A = L U is “unsymmetric” because U has the pivots on its diagonal where L has l’s. This is easy to change. Divide U by a diagonal matrix D that contains the pivots. That leaves a new triangular matrix with l’s on the diagonal:
Split U into ⎣⎢⎢⎡d1d2⋱dn⎦⎥⎥⎤⎣⎢⎢⎢⎡1u12/d11u13/d1u23/d2⋱..⋮1⎦⎥⎥⎥⎤
(AB)T=BTAT
Vector Spaces and Subspaces
A real vector space is a set of “vectors” together with rules for vector addition and for multiplication by real numbers.
A subspace of a vector space is a set of vectors (including 0) that satisfies two requirements: If v and w are vectors in the subspace and c is any scalar, then
v + w is in the subspace.
cv is in the subspace.
A subspace containing v and w must contain all linear combinations cv + dw.
The column space consists of all linear combinations of the columns .The combinations are all possible vectors Ax. They fill the column space C(A).
For example Ax is ⎣⎡142033⎦⎤[x1x2] which is x1⎣⎡142⎦⎤+x2⎣⎡033⎦⎤
This column space is crucial., To solve Ax=b is to express b as a combination ofthe columns.
The system Ax=b is solvable if and only if b is in the column space of A.
The nullspaceN(A) in Rn contains all solutions x to Ax=0. This include x=0
Elimination (from A to U to R) does not change the nullspace: N(A)=N(U)=N(R).
Suppose Ax=0 has more unknowns than equations (n > m, more columns than rows). There must be at least one free column. Then Ax = 0 has nonzero solutions.
A short wide matrix (n>m) always has nonzero vectors in its nullspace. There must be at least n−m free variables, since the number of pivots cannot exceed m. (The matrix only has m rows, and a row never has two pivots.) Of course a row might have no pivot which means an extra free variable. But here is the point: When there is a free variable, it can be set to 1. Then the equation Ax=0 has at least a line of nonzero solutions.
The nullspace is a subspace. Its “dimension” is the number of free variables. This central idea-the dimension of a subspace
The rank of A is the number of pivots. This number is r. Every ''free column" is a combination of earlier pivot columns. It is the special solutions s that tell us those combinations.
Number of pivots=number of nonzero rows in R=rank r. There are n−r free columns.
The column space of a rank one matrix is “one-dimensional”, have the special rank one form A=uvT, which is form the rank one matrix, A=column times row=uvT , u,v are basis vector.
Complete solution to Ax=b is that x=(one particular solution xp) + (any xn in the nullspace)
The particular solutioni solves Axp=b
The n−r special solutions solve Axn=0
it means Axp+Axn=A(xp+xn)=b+0=b
Suppose A is a square invertible matrix, m=n=r. The particular solution is the one and only solution xp=A−1b. There are no special solutions or free variables. R=I has no zero rows. The only vectorin the nullspace is xn=0. The complete solution is x=xp+xn=A−1b+0.
Every matrix A with full column rank (r = n) has all these properties:
All columns of A are pivot columns.
There are no free variables or special solutions.
The nullspace N(A) contains only the zero vector x=0.
If Ax=b has a solution (it might not) then it has only one solution.
Every matrix A with full row rank (r = m) has all these properties:
All rows have pivots, and R has nozero rows.
Ax=b has a solution for every right side b.
The column space is the whole space Rm
There are n−r=n−m special solutions in the nullspace of A.
In this case with m pivots, the rows are “linearly independent”. So the columns of AT are linearly independent. The nullspace of AT is the zero vector.
The columns of A are linearly independent when the only solution to Ax=0 is x=0. No other combination Ax of the columns gives the zero vector.
The sequence of vectors v1,⋯,vn is linearly independent if the only combination that gives the zero vector is 0v1+0v2+⋯+0vn. that’s x1v1+x2v2+⋯+xnvn=0 only happens when all x's are zero.
The row space of A is C(AT), it’s the column space of AT
The vectors v1,⋯,vn are a basis for Rn exactly when they are the columns of an n×n invertible matrix. Thus Rn has infinitely many different bases.
The pivot columns of A are a basis for its column space. The pivot rows of A are a basis for its row space. So are the pivot rows of its echelon form R.
If v1,⋯,vm and w1,⋯,wn are both bases for the same vector space, then m=n. The dimension of a space is the number of vectors in every basis.
For example
for the matrix A=[122238] the column space C(A) and the row space C(AT) has a dimension 2, not 3
for the matrix B=⎣⎡123228⎦⎤ the column space C(B) and the row space C(BT) has a dimension 2, not 3
Four Fundamental Subspaces of matrix Am×n
The row space is C(AT), a subspace of Rn.
The column space is C(A), a subspace of Rm.
The nullspace is N(A), a subspace of Rn
The left nullspace is N(AT), a subspae of Rm.
For the left nullspace we solve ATy=0(the system is n×m. it is the nullspace of AT).
The vectors y go on the left side of A when the equation is written yTA=0T .
The row space and column space have the same dimension r=Rank(A). N(A) and N(AT) have dimensions n−r and m−r, to make up the full n and m.
In Rn the row space and nullspace have dimensions r and n−r
In Rm the column space and left nullspace have dimensions r and m−r
A matrix multiplies a vector: A times x.
At the first level this is only numbers.
At the second level Ax is a combination of column vectors.
The third level shows subspaces. The matrix Am×n's big picture as follow
The row space is perpendicular to the nullspace.
Every row of A is perpendicular to every solution of Ax=0.
The column space is perpendicular to the nullspace of AT
When b is outside the column space—when we want to solve Ax=b and can’t do it—then this nullspace of AT comes into its own. It contains the error e=b−Ax in the “least-squares” solution.
Every rank one matrix is one column times one row A=uvT. Rank Two Matrices = Rank One plus Rank One
For example as follow A=⎣⎡1140123720⎦⎤=⎣⎡114012001⎦⎤⎣⎡100010340⎦⎤=CR
The row space of R clearly has two basis vectors v1T=[1 0 3] and v2T=[0 1 4]. and the column space of C clearly has tow basic vectors u1=(1,1,4),u2=(0,1,2), Then A=[u1u2u3]⎣⎡v1Tv2Tzero row⎦⎤=u1v1T+u2v2T=(rank 1)+(rank 1)
Orthogonality
Orthogonality of the Four Subspaces
Orthogonality of the Four Subspaces
Orthogonal vectors have vTw=0.Then ∣∣v2∣∣+∣∣w2∣∣=∣∣v+w∣∣2=∣∣v−w∣∣2
Subspaces V and W are orthogonal when vTw=0 for every v in V and every w in W.
The row space of A is orthogonal to the nullspace. The column space is orthogonal to N(AT).
Row space and nullspace are orthogonal complements: Every x in Rn splits into Xrow+Xnull·
Every vector x in the nullspace is perpendicular to every row of A, because Ax=0.
The nullspaceN(A) and the row spaceC(AT) are orthogonal subspaces of Rn .
Proof as follow Ax=⎣⎢⎡row1⋮rowm⎦⎥⎤[x]=⎣⎢⎡0⋮0⎦⎥⎤. It’s cleary that $\text{(row m)} \cdot x $ is zero.
Or the seccond way to proof that orthogonality for readers who like matrix shorthand. The vectors in the row space are combinations ATy of the rows.
Take the dot product of ATy with any x in the nullspace. These vectors are perpendicular: xT(ATy)=(Ax)Ty=0Ty=0
Every vector y in the nullspace of AT is perpendicular to every column of A.
The left nullspaceN(AT) and the column spaceC(A) are orthogonal in Rm.
For a visual proof, look at ATy=0. Each column of A multiplies y to give 0: C(A)⊥N(AT) which is ATy=⎣⎡(column 1)T⋯(column n)T⎦⎤[y]=⎣⎡0.0⎦⎤
The dot product of y with every column of A is zero. Then y in the left nullspace is perpendicular to each column of A—and to the whole column space.
The orthogonal complement of a subspace V contains every vector that is perpendicular to V. This orthogonal subspace is denoted by V⊥(pronounced"V perp").
By this definition, the nullspace is the orthogonal complement of the row space.
Every x that is perpendicular to the rows satisfies Ax=0, and lies in the nullspace.
The reverse is also true. If v is orthogonal to the nullspace, it must be in the row space.
Otherwise we could add this v as an extra row of the matrix, without changing its nullspace. The row space would grow, which breaks the law r+(n−r)=n. We conclude that the nullspace complement N(A)⊥ is exactly the row space C(AT).
In the same way, the left nullspace and column space are orthogonal in Rm, and they are orthogonal complements. Their dimensions r and m−r add to the full dimension m.
N(A) is the orthogonal complement ofthe row space C(AT) (in Rn).
N(AT) is the orthogonal complement of the column space C(A) (in Rm ).
The point of **“complements” **is that every x can be split into a row space component r and a nullspace component xn . When A multiplies x=xr+xn , Figure below shows what happens to Ax=Axr+Axn :
The nullspace component goes to zero: Axn=0.
The row space component goes to the column space: Axr=Ax.
Every vector goes to the column space!
Multiplying by A cannot do anything else. More than that: Every vector b in the column space comes from one and only one vector xr in the row space.
Proof: If Axr=Axr′, the difference xr−xr′ is in the nullspace. It is also in the row space, where xr and xr′ came from. This difference must be the zero vector, because the nullspace and row space are perpendicular. Therefore xr=xr′
repeat one clear fact. A row of A can’t be in the nullspace of A (except for a zero row). The only vector in two orthogonal subspaces is the zero vector.
Projections
The projection of a vector b onto the line through a is the closest point p=aaTaaTb.
The projection matrix P=aTaaaT
p=λa=aλ=aaTaaTb=aTaaaTb=Pb, then the P is the projection matrix that handle the transform, p is the projection result vector.
The error e=b−p is perpendicular to a : Right triangle b,p,e has rulle ∣∣p∣∣+∣∣e∣∣=∣∣b∣∣.
2. The projection of b onto a subspace S is the closest vector p in S; b−p is orthogonal to S.
Assume n linearly independent. vectors a1,⋯,an in Rm.
Find the combination p=x^1a1+⋯+x^nan closest to a given vector b.
We compute projections onto $n-dimensional subspaces in 3 steps as before:
find the vector x
find the projection p=Ax
find the projection matrix P
The key is b to the nearest point Ax^ in the subspace. This error vector b−Ax^ is perpendicular to the subspace. The error b−Ax^ makes a right angle with all the vectors a1,⋯,an in the base. The n right angles give the n equations for x^: ⎣⎢⎡−a1T−⋮−anT−⎦⎥⎤[b−Ax^]=[0]
The matrix with those rows aiT is AT. The n equations are exactly AT(b−Ax^)=0.
Rewrite AT(b−Ax^)=0 in tis famous form ATAx^=ATb
The combination p=x^1a1+⋯+x^nan=Ax that is closest to b comes from x^:
Find x^(n×1)→AT(b−Ax^)=0 Or ATAx^=ATb
This symmetric matrix ATA is n by n. It is invertible if the a’s are independent.
The solution is x^=(ATA)−1ATb. The projection of b onto the subspace is p.
Find p(m×1)→p=Ax^=(ATA)−1ATb
The next formula picks out the projection matrix that is multiplying b in above
Find P(m×m)→P=A(ATA)−1AT
Compare with projection onto a line, when A has only one column : ATA is aTa.
For n=1→x^=aTaaTb,p=aaTaaTb,P=aTaaaT
The key step was AT(b−Ax^)=0. We can expressed it by geometry. Linear algebra gives this “normal equation” too, in a very quick and beautiful way :
Our subspace is the column space of A.
The error vector b−Ax^ is perpendicular to that column space.
Therefore b−Ax^ is in the nullspace of AT, that means AT(b−Ax^)=0
The left nullspace is important in projections. That nullspace of AT contains the error vector e=b−Ax^. The vector b is being split into the projection p and the error e=b−p. Projection produces a right triangle with sides p,e,b.
ATA is invertible if and only if A has linearly independent columns.
Least Squares Approximations
When Ax=b has no solution, multiply by AT and solve ATAx=ATb.
It often happens that Ax=b has no solution. The usual reason is: too many equations.
The matrix A has more rows than columns. There are more equations than unknowns (m>n). Then columns span a small part of m-dimensional space. Unless all measurements are perfect, b is outside that column space of A. Elimination reaches an impossible equation and stops. But we can’t stop just because measurements include noise!
WIth the projection, we can reduce the dimension difference.
So SolvingI ATAx=ATb gives the projection p=Ax^ of b onto the column space of A.
When Ax=b has no solution, xis the “least -squares solution”: ∣∣b−Ax^∣∣2=minimum.
Setting partial derivatives of E=∣∣Ax−b∣∣2 to zero (∂xi∂E=0)also produces ATAx=ATb.
To fit points (t1,b1),⋯,(tm,bm)by a straightline ,A has columns (1,⋯,1) and (t1,⋯,tm).
$Ax = b $ is C+Dt1=b1C+Dt2=b2⋮C+Dtm=bm with A=⎣⎢⎢⎢⎡11⋮1t1t2⋮tm⎦⎥⎥⎥⎤.
The column space is so thin that almost certainly b is outside of it. When b happens to lie in the column space, the points happen to lie on a line. In that case b=p. Then Ax=b is solvable and the errors are e=(0,⋯,0).
Turn the fitting points by a straight line to least squares and Solve ATAx^=ATb for x^=(C,D). The errors are ei=bi−C−Dti
The columns q1,⋯,qn are orthonormal if qiTqj={01fori=jfori=j. Then QTQ=1
If Q is also square then QT=Q−1
The least squares solution to Qx=b is x^=QTb. Projection of b is p=QQTb=Pb
With three independent vectors a,b,c to construct three orthogonal vectors A,B,C.
let A=a
then B=b−ATAATbA
then C=c−ATAATcA−BTBBTcB
The Factorization A=QR with q1=∣∣A∣∣A,q2=∣∣B∣∣B,q3=∣∣C∣∣C [abc]=[q1q2q3]⎣⎡q1Taq1Tbq2Tbq1Tcq2Tcq3Tc⎦⎤, which also is A=QR
Clearly, R=QTA
With A=QR→ATA=(QR)TQR=RTQTQR=RTR
So The least squares equation as follow ATAx^=ATb→RTRx^=RTQTb→Rx^=QTb x^=R−1QTb
Determinants
The determinant of an n by n matrix can be found in three ways:
Pivot formula.
Multiply the n pivots (times 1 or -1)
“Big” formula.
Add up n! terms (times 1 or -1)
Cofactor formula.
Combine n smaller determinants (times 1 or -1)
The properties of the determinant
The determinant of the n by n identity matrix is 1.
The determinant changes sign when two rows are exchanged (sign reversal).
The determinant is a linear function of each row separately(all other rows stay fixed)
If the first row is multiplied by t, the determinant is multiplied by t. If first rows are added, determinants are added. This rule only applies when the other rows do not change! Notice how e and d stay the same:
multiply row 1 by any number t, det is multiplied by t[tactbd]=t[acbd]
add row 1 of A to row 1 of A′, then determinants add [a+a′cb+b′d]=[acbd]+[a′cb′d]
If two rows of A are equal, then detA=0.
Subtracting a multiple of one row from another row leaves det A unchanged.
The determinant is not changed by the usual elimination steps from A to U.
Thus detA=detU. If we can find determinants of triangular matrices U, we can find determinants of all matrices A. Every row exchange reverses the sign, so always detA=±detU.
A matrix with a row of zeros has detA=0.
If A is triangular then detA=a11a22⋯ann=product ofdiagonal entries.
If A is singular then detA=0. If A is invertible then detA=0.
detA=±detU=±(product of the pivots)
the determinant of AB is detA times detB, that det(AB)=det(A)det(B) OR ∣AB∣=∣A∣∣B∣
(detA)(detA−1)=detI=1
the transpose AT has the same determinant as A, that’s detA=detAT
The Pivot Formula
When elimination leads to A=LU, the pivots d1,⋯,dn are on the diagonal of the upper triangular U. If no row exchanges are involved, multiply those pivots to find the determinant: detA=(detL)(detU)=(1)(d1d2⋯dn) (detP)(detA)=(detL)(detU)→detA=±(d1d2⋯dn).
Each pivot is a ratio of determinants, the kth pivot is dk=d1d2⋯dk−1d1d2⋯dk=detAk−1detAk
The Big Formula for Determinants
The formula has n! terms. Its size grows fast because $n! = 1, 2, 6, 24, 120, \cdots $
The determinant of A is the sum of these n! simple determinants times 1 or -1.
The simple determinants a1αa2β⋯anω choose one entry from every row and column.
detA=sum over all n! column permutationsP=(α,β,⋯,ω)=∑(detP)a1αa2β⋯anω=BigFormula
Determinant by Cofactors
The determinant is the dot product of any row i of A with its cofactors using other rows:
Cofactors Formula detA=ai1Ci1+ai2Ci2+⋯+ainCin
Each cofactor Cij (order n−l, without row i and column j) includes its correct sign:
Cofactor Cij=(−1)i+jdetMij
the submatrix Mij throws out row i and column j.
Cramer’s Rule, Inverses, and Volumes
The Cramer’s Rule solves Ax=b
A neat idea gives the first component x1 . Replacing the first column of I by x gives a matrix with determinant x1 . When you multiply it by A, thefirst column becomes Ax which is b. The other columns of B1 are copied from A: Key Idea[A]⎣⎡x1x2x3010001⎦⎤=⎣⎡b1b2b3a12a22a32a13a23a33⎦⎤=B1
With Product Rule (detA)(det⎣⎡x1x2x3010001⎦⎤)=detB1→(detA)(x1)=detB1→x1=detAdetB1
Wihe same procedure x2=detAdetB2,x3=detAdetB3
If detA is not zero, Ax=b is solved by determinants: x1=detAdetB1,x2=detAdetB2,xn=detAdetBn
The matrix Bj has the jth column of A replaced by the vector b.
A−1 involves the cofactors. When the right side is a column of the identity matrix I, as in AA−1=I, the determinant of each Bj in Cramer’s Rule is a cofactor of A.
The i,j entry of A−1 is the cofactor Cji(notCij) divided by detA. Formula For A−1→(A−1)ij=detACji→A−1=detACT
Area of a Triangle with 3 points (x1,y1),(x2,y2),(x3,y3)
Determinants are the best way to find area. The area of a triangle is half of a 3 by 3 determinant. Striangle=21∣∣∣∣∣∣x1x2x3y1y2y3111∣∣∣∣∣∣=21∣∣∣∣x1x2y1y2∣∣∣∣when (x3,y3)=(0,0)
The Cross Product
The cross product of u=(u1,u2,u3) and v=(v1,v2,v3) is a vector u×v=∣∣∣∣∣∣iu1v1ju2v2ku3v3∣∣∣∣∣∣=(u2v3−u3v2)i+(u3v1−u1v3)j+(u1v2−u2v1)k
This vector u×v is perpendicular to u and v. The cross product v×u is −(u×v).
that’s u×v⊥u and u×v⊥v and ∣∣u×v∣∣=∣∣u∣∣∣∣v∣∣∣sinθ∣. while ∣u⋅v∣=∣∣u∣∣∣∣v∣∣∣cosθ∣
Eigenvalues and Eigenvectors
The first part was about Ax=b: balance and equilibrium and steady state.
Now the second part is about change. Time enters the picture-continuous time in a differential equation du/dt=Au or time steps in a difference equation uk+i=Auk. Those equations are NOT solved by elimination.
The key idea is to avoid all the complications presented by the matrix A.
Suppose the solution vector u(t) stays in the direction of a fixed vector x. Then we only need to find the number (changing with time) that multiplies x. A number is easier than a vector. We want “eigenvectors”x that don’t change direction when you multiply by A.
vectors not change direction, when they are multiplied by A as Ax, that are the “eigenvectors”.
The basic equation is Ax=λx. The number λ is an eigenvalue of A.
The number λ is an eigenvalue of A if and only ifA−λI is singular. →det(A−λI)=0
The sum of the entries along the main diagonal is called the **trace **of A.
The sum of the n eigenvalues equals the sum of the n diagonal entries. λ1+λ2+⋯+λn=a11+a22+⋯+ann=Trace→i=1∑nλi=i=1∑naii=Trace
Theproduct ofthe n eigenvalues equals the determinant. λ1λ2⋯λn=detA→i=1∏nλi=detA
The matrix A turns into a diagonal matrixΛ when we use the eigenvectors properly.
Diagonalization: Suppose the n by n matrix A has n linearly independent eigenvectors x1,⋯,xn , Put them into the columns of an eigenvector matrix X. ThenX−1AX is the eigenvalue matrix Λ
The matrix X has an inverse, because its columns (the eigenvectors of A) were assumed to be linearly independent. Without n independent eigenvectors, we can’t diagonalize. A and Λ have the same eigenvalues λ1,⋯,λn · The eigenvectors are different.
Similar Matrices: Same Eigenvalues
Suppose the eigenvalue matrix Λ is fixed. As we change the eigenvector matrix X, we get a whole family of different matrices A=XΛX−1—all with the same eigenvalues in Λ. All those matrices A (with the same Λ) are called similar.
This idea extends to matrices that can’t be diagonalized. Again we choose one constant matrix C(not necessarily Λ). And we look at the whole family of matrices A=BCB−1, allowing all invertible matrices B. Again those matrices A and C are called similar
All the matrices A=BCB−1 are “similar”. The all share the eigenvalues of C
Proof: let Cx=λx→(BCB−1)(Bx)=BCx=Bλx=λ(Bx)→ABx=λ(Bx)
So with any B that invertible, the correspoding A family and the fixed C has the same eigenvalues for diffrent vectors.
Solve Fibonacci Numbers
As define "“Every new Fibonacci number is the sum of the two previous F’s”, find F100Fk+2=⎩⎪⎨⎪⎧01Fk+1+Fkk=0k=1k≥2
The key is to begin with a matrix equation uk+1=Auk. That is a one-step rule for vectors, while Fibonacci gave a two-step rule for scalars. We match those rules by putting two Fibonacci numbers into a vector. Then you will see the matrix A.
Let uk=[Fk+1Fk]→uk+1=[1110]uk
Every step multiplies by A=[1110], After 100 steps we reach u100=A100u0
This problem is just right for eigenvalues. Subtract λ from the diagonal of A A−λI=[1−λ11−λ]→det(A−λI)=λ2−λ−1=0 λ1,λ2 are the roots of the quadratic equation, that’s the eigenvalues
So the eigenvectors x1=[λ1,1]T,x2=[λ2,1]T
finds the combination of those eigenvectors that gives u0=[1,0]T [10]=λ1−λ21([λ11]−[λ21])→u0=λ1−λ2x1−x2
multiplies u0 by A100 to find u100 . The eigenvectors x1 and x2 stay separate!
Conclusion: Solve uk+1=Auk by uk=Aku0=XΛkX−1u0=c1(λ1)kx1+⋯+cn(λn)kxn
Fibonacci’s example is a typical difference equation uk+1=Auk. Each step multiplies by A. The solution is uk=Aku0. We want to make clear how diagonalizing the matrix gives a quick way to compute Ak and find Uk in three steps.
The eigenvector matrix X produces A=XΛX−1. This is a factorization of the matrix, like A=LU or A=QR. The new factorization is perfectly suited to computing powers, because every time X−1 multiplies X we get I.
**Powers of A: ** →Aku0=(XΛX−1)⋯(XΛX−1)u0=XΛkX−1u0
split XΛkX−1u0 into three steps that show how eigenvalues work:
Write u0 as a combination c1x1+⋅⋅⋅+cnxn ofthe eigenvectors. Then c=X−1u0
u0=[x1⋯xn]⎣⎢⎡c1⋮cn⎦⎥⎤→{u0=Xcc=X−1u0
Multiply each eigenvector xi by (λi)k. Now we have ΛkX−1u0.
Add up the pieces ci(λi)kxi to find the solution uk=Aku0. This is XΛkX−1u0
Behind these numerical examples lies a fundamental idea: Follow the eigenvectors.
This is the crucial link from linear algebra to differential equations (λk will become eλt). Later we’ll see the same idea as “transforming to an eigenvector basis.” The best example of all is a Fourier series, built from the eigenvectors eikx of d/dx.
Systems of Differential Equations
The whole point of the section is To convert constant-coefficient differential equations into linear algebra
System of n equations dtdu=Au starting from the vector u(0)=⎣⎡u1(0)⋯un(0)⎦⎤ at t=0
If Ax=λx then u(t)=eλtx will solve dtdu=Au. Each λ and x give a solution eλtx
If A=XΛX−1, then u(t)=eAtu(0)=XeΛtX−1u(0)=c1eλ1tx1+⋯+cneλntxn
Symmetric Matrices
It is no exaggeration to say that symmetric matrices S are the most important matrices.
A symmetric matrix has only real eigenvalues.
The eigenvectors can be chosen orthonormal.
Those n orthonormal eigenvectors go into the columns of X. Every symmetric matrix can be diagonalized. Its eigenvector matrix X becomes an orthogonal matrix Q. Orthogonal matrices have Q−1=QT — what we suspected about the eigenvector matrix is true. To remember it we write Q instead of X, when we choose orthonormal eigenvectors.
Every symmetric matrix has the factorization S=QΛQT with real eigenvalues in Λ and orthonormal eigenvectors in the columns of Q. Symmetric diagonalizationS=QΛQ−1=QΛQT
This says that every 2 by 2 symmetric matrix is (rotation)(stretch)(rotate back) S=QΛQT=[q1q2][λ1λ2][q1Tq2T]=λ1q1q1T+λ2q2q2T
For every symmetric matrix S=QΛQT=λ1q1q1T+⋯+λnqnqnT
Complex Eigenvalues of Real Matrices
For a symmetric matrix, lambda and x turn out to be real. Those two equations become the same. But a nonsymmetric matrix can easily produce,\ and x that are complex.
For real matrices, complex λ''s and x's come in “conjugate pairs.” {λ=a+ibλˉ=a−ib If Ax=λx→Axˉ=λˉxˉ
Eigenvalues versus Pivots
The eigenvalues of A are very different from the pivots.
For eigenvalues, we solve det(A−AI)=0.
For pivots, we use elimination.
The only connection so far is product of pivots = determinant = product of eigenvalues.
We are assuming a full set of pivots d1,⋯,dn. There are n real eigenvalues λ1,⋯,λn. The d's and λ's are not the same, but they come from the same symmetric matrix. The d's and λ's have a hidden relation. For symmetric matrices the pivots and the eigenvalues have the same signs
The number of positive eigenvalues of S=ST equals the number of positive pivots.
Special case: S has all Ai>0 if and only if all pivots are positive.
Positive Definite Matrices
This section concentrates on symmetric matrices that have positive eigenvalues.
SymmetricS:all eigenvalues>0⟺all pivots>0⟺all upper left determinants>0
@(Energy-based Definition)
S is positive definite if xTSx>0 for every nonzero vector x.
Sx=λx→xTSx=λxTx. The right side is a positive λ times a positive number xTx=∣∣x∣∣2 . So the left side xTSx is positive for any eigenvector.
If S and T are symmetric positive definite, so is S+T.
If the columns of A are independent, then S=ATA is positive definite.
xTSx=xTATAx=(Ax)T(Ax)=∣∣Ax∣∣2≥0
@(Positive Semidefinite Matrices)
Often we are at the edge of positive definiteness. The determinant is zero. The smallest eigenvalue is zero. These matrices on the edge are called positive semidefinite. Here are two examples (not invertible): S=[1224] and T=⎣⎡2−1−1−12−1−1−12⎦⎤
Positive semidefinite matrices have all $\lambda \ge 0 $ and all xTSx≥0. Those weak inequalities ( ≥ instead of > ) include positive definite S and also the singular matrices at the edge.
@(Application)[The Ellipse]
The tilted ellipse is associated with S. Its equation is xTSx=1.
The lined-up ellipse is associated with Λ. Its equation is XTΛX=1.
The rotation matrix that lines up the ellipse is the eigenvector matrix Q.
The tilted ellipse ax2+2bxy+cy2=1 →[xy][abbc][xy]=1→xTSx=1→S=[abbc]
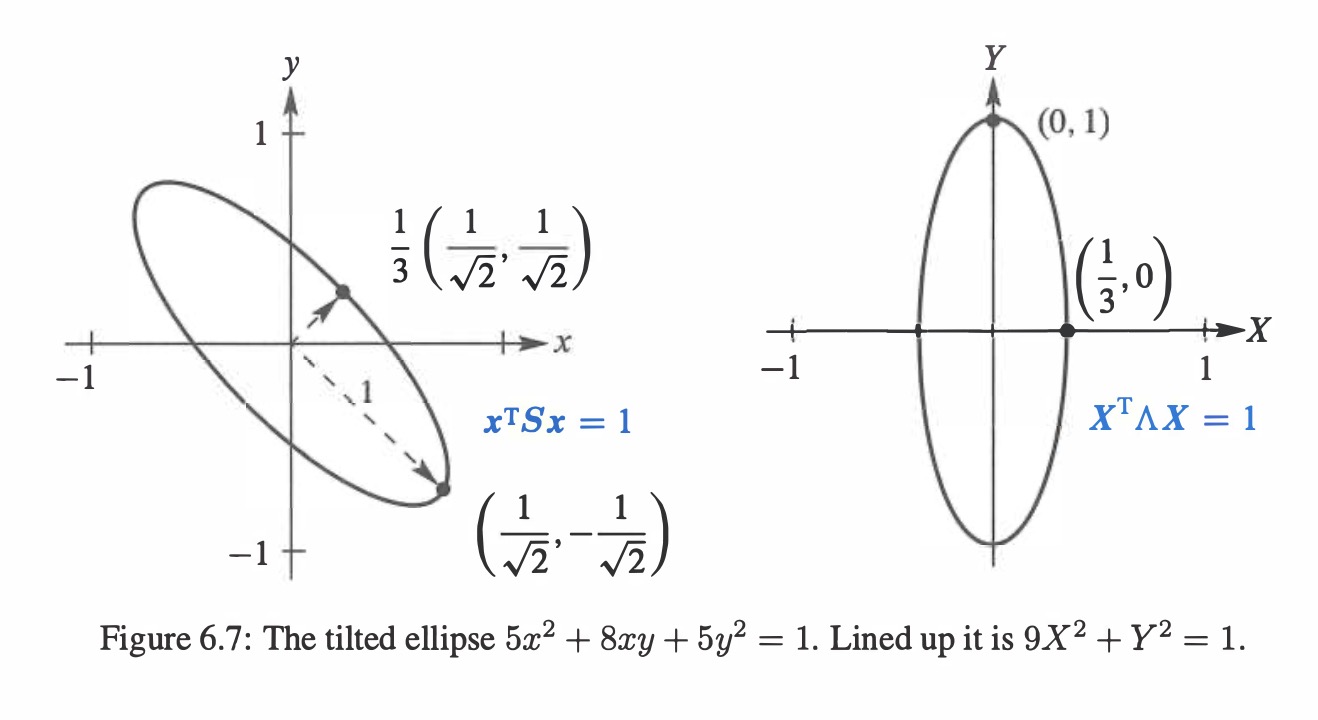
Example: Find the axes of this tilted ellipse 5x2+8xy+5y2=1. →S=[5445]→λ1=1,λ2=9→eigenvector[11],[1−1]→[5445]=21[111−1][9001]21[111−1]=QΛQT
Now multiply by [xy] on the left and[xy]Ton the right to get xTSx=(xTQ)Λ(QTx) xTSx=sum of squares→5x2+8xy+5y2=9(2x+y)2+1(2x−y)2
The coefficients are the eigenvalues 9 and 1 from Λ. Inside the squares are the eigenvectors q1=(1,1)/2 and q2=(1,−1)/2. The axes of the tilted ellipse point along those eigenvectors. This explains why S=QΛQT is called the “principal axis theorem”—it displays the axes.
S=QΛQT is positive definite when all λi>0. The graph of xTSx=1 is an ellipse Ellipse [xy]QΛQT[xy]=[XY]Λ[XY]=λ1X2+λ2Y2=1
The axes point along eigenvectors of S. The half-lengths are λ11 and λ21
Singular Value Decomposition (SVD)
Image Processing by Linear Algebra
The singular value theorem for A is the eigenvalue theorem for ATA and AAT.
A has two sets of singular vectors (the eigenvectors of ATA and AAT). There is one set of positive singular values (because ATA has the same positive eigenvalues as AAT). A is often rectangular, but ATA and AAT are square, symmetric, and positive semidefinite.
The Singular ValueDecomposition (SVD) separates any matrix into simple pieces.
Each piece is a column vector times a row vector.
Use the eigenvectors u of AAT and the eigenvectors v of ATA.
Since AAT and ATA are automatically symmetric (but not usually equal!) the u's will be one orthogonal set and the eigenvectors v will be another orthogonal set. We can and will make them all unit vectors: ∣∣ui∣∣=1 and ∣∣vi∣∣=1. Then our rank 2 matrix will be A=σ1u1v1T+σ2u2v2T The size of those numbers σ1 and σ2 will decide whether they can be ignored in compression. We keep larger σ's, we discard small σ's.
The u's from the SVD are called left singular vectors (unit eigenvectors of AAT ).
The v's from the SVD are called right singular vectors (unit eigenvectors of ATA ).
The σ's are singular values, square roots(λ) of the equal eigenvalues of AAT and ATA Choices from the SVD: AATui=σi2uiATAvi=σi2viAvi=σiui
Bases and Matrices in the SVD
A is any m by n matrix, square or rectangular. Its rank is r. We will diagonalize this A, but not by X−1AX. The eigenvectors in X have three big problems:
They are usually not orthogonal,
there are not always enough eigenvectors,
and Ax=λx requires A to be a square matrix.
The singular vectors of A solve all those problems in a perfect way.
The SVD produces orthonormal basis of v's and u's for the four fundamental subspaces.
There are two sets of singular vectors, u's and v's. The u's are in Rm and the v's are in Rn. They will be the columns of an m by m matrix U and an n by n matrix V
The u's and v's give bases for the four fundamental subspaces:
u1,⋯,ur is an orthonormal basis for the column space ur+1,⋯,um is an orthonormal basis for the left nullspace N(AT) v1,⋯,vr is an orthonormal basis for the row space vr+1,⋯,vn is an orthonormal basis for the nullspace N(A).
More than just orthogonality, these basis vectors diagonalize the matrix A:
A is diagonalizedAv1=σ1u1Av2=σ2u2⋯Avr=σrur
Those singular valuesσ1 to σr will be positive numbers: σi is the length of Avi. The σ's go into a diagonal matrix that is otherwise zero. That matrix is ∑.
Since the u's are orthonormal, the matrix Ur with those r columns has UrTUr=I. Since the v's are orthonormal, the matrix Vr has VrTVr=I. Then the equations Avi=σiui tell us column by column that AVr=Ur∑r
This is the heart of the SVD, but there is more. Those v's and u's account for the row space and column space of A. We have n−r more v's and m−r more u's, from the nullspace N(A) and the left nullspace N(AT). They are automatically orthogonal to the first v's and u's (because the whole nullspaces are orthogonal). We now include all the v's and u's in V and U, so these matrices become square. We still have AV=U∑.
The new ∑ is m by n. It is just the r by r matrix inequation above with m−r extra zero rows and n−r new zero columns. The real change is in the shapes of U and V. Those are square matrices and V−1=VT . So AV=U∑ becomes A=U∑V . This is the Singular Value Decomposition.
SVDA=U∑VT=u1σ1v1T+⋯+urσrvrT
It’s is crucial that each σi2 is an eigenvalue of ATA and also AAT. When we put the singular values in descending order, σ1≥σ2≥⋯σr>0, the splitting in equation above gives the r rank-one pieces of A in order of importance.
Example, Find the matrices U,∑,V for A=[3405]
→ATA=[25202025],AAT=[9121241]→λ1=45,λ2=5→σ12=λ1=45,σ22=λ2=5→eigenvectors for ATA,v1=21[11],v2=21[−11]→ui=σiAvi→u1=101[13],u2=101[−31]→U=101[13−31],∑=[455],V=21[11−11]→AV=U∑→A=U∑V−1→A=σ1u1v1T+σ2u2v2T
This section explains a major application of the SVD to statistics and data analysis.
PCA gives a way to understand a data plot in dimension m= the number of measured variables (here age and height). Subtract average age and height (m=2 for n samples) to center the m by n data matrix A. The crucial connection to linear algebra is in the singular values and singular vectors of A. Those come from the eigenvalues λ=σ2 and the eigenvectors u of the sample covariance matrix S=AAT/(n−1).
The total variance in the data is the sum of all eigenvalues and of sample variances s2 : Total variance T=σ12+⋯+σm2=s12+⋯+sm2=trace (diagonal sum)
The first eigenvector u1 of S points in the most significant direction of the data. That direction accounts for (or explains) a fraction σ12/T of the total variance.
The next eigenvector u2 (orthogonal to u1) accounts for a smaller fraction σ22/T.
Stop when those fractions are small. You have the R directions that explain most of the data. The n data points are very near an R-dimensional subspace with basis u1 to UR — These u's are the principal components in m−dimensional space.
R is the “effective rank” of A. The true rank r is probably m or n : full rank matrix.