了std::align函数来动态地根据指定的对齐方式调整数据块的位置
1 | void* align(std:: size_t alignment, std:: size_t size,void*&ptr,std:: size_t&space); |
该函数在ptr指向的大小为space的内存中进行对齐方式的调整,将ptr开始的size大小的数据调整为按alignment对齐
1 | |
2 | |
3 | using namespace std; |
4 | |
5 | struct ColorVector{ |
6 | double r; |
7 | double g; |
8 | double b; |
9 | double a; |
10 | }; |
11 | |
12 | int main(){ |
13 | size_t const size=100; |
14 | ColorVector* const vec=new ColorVector[size]; |
15 | void*p=vec; |
16 | size_t sz=size; |
17 | void* aligned=align(alignof(double)*4,size,p,sz); |
18 | |
19 | if(aligned!=nullptr) |
20 | cout<<alignof(p)<<endl; |
21 | } |
__注意:__C++11中的alignas能否完全代替#pragma pack
The alignas specifier may be applied to the declaration of a variable or a non-bitfield class data member, or it can be applied to the declaration or definition of a class/struct/union or enumeration. It cannot be applied to a function parameter or to the exception parameter of a catch clause.The object or the type declared by such a declaration will have its alignment requirement equal to the strictest (largest) non-zero expression of all alignas specifiers used in the declaration, unless it would weaken the natural alignment of the type.If the strictest (largest) alignas on a declaration is weaker than the alignment it would have without any alignas specifiers (that is, weaker than its natural alignment or weaker than alignas on another declaration of the same object or type), the program is ill-formed
如上所述,不能指定比本身还小的对齐
1 | struct alignas(1) Point |
2 | { |
3 | int a; |
4 | char b; |
5 | }p; |
6 | |
7 | cout<<alignof(p)<<endl; // output 4 |
8 | cout<<sizeof(p)<<endl; // output 8 |
9 | |
10 | |
11 | |
12 | struct Point2 |
13 | { |
14 | int a; |
15 | char b; |
16 | }p2; |
17 | |
18 | |
19 | cout<<alignof(p2)<<endl; //output 1 |
20 | cout<<sizeof(p2)<<endl; //output 5 |
通用属性
随着C语言的演化和编译器的发展,人们常会发现标准提供的语言能力不能完全满足要求。于是编译器厂商或组织为了满足编译器客户的需求,设计出一系列的语言扩展(language extension)来扩展语法。这些扩展语法并不存在于C/C标准中,却有可能拥有较多的用户。
扩展语法中比较常见的就是"属性"。属性是对语言中的实体对象(比如函数、变量、类型等)附加一些的额外注解信息,其用来实现一些语言及非语言层面的功能,或是实现优化代码等的一种手段。不同编译器有不同的属性语法。比如对于g++,属性是通过GNU的关键字__attribute__来声明的。程序员只需要简单地声明:__attribute__((attribute-list))即可为程序中的函数、变量和类型设定一些额外信息,以便编译器可以进行错误检查和性能优化等
1 | extern int area(int n) __attribute__((const)); |
2 | int main() |
3 | { |
4 | int i; |
5 | int areas=0; |
6 | for(i=0;i<10;i++) |
7 | { |
8 | areas+=area(3)*i; |
9 | } |
10 | } |
这里的const属性告诉编译器:本函数返回值只依赖于输入,不会改变任何函数外的数据,因此没有任何副作用。在此情况下,编译器可以对area函数进行优化处理。area(3)的值只需要计算一次,编译之后可以将area(3)视为循环中的常量而只使用其计算结果,从而大大提高了程序的执行性能。
GNU对C/C++使用__attribute__提供通用属性支持,windows平台下微软使用__declspec提供类似的支持
自定义通用属性
C11语言中的通用属性使用了左右双中括号的形式:**c [[attribute-list]]**
C++11的通用属性可以作用于类型、变量、名称、代码块等。对于作用于声明的通用属性,既可以写在声明的起始处,也可以写在声明的标识符之后。而对于作用于整个语句的通用属性,则应该写在语句起始处。而出现在以上两种规则描述的位置之外的通用属性,作用于哪个实体跟编译器具体的实现有关
预定义通用属性
在现有C++11标准中,只预定义了两个通用属性,分别是__[[noreturn]]__ 和 [[carries_dependency]]。
[[noreturn]] 是用于标识不会返回的函数的。这里必须注意,__不会返回__和__没有返回值的(void)__函数的区别。
没有返回值的void函数在调用完成后,调用者会接着执行函数后的代码;而不会返回的函数在被调用完成后,后续代码不会再被执行。[[noreturn]] 主要用于标识那些不会将控制流返回给原调用函数的函数,典型的例子有:有终止应用程序语句的函数、有无限循环语句的函数、有异常抛出的函数等。
1 | void DoSomething1(); |
2 | void DoSomething2(); |
3 | [[noreturn]] void ThrowAway(){ |
4 | throw "expection"; //控制流跳转到异常处理 |
5 | } |
6 | |
7 | void Func(){ |
8 | DoSomething1(); |
9 | ThrowAway(); |
10 | DoSomething2(); // 该函数不可到达 |
11 | } |
[[carries_dependency]] 则跟并行情况下的编译器优化有关。事实上,[[carries_depency]] 主要是为了解决弱内存模型平台上使用memory_order_consume内存顺序枚举问题。
memory_order_consume的主要作用是保证对当前 “原子类型数据” 的读取操作先于所有之后关于该原子变量的操作完成,但它不影响其他原子操作的顺序。要保证这样的"先于发生" 的关系,编译器往往需要根据memory_model枚举值在原子操作间构建一系列的依赖关系,以减少在弱一致性模型的平台上产生内存栅栏。不过这样的关系则往往会由于函数的存在而被破坏。
1 | |
2 | |
3 | using namespace std; |
4 | atomic<int*> p1; |
5 | atomic<int*> p2; |
6 | atomic<int*> p3; |
7 | atomic<int*> p4; |
8 | //定义了4个原子类型 |
9 | void func_in1(int*val){ |
10 | cout<<*val<<endl; |
11 | } |
12 | |
13 | void func_in2(int*[[carries_dependency]] val){ |
14 | p2.store(val,memory_order_release); //p2.store对p的使用会被保证在任何关于p的使用之后完成。 |
15 | cout<<*p2<<endl; |
16 | } |
17 | |
18 | [[carries_dependency]] int*func_out(){ |
19 | return(int*)p3.load(memory_order_consume); //p3.load对p的使用会被保证在任何关于p的使用之前完成。 |
20 | } |
21 | |
22 | void Thread(){ |
23 | int* p_ptr1=(int*)p1.load(memory_order_consume); //L1 |
24 | |
25 | cout<<*p_ptrl<<endl; //L2 |
26 | func_in1(p_ptr1); //L3 |
27 | func_in2(p_ptr1); //L4 |
28 | int*p_ptr2=func_out(); //L5 |
29 | p4.store(p_ptr2,memory_order_release); //L6 |
30 | cout<<*p_ptr2<<endl; |
31 | } |
L1句中,p1.load采用了memory_order_consume的内存顺序,因此任何关于p1或者p_ptr1的原子操作,必须发生在L1句之后。
L2将由编译器保证其执行必须在L1之后(通过编译器正确的指令排序和内存栅栏)。
编译器在处理L3时,由于func_in1对于编译器而言并没有声明[[carries_dependency]]属性,编译器则可能采用保守的方法,在func_in1调用表达式之前插入内存栅栏。
编译器在处理L4句时,由于函数func_in2使用了[[carries_dependency]], 编译器则会假设函数体内部会正确地处理内存顺序,因此不再产生内存栅栏指令。
事实上func_in2中也由于p2.store使用内存顺序memory_order_release, 因而不会产生任何的问题。
编译器处理L5句时,由于func_out的返回值使用了[[carries_dependency]],编译器也不会在返回前为p3.load(memory_order_consume) 插入内存栅栏指令去保证正确的内存顺序。
在L6行中,p4.store使用了memory_order_release, 因此func_out不产生内存栅栏也是毫无问题的。
[[noreturn]],[[carries_dependency]] 只是帮助编译器进行优化,这符合通用属性设计的原则。 当读者使用的平台是弱内存模型的时候,并且很关心并行程序的执行性能时,可以考虑使用 [[carries_dependency]]。
Unicode
C98标准中,为了支持Unicode,定义了“宽字符”的内置类型wchar_t. 不过不久程序员便发现C标准对wchar_t的“宽度”显然太过容忍,在Windows上,多数wchar_t被实现为16位宽,而在Linux上,则被实现为32位。事实上,C++98标准定义中,wchar_t的宽度是由编译器实现决定的。理论上,wchar_t的长度可以是8位、16位或者32位。这样带来的最大的问题是,程序员写出的包含wchar_t的代码通常不可移植。
C++11引入以下两种新的内置数据类型来存储不同编码长度的Unicode数据。
A char16_t: 用于存储UTF-16编码的Unicode数据。
B char32_t: 用于存储UTF-32编码的Unicode数据。
至于UTF-8编码的Unicode数据,C11还是使用8字节宽度的char类型的数组来保存。而char16_t和char32_t的长度则犹如其名称所显示的那样,长度分别为16字节和32字节,对任何编译器或者系统都是一样的。此外,C11还定义了一些常量字符串的前缀。在声明常量字符串的时候,这些前缀声明可以让编译器使字符串按照前缀类型产生数据。事实上,C++11一共定义了3种这样的前缀
1 | u8表示UTF-8编码 |
2 | u表示为UTF-16编码 |
3 | U表示为UTF-32编码 |
3种前缀对应着3种不同的Unicode编码。一旦声明了这些前缀,编译器会在产生代码的时候按照相应的编码方式存储。以上3种前缀加上基于宽字符wchar_t的前缀“L”, 及不加前缀的普通字符串字面量,算来在C++11中,一共有了5种方式来声明字符串字面量,其中4种是前缀表达的。
不要将各种前缀字符串字面量连续声明,因为标准定义除了UTF-8和宽字符字符串字面量同时声明会冲突外,其他字符串字面量的组合最终会产生什么结果,以及会按照什么类型解释,是由编译器实现自行决定的。因此应该尽量避免这种不可移植的字符串字面量声明方式。
C++11中还规定了一些简明的方式,即在字符串中用’\u’加4个十六进制数编码的Unicode码位(UTF-16)来标识一个Unicode字符。比如’\u4F60’ 表示的就是Unicode中的中文字符 “你”,而’\u597D’ 则是Unicode中的 “好”。此外,也可以通过’\U’ 后跟8个十六进制数编码的Unicode码位(UTF-32)的方式来书写Unicode字面常量
1 | |
2 | using namespace std; |
3 | int main(){ |
4 | char utf8[] =u8 "\u4F60\u597D\u597D\u554A"; //你好啊 |
5 | char16_t utf16[] =u "hello"; |
6 | char32_t utf32[] =U "hello equals\u4F60\u597D\u554A"; |
7 | |
8 | cout<<utf8<<endl; |
9 | cout<<utf16<<endl; |
10 | cout<<utf32<<endl; |
11 | |
12 | char32_t u2[] =u "hello"; //Error |
13 | char u3[] = U "hello"; //Error |
14 | char16_t u4=u8 "hello"; |
15 | } |
我们声明了3中不同类型的Unicode字符串utf8、utf16和utf32。由于无论对哪种Unicode编码,英文的Unicode码位都相同,因此只有非英文使用了"\u"的码位方式来标志。
使用了Unicode字符串前缀,这个字符串的类型就确定了,仅能放在相应类型的数组中。
u2、u3、u4就是因为类型不匹配而不能通过编译
原生字符串字面量 Raw String Literal
原生字符串字面量(raw string literal)并不是一个新鲜的概念,在许多编程语言中,我们都可以看到对原生字符串字面量的支持。 原生字符串使用户书写的字符串 “所见即所得”,不再需要如’\t’、’\n’等控制字符来调整字符串中的格式,这对编程语言的学习和使用都是具有积极意义的。
在C11中,终于引入了原生字符串字面量的支持。C11中原生字符串的声明相当简单,程序员只需要在字符串前加入前缀,即字母R,并在引号中用使用括号左右标识,就可以声明该字符串为原生字符串了。
R"(custom raw string inside the bracket)"