introduction
keywords
-
supervised learning
Supervised learning, in the context of artificial intelligence (AI) and machine learning, is a type of system in which both input and desired output data are provided. Input and output data are labelled for classification to provide a learning basis for future data processing. -
unsupervised learning
opposite of supervised learning -
classification
Cases such as the digit recognition example, in which the aim is to assign each input vector to one of a finite number of discrete categories -
reinforcement learning
Reinforcement learning is where a system, or agent, tries to maximize some measure of reward while interacting with a dynamic environment. If an action is followed by an increase in the reward, then the system increases the tendency to produce that action. -
regression
If the desired output consists of one or more continuous variables, then the task is called regression
-
error function
-
over-fitting
-
generalization
-
credit assignment
-
regularization
-
maximum likelihood
-
Polynomial Curve Fitting
-
shrinkage methods
-
ridge regression
-
weight decay
-
Minkowski loss
-
differential entropy
In other pattern recognition problems, the training data consists of a set of input vectors x without any corresponding target values. The goal in such unsupervised learning problems may be to discover groups of similar examples within the data, where it is called clustering, or to determine the distribution of data within the input space, known as density estimation, or to project the data from a high-dimensional space down to two or three dimensions for the purpose of visualization.
Polynomial Curve Fitting
suppose that we are given a training set comprising N observations of x, written
together with corresponding observations of the values of t ,denoted
we shall fit the data using a polynomial function of the form
where n is the order of the polynomial, and denotes x raised to the power of j.
The polynomial coefficients , … , are collectively denoted by the vector w.
Note that, although the polynomial function is a nonlinear function of x, it is a linear function of the coefficients w.
The values of the coefficients will be determined by fitting the polynomial to the training data. This can be done by minimizing an error function that measures the misfit between the function , for any given value of w, and the training set data points.
One simple choice of error function, which is widely used, is given by the sum of the squares of the errors between the predictions for each data point and the corresponding target values , so that we minimize
where the factor of 1/2 is included for later convenience. We can solve the curve fitting problem by choosing the value of w for which E(w) is as small as possible.
It is sometimes more convenient to use the root-mean-square
in which the division by N allows us to compare different sizes of data sets on an equal footing, and the square root ensures that is measured on the same scale (and in the same units) as the target variable t.
there is something rather unsatisfying about having to limit the number of parameters in a model according to the size of the available training set. It would seem more reasonable to choose the complexity of the model according to the complexity of the problem being solved. We shall see that the least squares approach to finding the model parameters represents a specific case of maximum likelihood, and that the over-fitting problem can be understood as a general property of maximum likelihood. By adopting a Bayesian approach, the over-fitting problem can be avoided. We shall see that there is no difficulty from a Bayesian perspective in employing models for which the number of parameters greatly exceeds the number of data points. Indeed, in a Bayesian model the effective number of parameters adapts automatically to the size of the data set
For the moment, however, it is instructive to continue with the current approach and to consider how in practice we can apply it to data sets of limited size where we may wish to use relatively complex and flexible models. One technique that is often used to control the over-fitting phenomenon in such cases is that of regularization, which involves adding a penalty term to the error function (1.1.2) in order to discourage the coefficients from reaching large values. The simplest such penalty term takes the form of a sum of squares of all of the coefficients, leading to a modified error function of the form
where , and the coefficient λ governs the relative importance of the regularization term compared with the sum-of-squares error term.
Note that often the coefficient w0 is omitted from the regularizer because its inclusion causes the results to depend on the choice of origin for the target variable (Hastie et al., 2001), or it may be included but with its own regularization coefficient.
Again, the error function in (1.1.4) can be minimized exactly in closed form. Techniques such as this are known in the statistics literature as shrinkage methods because they reduce the value of the coefficients. The particular case of a quadratic regularizer is called ridge regres- sion (Hoerl and Kennard, 1970). In the context of neural networks, this approach is known as weight decay.
Probability Theory
Probability densities
A key concept in the field of pattern recognition is that of uncertainty. It arises both through noise on measurements, as well as through the finite size of data sets. Prob- ability theory provides a consistent framework for the quantification and manipula- tion of uncertainty and forms one of the central foundations for pattern recognition. Combined with decision theory, it allows us to make optimal predictions given all the information available to us, even though that information may be incomplete or ambiguous.
The probability that X will take the value and Y will take the value is written and is called the joint probability of X = and . It is given by the number of points falling in the cell i,j as a fraction of the total number of points, and hence
Here we are implicitly considering the limit . Similarly, the probability that X takes the value irrespective of the value of Y is written as and is given by the fraction of the total number of points that fall in column i, so that
Because the number of instances in column i is just the sum of the number of instances in each cell of that column, we have nij and therefore, from (1.2.1) and (1.2.2), we have
which is the sum rule of probability. Note that is sometimes called the marginal probability, because it is obtained by marginalizing, or summing out, the other variables (in this case Y ).
If we consider only those instances for which , then the fraction of such instances for which is written and is called the conditional probability of given . It is obtained by finding the fraction of those points in column i that fall in cell i,j and hence is given by
From (1.2.1), (1.2.2), (1.2.4) we can then derive the following relationship
which is the product rule of probability.
two fundamental rules of probability theory in the following form.
- sum rule
- product rule
From the product rule, together with the symmetry property , we immediately obtain the following relationship between conditional probabilities
which is called Bayes’ theorem and which plays a central role in pattern recognition and machine learning.
Using the sum rule, the denominator in Bayes’ theorem can be expressed in terms of the quantities appearing in the numerator
We can view the denominator in Bayes’ theorem as being the normalization constant required to ensure that the sum of the conditional probability on the left-hand side of (1.2.8) over all values of Y equals one.
Probability densities
As well as considering probabilities defined over discrete sets of events, we also wish to consider probabilities with respect to continuous variables. If the probability of a real-valued variable x falling in the interval is given by for , then is called the probability density over x. The probability that x will lie in an interval is then given by
Because probabilities are nonnegative, and because the value of x must lie somewhere on the real axis, the probability density p(x) must satisfy the two conditions
- probabilities are nonnegativ
- integrad of probability density is 1
Under a nonlinear change of variable, a probability density transforms differently from a simple function, due to the Jacobian factor. For instance, if we consider a change of variables , then a function becomes . Now consider a probability density that corresponds to a density with respect to the new variable y, where the suffices denote the fact that and are different densities. Observations falling in the range will, for small values of , be transformed into the range where , and hence
One consequence of this property is that the concept of the maximum of a probability density is dependent on the choice of variable.
The probability that x lies in the interval is given by the cumulative distribution function(CDF) defined by
which satisfies
If we have several continuous variables , denoted collectively by the vector x, then we can define a joint probability density such that the probability of x falling in an infinitesimal volume containing the point x is given by . This multivariate probability density must satisfy and in which the integral is taken over the whole of x space. We can also consider joint probability distributions over a combination of discrete and continuous variables.
Note that if x is a discrete variable, then is sometimes called a probability mass function because it can be regarded as a set of ‘probability masses’ concentrated at the allowed values of x.
The sum and product rules of probability, as well as Bayes’ theorem, apply equally to the case of probability densities, or to combinations of discrete and continuous variables. For instance, if x and y are two real variables, then the sum and product rules take the form
- sum rule
- product rule
Expectations and covariances
One of the most important operations involving probabilities is that of finding weighted averages of functions. The average value of some function under a probability distribution is called the expectation of and will be denoted by .
- For a discrete distribution, the average is weighted by the relative probabilities of the different values of x
- For continuous variables, expectations are expressed in terms of an integration with respect to the corresponding probability density
In either case, if we are given a finite number N of points drawn from the probability distribution or probability density, then the expectation can be approximated as a finite sum over these points
Sometimes we will be considering expectations of functions of several variables, in which case we can use a subscript to indicate which variable is being averaged over, so that for instance denotes the average of the function with respect to the distribution of x. Note that will be a function of y.
We can also consider a conditional expectation with respect to a conditional distribution, so that
The variance of f(x) is defined by
Expanding out the square, we see that the variance can also be written in terms of the expectations of and
for variabce of one variable x
for random variables x and y, the covariance is defined by
for two vectors of random variables and , the covariance is a matrix
Bayesian probabilities
So far, we have viewed probabilities in terms of the frequencies of random, repeatable events. We shall refer to this as the classical or frequentist interpretation of probability. Now we turn to the more general Bayesian view, in which probabilities provide a quantification of uncertainty.
we can adopt a similar approach when making inferences about quantities such as the parameters in the polynomial curve fitting example. We capture our assumptions about , before observing the data, in the form of a prior probability distribution . The effect of the observed data is expressed through the conditional probability , how this can be represented explicitly. Bayes’ theorem, which takes the form
then allows us to evaluate the uncertainty in after we have observed D in the form of the posterior probability
The quantity on the right-hand side of Bayes’ theorem is evaluated for the observed data set and can be viewed as a function of the parameter vector , in which case it is called the likelihood function.It expresses how probable the observed data set is for different settings of the parameter vector .
Note that the likelihood is not a probability distribution over , and its integral with respect to does not (necessarily) equal one.
Given this definition of likelihood, we can state Bayes’ theorem in words: where all of these quantities are viewed as functions of .
The denominator in (1.2.23) is the normalization constant, which ensures that the posterior distribution on the left-hand side is a valid probability density and integrates to one. Indeed, integrating both sides of (1.2.23) with respect to , we can express the denominator in Bayes’ theorem in terms of the prior distribution and the likelihood function
In both the Bayesian and frequentist paradigms, the likelihood function plays a central role. However, the manner in which it is used is fundamentally different in the two approaches. In a frequentist setting, is considered to be a fixed parameter, whose value is determined by some form of ‘estimator’, and error bars on this estimate are obtained by considering the distribution of possible data sets . By contrast, from the Bayesian viewpoint there is only a single data set (namely the one that is actually observed), and the uncertainty in the parameters is expressed through a probability distribution over .
A widely used frequentist estimator is maximum likelihood, in which is set to the value that maximizes the likelihood function . This corresponds to choosing the value of for which the probability of the observed data set is maximized. In the machine learning literature, the negative log of the likelihood function is called an error function. Because the negative logarithm is a monotonically decreasing function, maximizing the likelihood is equivalent to minimizing the error.
The Gaussian distribution
For the case of a single real-valued variable x, the Gaussian distribution is defined by
which is governed by two parameters: , called the mean, and , called the variance. The square root of the variance, given by , is called the standard deviation, and the reciprocal of the variance, written as , is called the precision.
From the form of (1.2.25) we see that the Gaussian distribution satisfies . Also it is straightforward to show that the Gaussian is normalized, so that
Proof the form (1.2.26-1.2.29) with standard gaussian distribution(), the common gaussian distribution can be linear transform of the standard one.
gaussian distribution
standard gaussian distribution
let then
let
so
where
then
then
then
image that
then
clearly
as the normal gaussion distribution satisfiestranslate rule:
scale rule:
so the integral of any gaussion distribution density function equals 1
mean of guassion distribution:
gaussian distribution function defined
where and are two parameters, with . By definition of the mean we have
let
let
clearly that, let then the is a symmetric way of that
so and
let
as proofed, the integral of any gaussion distribution density function equals 1,
variance of guassion distribution:
with the same tricks (let ) as before we have
let
thenas so
then , integrad both side
thenas Hopital Rule:
then
then
let
then
let
so
then
then
theorem for gaussion density function
We are also interested in the Gaussian distribution defined over a D-dimensional vector x of continuous variables, which is given by
where the D-dimensional vector is called the mean, the D × D matrix is called the covariance, and denotes the determinant of .
Now suppose that we have a data set of observations , rep- resenting N observations of the scalar variable . Note that we are using the typeface to distinguish this from a single observation of the vector-valued variable , which we denote by . We shall suppose that the observations are drawn independently from a Gaussian distribution whose mean and variance are unknown, and we would like to determine these parameters from the data set. Data points that are drawn independently from the same distribution are said to be independent and identically distributed, which is often abbreviated to i.i.d. We have seen that the joint probability of two independent events is given by the product of the marginal probabilities for each event separately. Because our data set is i.i.d., we can therefore write the probability of the data set, given and , in the form
With the dataset sample m times randomly, get the m group data, denoted
then the likelihood function is
One common criterion for determining the parameters in a probability distribu- tion using an observed data set is to find the parameter values that maximize the likelihood function. This might seem like a strange criterion because, from our fore- going discussion of probability theory, it would seem more natural to maximize the probability of the parameters given the data, not the probability of the data given the parameters.In fact, these two criteria are related, as we shall discuss in the context of curve fitting.
For the moment, however, we shall determine values for the unknown parameters and in the Gaussian by maximizing the likelihood function (1.2.31). In practice, it is more convenient to maximize the log of the likelihood function. Because the logarithm is a monotonically increasing function of its argument, maximization of the log of a function is equivalent to maximization of the function itself. Taking the log not only simplifies the subsequent mathematical analysis, but it also helps numerically because the product of a large number of small probabilities can easily underflow the numerical precision of the computer, and this is resolved by computing instead the sum of the log probabilities.From (1.2.25) and (1.2.31), the log likelihood function can be written in the form
Maximizing (1.2.32) with respect to , that , we obtain the maximum likelihood solution given by
which is the sample mean, i.e., the mean of the observed values . Similarly, maximizing (1.2.32) with respect to , that we obtain the maximum likelihood solution for the variance in the form
which is the sample variance measured with respect to the sample mean
Note that we are performing a joint maximization of (1.2.32) with respect to and , but in the case of the Gaussian distribution the solution for decouples from that for so that we can first evaluate (1.2.33) and then subsequently use this result to evaluate (1.2.34).
We first note that the maximum likelihood solutions and are functions of the data set values . Consider the expectations of these quantities with respect to the data set values, which themselves come from a Gaussian distribution and . It is straightforward to show that
so that on average the maximum likelihood estimate will obtain the correct mean but will underestimate the true variance by a factor .
The intuition behind this result is that aeraged across the N data sets, the mean is correct, but the variance is systematically under-estimated because it is measured relative to the sample mean and not relative to the true mean.
From (1.2.36) it follows that the following estimate for the variance parameter is unbiased
Note that the bias of the maximum likelihood solution becomes less significant as the number N of data points increases, and in the limit the maximum likelihood solution for the variance equals the true variance of the distribution that generated the data. In practice, for anything other than small N, this bias will not prove to be a serious problem. However, throughout this book we shall be interested in more complex models with many parameters, for which the bias problems associated with maximum likelihood will be much more severe. In fact, as we shall see, the issue of bias in maximum likelihood lies at the root of the over-fitting problem that we encountered earlier in the context of polynomial curve fitting.
Prooved of the formula (1.2.37)let sample meal , sample variance , population mean , populatioin variance
consider variance definition without bias
clearly, when devide n, , furthermore
so when consider the bias
Curve fitting re-visited
We have seen how the problem of polynomial curve fitting can be expressed in terms of error minimization. Here we return to the curve fitting example and view it from a probabilistic perspective, thereby gaining some insights into error functions and regularization, as well as taking us towards a full Bayesian treatment.
The goal in the curve fitting problem is to be able to make predictions for the target variable t given some new value of the input variable x on the basis of a set of training data comprising N input values and their corresponding target values . We can express our uncertainty over the value of the target variable using a probability distribution. For this purpose, we shall assume that, given the value of , the corresponding value of has a Gaussian distribution with a mean equal to the value of the polynomial curve given Thus we have
where we have defined a precision parameter corresponding to the inverse variance of the distribution.
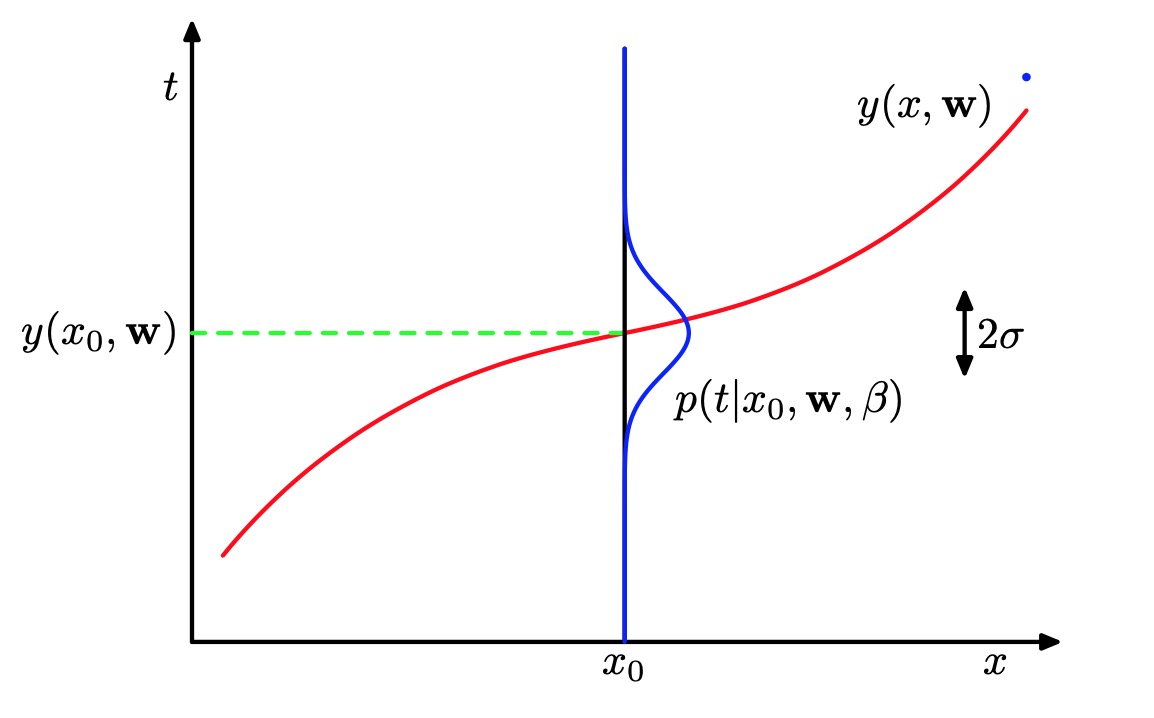
Schematic illustration of a Gaussian conditional distribution for t given x given by (1.2.25), in which the mean is given by the polynomial function , and the precision is given by the parameter , which is related to the variance by
We now use the training data to determine the values of the unknown parameters and by maximum likelihood. If the data are assumed to be drawn independently from the distribution (1.2.25), then the likelihood function is given by
Substituting for the form of the Gaussian distribution, given by (1.2.25), we obtain the log likelihood function in the form
Consider first the determination of the maximum likelihood solution for the polynomial coefficients, which will be denoted by . These are determined by maximizing (1.2.40) with respect to . For this purpose, we can omit the last two terms on the right-hand side of (1.2.40) because they do not depend on . Also, we note that scaling the log likelihood by a positive constant coefficient does not alter the location of the maximum with respect to , and so we can replace the coefficient β/2 with 1/2. Finally, instead of maximizing the log likelihood, we can equivalently minimize the negative log likelihood. We therefore see that maximizing likelihood is equivalent, so far as determining is concerned, to minimizing the sum-of-squares error function defined by (1.1.2). Thus the sum-of-squares error function has arisen as a consequence of maximizing likelihood under the assumption of a Gaussian noise distribution.
We can also use maximum likelihood to determine the precision parameter β of the Gaussian conditional distribution. Maximizing (1.2.40) with respect to β gives
Again we can first determine the parameter vector governing the mean and subsequently use this to find the precision as was the case for the simple Gaussian distribution.
Having determined the parameters and , we can now make predictions for new values of . Because we now have a probabilistic model, these are expressed in terms of the predictive distribution that gives the probability distribution over t, rather than simply a point estimate, and is obtained by substituting the maximum likelihood parameters into (1.2.38) to give
Now let us take a step towards a more Bayesian approach and introduce a prior distribution over the polynomial coefficients . For simplicity, let us consider a Gaussian distribution of the form
where is the precision of the distribution, and M +1 is the total number of elements in the vector for an order polynomial. Variables such as , which control the distribution of model parameters, are called hyperparameters. Using Bayes’ theorem, the posterior distribution for is proportional to the product of the prior distribution and the likelihood function
We can now determine by finding the most probable value of given the data, in other words by maximizing the posterior distribution. This technique is called maximum posterior, or simply MAP. Taking the negative logarithm of (1.2.44) and combining with (1.2.40) and (1.2.43), we find that the maximum of the posterior is given by the minimum of
Thus we see that maximizing the posterior distribution is equivalent to minimizing the regularized sum-of-squares error function encountered earlier in the form (1.1.4), with a regularization parameter given by .
Bayesian curve fitting
Although we have included a prior distribution , we are so far still making a point estimate of and so this does not yet amount to a Bayesian treatment. In a fully Bayesian approach, we should consistently apply the sum and product rules of probability, which requires, as we shall see shortly, that we integrate over all values of . Such marginalizations lie at the heart of Bayesian methods for pattern recognition.
In the curve fitting problem, we are given the training data and , along with a new test point , and our goal is to predict the value of . We therefore wish to evaluate the predictive distribution . Here we shall assume that the parameters and are fixed and known in advance (in later chapters we shall discuss how such parameters can be inferred from data in a Bayesian setting).
A Bayesian treatment simply corresponds to a consistent application of the sum and product rules of probability, which allow the predictive distribution to be written in the form
Here is given by (1.2.38), and we have omitted the dependence on and to simplify the notation.Here is the posterior distribution over param- eters, and can be found by normalizing the right-hand side of (1.2.44). We shall see that for problems such as the curve-fitting example, this posterior distribution is a Gaussian and can be evaluated analytically. Similarly, the integration in (1.2.46) can also be performed analytically with the result that the predictive distribution is given by a Gaussian of the form
where the mean and variance are given by
mean:
variance:
here the matrix S is given by
where is the unit matrix, and we have defined the vector with elements for .
We see that the variance, as well as the mean, of the predictive distribution in (1.2.46) is dependent on .
Model Selectioin
In our example of polynomial curve fitting using least squares, we saw that there was an optimal order of polynomial that gave the best generalization. The order of the polynomial controls the number of free parameters in the model and thereby governs the model complexity. With regularized least squares, the regularization coefficient also controls the effective complexity of the model, whereas for more complex models, such as mixture distributions or neural networks there may be multiple pa- rameters governing complexity. In a practical application, we need to determine the values of such parameters, and the principal objective in doing so is usually to achieve the best predictive performance on new data. Furthermore, as well as find- ing the appropriate values for complexity parameters within a given model, we may wish to consider a range of different types of model in order to find the best one for our particular application.
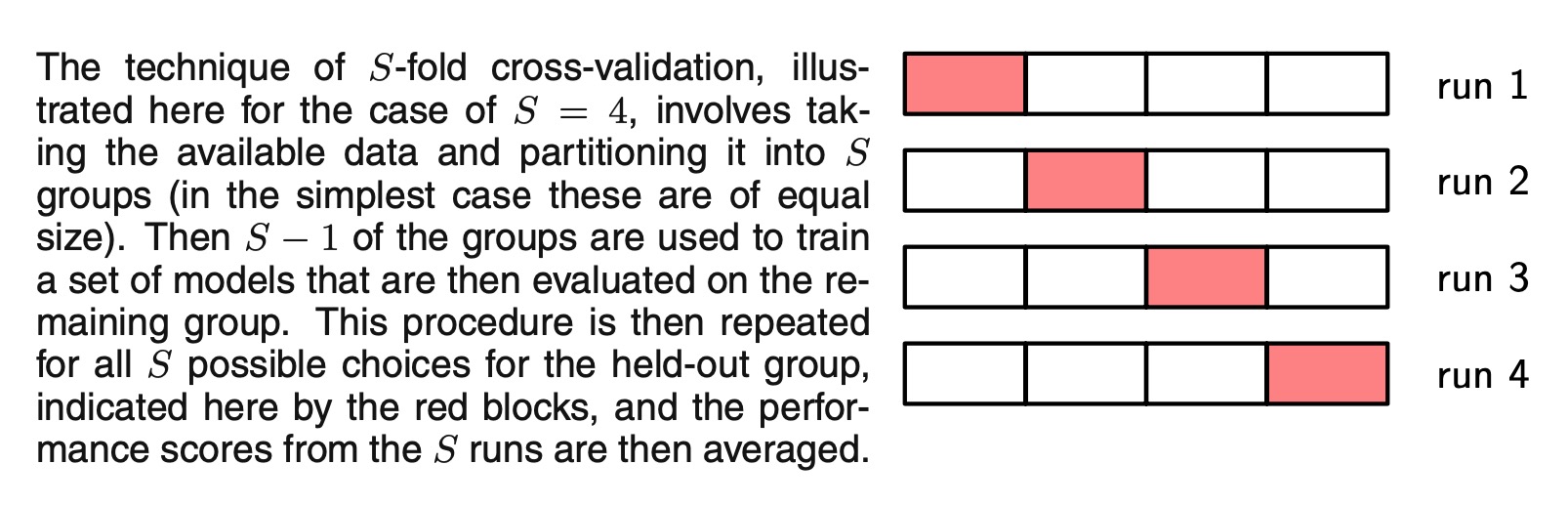
In many applications, however, the supply of data for training and testing will be limited, and in order to build good models, we wish to use as much of the available data as possible for training. However, if the validation set is small, it will give a relatively noisy estimate of predictive performance. One solution to this dilemma is to use cross-validation, which is illustrated as follow. This allows a proportion (S − 1)/S of the available data to be used for training while making use of all of the data to assess performance.When data is particularly scarce, it may be appropriate to consider the case S = N , where N is the total number of data points, which gives the leave-one-out technique.
The Curse of Dimensionality
In the polynomial curve fitting example we had just one input variable . For practical applications of pattern recognition, however, we will have to deal with spaces of high dimensionality comprising many input variables. As we now discuss, this poses some serious challenges and is an important factor influencing the design of pattern recognition techniques.
Decision Thory
We have seen that how probability theory provides us with a consistent mathematical framework for quantifying and manipulating uncertainty. Here we turn to a discussion of decision theory that, when combined with probability theory, allows us to make optimal decisions in situations involving uncertainty such as those encountered in pattern recognition.
Suppose we have an input vector together with a corresponding vector of target variables, and our goal is to predict given a new value for . For regression problems, will comprise continuous variables, whereas for classification problems it will represent class labels.The joint probability distribution provides a complete summary of the uncertainty associated with these variables.
Minimizing the misclassification rate
Suppose that our goal is simply to make as few misclassifications as possible. We need a rule that assigns each value of to one of the available classes. Such a rule will divide the input space into regions called decision regions, one for each class, such that all points in are assigned to class . The boundaries between decision regions are called decision boundaries or decision surfaces. Note that each decision region need not be contiguous but could comprise some number of disjoint regions.
For the more general case of K classes, it is slightly easier to maximize the probability of being correct, which is given by
which is maximized when the regions are chosen such that each is assigned to the class for which is largest.Again, using the product rule , and noting that the factor of is common to all terms, we see that each should be assigned to the class having the largest posterior probability .
Minimizing the expected loss
For many applications, our objective will be more complex than simply mini- mizing the number of misclassifications.
We can formalize classifier through the introduction of a loss function, also called a cost function, which is a single, overall measure of loss incurred in taking any of the available decisions or actions.Our goal is then to minimize the total loss incurred.
The optimal solution is the one which minimizes the loss function. However, the loss function depends on the true class, which is unknown. For a given input vector , our uncertainty in the true class is expressed through the joint probability distribution and so we seek instead to minimize the average loss, where the average is computed with respect to this distribution, which is given by
Each can be assigned independently to one of the decision regions .Our goal is to choose the regions in order to minimize the expected loss, which implies that for each we should minimize .As before, we can use the product rule to eliminate the common factor of p(x). Thus the decision rule that minimizes the expected loss is the one that assigns each new to the class for which the quantity is a minimum. This is clearly trivial to do, once we know the posterior class probabilities .
The reject option
We have seen that classification errors arise from the regions of input space where the largest of the posterior probabilities is significantly less than unity, or equivalently where the joint distributions have comparable values. In some applications, it will be appropriate to avoid making decisions on the difficult cases in anticipation of a lower error rate on those examples for which a classification decision is made. This is known as the reject option.
Inference and decision
We have broken the classification problem down into two separate stages
the inference stage in which we use training data to learn a model for
the decision stage in which we use these posterior probabilities to make op- timal class assignments.
To solving decision problems, find a function , called a discriminant function, which maps each input directly onto a class label. For instance, in the case of two-class problems, might be binary valued and such that represents class and represents class . In this case, probabilities play no role, we no longer have access to the posterior probabilities .There are many powerful reasons for wanting to compute the posterior probabilities, even if we subsequently use them to make decisions. These include:
- Minimizing risk.
Consider a problem in which the elements of the loss matrix are subjected to revision from time to time.If we know the posterior probabilities, we can trivially revise the minimum risk decision criterion by modifying appropriately.If we have only a discriminant function, then any change to the loss matrix would require that we return to the training data and solve the classification problem afresh - Rejectoption.
Posterior probabilities allow us to determine a rejection criterion that will minimize the misclassification rate, or more generally the expected loss, for a given fraction of rejected data points. - Compensating for class priors.
A balanced data set in which we have selected equal numbers of exam- ples from each of the classes would allow us to find a more accurate model. However, we then have to compensate for the effects of our modifications to the training data. Suppose we have used such a modified data set and found models for the posterior probabilities. From Bayes’ theorem, we see that the posterior probabilities are proportional to the prior probabilities, which we can interpret as the fractions of points in each class. We can therefore simply take the posterior probabilities obtained from our artificially balanced data set and first divide by the class fractions in that data set and then multiply by the class fractions in the population to which we wish to apply the model. Finally, we need to normalize to ensure that the new posterior probabilities sum to one. Note that this procedure cannot be applied if we have learned a discriminant function directly instead of determining posterior probabilities. - **Combining models. **
For complex applications, we may wish to break the problem into a number of smaller subproblems each of which can be tackled by a sep- arate module.
Loss functions for regression
So far, we have discussed decision theory in the context of classification prob- lems. We now turn to the case of regression problems, such as the curve fitting example discussed earlier. The decision stage consists of choosing a specific estimate of the value of for each input .Suppose that in doing so, we incur a loss . The average, or expected, loss is then given by
A common choice of loss function in regression problems is the squared loss given by . In this case, the expected loss can be written
Our goal is to choose y(x) so as to minimize . If we assume a completely flexible function , we can do this formally using the calculus of variations to give
Solving for , and using the sum and product rules of probability, we obtain
which is the conditional average of conditioned on and is known as the regression function.To multiple target variables represented by the vector , in which case the optimal solution is the conditional average .We can also derive this result in a slightly different way, which will also shed light on the nature of the regression problem. Armed with the knowledge that the optimal solution is the conditional expectation, we can expand the square term as follows
where, to keep the notation uncluttered, we use to denote .Substituting into the loss function and performing the integral over t, we see that the cross-term vanishes and we obtain an expression for the loss function in the form
The function we seek to determine enters only in the first term, which will be minimized when is equal to , in which case this term will vanish. This is simply the result that we derived previously and that shows that the optimal least squares predictor is given by the conditional mean. The second term is the variance of the distribution of , averaged over . It represents the intrinsic variability of the target data and can be regarded as noise. Because it is independent of , it represents the irreducible minimum value of the loss function.As with the classification problem, we can either determine the appropriate prob- abilities and then use these to make optimal decisions, or we can build models that make decisions directly. Indeed, we can identify three distinct approaches to solving regression problems given, in order of decreasing complexity,by
(a). First solve the inference problem of determining the joint density . Then normalize to find the conditional density , and finally marginalize to find the conditional mean given by (1.3.4)
(b). First solve the inference problem of determining the conditional density , and then subsequently marginalize to find the conditional mean given by (1.3.4)
©. Find a regression function directly from the training data.
The relative merits of these three approaches follow the same lines as for classifica- tion problems above.
The squared loss is not the only possible choice of loss function for regression. Indeed, there are situations in which squared loss can lead to very poor results and where we need to develop more sophisticated approaches. An important example concerns situations in which the conditional distribution is multimodal, as often arises in the solution of inverse problems. Here we consider briefly one simple generalization of the squared loss, called the Minkowski loss, whose expectation is given by
which reduces to the expected squared loss for .The minimum of is given by the conditional mean for , the conditional median for , and the conditional mode for .
Information Theory
n this chapter, we have discussed a variety of concepts from probability theory and decision theory that will form the foundations for much of the subsequent discussion in this book. We close this chapter by introducing some additional concepts from the field of information theory, which will also prove useful in our development of pattern recognition and machine learning techniques.
We begin by considering a discrete random variable and we ask how much information is received when we observe a specific value for this variable. The amount of information can be viewed as the ‘degree of surprise’ on learning the value of . If we are told that a highly improbable event has just occurred, we will have received more information than if we were told that some very likely event has just occurred, and if we knew that the event was certain to happen we would receive no information. Our measure of information content will therefore depend on the probability distribution , and we therefore look for a quantity that is a monotonic function of the probability and that expresses the information content. The form of can be found by noting that if we have two events and that are unrelated, then the information gain from observing both of them should be the sum of the information gained from each of them separately, so that . Two unrelated events will be statistically independent and so . From these two relationships, it is easily shown that must be given by the logarithm of and so we have
where the negative sign ensures that information is positive or zero.Note that low probability events x correspond to high information content. The choice of basis for the logarithm is arbitrary, and for the moment we shall adopt the convention prevalent in information theory of using logarithms to the base of 2.
Now suppose that a sender wishes to transmit the value of a random variable to a receiver. The average amount of information that they transmit in the process is obtained by taking the expectation of (1.4.1) with respect to the distribution and is given by
This important quantity is called the entropy of the random variable x.
Note that and so we shall take whenever we encounter a value for such that .
We now show that these definitions indeed possess useful properties. Consider a random variable x having 8 possible states, each of which is equally likely. In order to communicate the value of x to a receiver, we would need to transmit a message of length 3 bits. Notice that the entropy of this variable is given by
For a density defined over multiple continuous variables, denoted collectively by the vector , the differential entropy is given by
In the case of discrete distributions, we saw that the maximum entropy configuration corresponded to an equal distribution of probabilities across the possible states of the variable.Let us now consider the maximum entropy configuration for a continuous variable.
Omit the proof process, the distribution that maximizes the differential entropy is the Gaussian.If we evaluate the differential entropy of the Gaussian, we obtain
proof as follow
as prooved
for single variant
so
let , then
as , that and is symmetric in
thenfor multi-variant
if , with Mahalanobis transform let
then , that means is the normalization gaussion distribution
as
and
so
so
Suppose we have a joint distribution from which we draw pairs of values of and . If a value of is already known, then the additional information needed to specify the corresponding value of is given by . Thus the average additional information needed to specify can be written as
which is called the conditional entropy of given .
It is easily seen, using the product rule, that the conditional entropy satisfies the relation
where is the differential entropy of and is the differential entropy of the marginal distribution . Thus the information needed to describe and is given by the sum of the information needed to describe alone plus the additional information required to specify given .
Relative entropy and mutual information
So far in this section, we have introduced a number of concepts from information theory, including the key notion of entropy. We now start to relate these ideas to pattern recognition. Consider some unknown distribution , and suppose that we have modelled this using an approximating distribution . If we use to construct a coding scheme for the purpose of transmitting values of to a receiver, then the average additional amount of information (in nats) required to specify the value of (assuming we choose an efficient coding scheme) as a result of using instead of the true distribution is given by
This is known as the relative entropy or Kullback-Leibler divergence or KL divergence, between the distributions and .
Probability Distributions
We have emphasized the central role played by probability theory in the solution of pattern recognition problems. We turn now to an exploration of some particular examples of probability distributions and their properties. As well as being of great interest in their own right, these distributions can form building blocks for more complex models and will be used extensively throughout the entire. The distributions introduced in this part will also serve another important purpose, namely to provide us with the opportunity to discuss some key statistical concepts, such as Bayesian inference, in the context of simple models before we encounter them in more complex situations in later chapters.
Binary Variables
We begin by considering a single binary random variable . For example, might describe the outcome of flipping a coin, with representing ‘heads’, and representing ‘tails’. We can imagine that this is a damaged coin so that the probability of landing heads is not necessarily the same as that of landing tails. The probability of will be denoted by the parameter so that
where , from which it follows that . The probability distribution over x can therefore be written in the form
which is known as the Bernoulli distribution. It is easily verified that this distribution is normalized and that it has mean and variance given by
Now suppose we have a data set of observed values of . We can construct the likelihood function, which is a function of , on the assumption that the observations are drawn independently from , so that
In a frequentist setting, we can estimate a value for by maximizing the likelihood function, or equivalently by maximizing the logarithm of the likelihood. In the case of the Bernoulli distribution, the log likelihood function is given by
At this point, it is worth noting that the log likelihood function depends on the N observations only through their sum .This sum provides an example of a sufficient statistic for the data under this distribution, and we shall study the impor- tant role of sufficient statistics in some detail.If we set the derivative of ln with respect to equal to zero , we obtain the maximum likelihood estimator , which is also known as the sample mean. If we denote the number of observations of (heads) within this data set by , then we can write in the form . So that the probability of landing heads is given, in this maximum likelihood frame- work, by the fraction of observations of heads in the data set.
Now suppose we flip a coin, say, 3 times and happen to observe 3 heads. Then and . In this case, the maximum likelihood result would predict that all future observations should give heads. Common sense tells us that this is unreasonable, and in fact this is an extreme example of the over-fitting associated with maximum likelihood. We shall see shortly how to arrive at more sensible conclusions through the introduction of a prior distribution over .
We can also work out the distribution of the number m of observations of x = 1, given that the data set has size N. This is called the binomial distribution and that it is proportional to . In order to obtain the normalization coefficient we note that out of N coin flips, we have to add up all of the possible ways of obtaining m heads, so that the binomial distribution can be written is the number of ways of choosing m objects out of a total of N identical objects.
formal mean
formal variance
The beta distribution
We have seen that the maximum likelihood setting for the parameter in the Bernoulli distribution, and hence in the binomial distribution, is given by the fraction of the observations in the data set having . As we have already noted,
this can give severely over-fitted results for small data sets. In order to develop a Bayesian treatment for this problem, we need to introduce a prior distribution over the parameter .
Here we consider a form of prior distribution that has a simple interpretation as well as some useful analytical properties. To motivate this prior, we note that the likelihood function takes the form of the product of factors of the form .We choose a prior to be proportional to powers of and , then the posterior distribution, which is proportional to the product of the prior and the likelihood function, will have the same functional form as the prior. This property is called conjugacy. We therefore choose a prior, called the beta distribution, given by
Gamma Function . For the gamma function
where is the gamma function, and the coefficient in (2.1.5) ensures that the beta distribution is normalized, so that
The mean and variance of the beta distribution are given by
the mean:
the variance:
The parameters and are often called hyperparameters because they control the distribution of the parameter .
The posterior distribution of is now obtained by multiplying the beta prior (2.1.5) by the binomial likelihood function and normalizing. Keeping only the factors that depend on , we see that this posterior distribution has the form .where , and therefore corresponds to the number of ‘tails’ in the coin example.Indeed, it is simply another beta distribution, and its normalization coefficient can therefore be obtained by comparison with (2.1.5) to give
We see that the effect of observing a data set of observations of and observations of has been to increase the value of by , and the value of by , in going from the prior distribution to the posterior distribution.This allows us to provide a simple interpretation of the hyperparameters and in the prior as an effective number of observations of and , respectively. Note that and need not be integers.
If our goal is to predict, as best we can, the outcome of the next trial, then we must evaluate the predictive distribution of , given the observed data set . From the sum and product rules of probability, this takes the form
Using the result (2.1.7) for the posterior distribution , together with the result for the mean of the beta distribution, we obtain . which has a simple interpretation as the total fraction of observations (both real observations and fictitious prior observations) that correspond to .
Multinomial Variables
Binary variables can be used to describe quantities that can take one of two possible values. Often, however, we encounter discrete variables that can take on one of K possible mutually exclusive states.Although there are various alternative ways to express such variables, we shall see shortly that a particularly convenient representation is the 1-of-K scheme in which the variable is represented by a K-dimensional vector in which one of the elements equals 1, and all remaining elements equal 0. So, for instance if we have a variable that can take states and a particular observation of the variable happens to correspond to the state where , then x will be represented by . Note that such vectors satisfy . If we denote the probability of by the parameter , then the distribution of given
where , and the parameters are constrained to satisfy and
The distribution (2.2.1) can be regarded as a generalization of the Bernoulli distribution to more than two outcomes.
It is easily seen that the distribution is normalized
and that
Now consider a data set of independent observations . The corresponding likelihood function takes the form
We see that the likelihood function depends on the N data points only through the quantities . Which represent the number of observations of . These are called the sufficient statistics for this distribution.
In order to find the maximum likelihood solution for , we need to maximize with respect to taking account of the constraint that the must sum to 1. This can be achieved using a Lagrange multiplier and maximizing
Setting the derivative of (2.2.5) with respect to to zero , we obtain
We can solve for the Lagrange multiplier λ by substituting (2.2.6) into the constraint to to give , Thus we obtain the maximum likelihood solution in the form
which is the fraction of the N observations for which .
We can consider the joint distribution of the quantities , conditioned on the parameters and on the total number N of observations. From (2.2.4) this takes the form
which is known as the multinomial distribution.
Note that the variables are subject to the constraint
The Dirichlet distribution
We now introduce a family of prior distributions for the parameters {μk} of the multinomial distribution (2.2.7).By inspection of the form of the multinomial distribution, we see that the conjugate prior is given by
where and . Here are the parameters of the distribution, and denotes . Note that, because of the summation constraint, the distribution over the space of the is confined to a simplex of dimensionality K − 1. The normalized form for this distribution is by
which is called the Dirichlet distribution, and
Multiplying the prior (2.2.10) by the likelihood function (2.2.8), we obtain the posterior distribution for the parameters in the form
We see that the posterior distribution again takes the form of a Dirichlet distribution, confirming that the Dirichlet is indeed a conjugate prior for the multinomial. This allows us to determine the normalization coefficient by comparison with (2.2.10) so that
where we have denoted . As for the case of the binomial distribution with its beta prior, we can interpret the parameters αk of the Dirichlet prior as an effective number of observations of .
Note that two-state quantities can either be represented as binary variables and modelled using the binomial distribution or as 1-of-2 variables and modelled using the multinomial distribution(2.2.8) with K = 2
The Gaussian Distribution
The Gaussian, also known as the normal distribution, is a widely used model for the distribution of continuous variables. In the case of a single variable , the Gaussian distribution can be written in the form
where is the mean and is the variance. For a D-dimensional vector , the multivariate Gaussian distribution takes the form
where is a D-dimensional mean vector, Σ is a covariance matrix, and denotes the determinant of .
Deducing
For arbitrary , transform by , then we get
Consider the N indepedent variant, such as the N-dimentional column vector , corresponding variance is , with the product rule, we have that
For the exponent part, called the Mahalanobis distance from to and reduces to the Euclidean distance when is the identity matrix. , make the matrix transform, then
First of all, we note that the matrix can be taken to be symmetric, without loss of generality, because any antisymmetric component would disappear from the exponent. Now consider the eigenvector equation for the covariance matrix
where . Because is a real, symmetric matrix its eigenvalues will be real, and its eigenvectors can be chosen to form an orthonormal set, so that
where is the element of the identity matrix and satisfies
The covariance matrix can be expressed as an expansion in terms of its eigenvectors in the form
and similarly the inverse covariance matrix can be expressed as
Then the in the deducing part quadratic form becomes
where we have defined
we can interpret as a new coordinate system defined by the orthonormal vectors that are shifted and rotated with respect to the original coordinates. Forming the vector , we have
where U is a matrix whose rows are given by . From (2.3.4) it follows that U is an orthogonal matrix, i.e., it satisfies , and hence also , where I is the identity matrix.
The quadratic form, and hence the Gaussian density, will be constant on surfaces for which (2.3.9.0) is constant. If all of the eigenvalues are positive, then these surfaces represent ellipsoids, with their centres at and their axes oriented along , and with scaling factors in the directions of the axes given by
For the Gaussian distribution to be well defined, it is necessary for all of the eigenvalues of the covariance matrix to be strictly positive, otherwise the distribution cannot be properly normalized. A matrix whose eigenvalues are strictly positive is said to be positive definite. If all of the eigenvalues are nonnegative, then the covariance matrix is said to be positive semidefinite.
Now consider the form of the Gaussian distribution in the new coordinate system defined by the . In going from the x to the y coordinate system, we have a Jacobian matrix J with elements given by
where are the elements of the matrix . Using the orthonormality property of the matrix U, we see that the square of the determinant of the Jacobian matrix is
and hence = 1. Also, the determinant of the covariance matrix can be written as the product of its eigenvalues, and hence
Thus in the coordinate system, the Gaussian distribution takes the form
which is the product of D independent univariate Gaussian distributions. The eigenvectors therefore define a new set of shifted and rotated coordinates with respect to which the joint probability distribution factorizes into a product of independent distributions. The integral of the distribution in the y coordinate system is then
where we have used the result (1.2.26) for the normalization of the univariate Gaussian. This confirms that the multivariate Gaussian (2.3.2) is indeed normalized.
Linear Models for Regression
The focus so far in this book has been on unsupervised learning, including topics such as density estimation and data clustering. We turn now to a discussion of super- vised learning, starting with regression.
GOAL
The goal of regression is to predict the value of one or more continuous target variables t given the value of a D-dimensional vec- tor x of input variables.
The simplest form of linear regression models are also linear functions of the input variables. However, we can obtain a much more useful class of functions by taking linear combinations of a fixed set of nonlinear functions of the input variables, known as basis functions.Such models are linear functions of the parameters, which gives them simple analytical properties, and yet can be nonlinear with respect to the input variables.
Given a training data set comprising N observations , where n = 1, . . . , N , together with corresponding target values , the goal is to predict the value of for a new value of . In the simplest approach, this can be done by directly constructing an appropriate function whose values for new inputs constitute the predictions for the corresponding values of . More generally, from a probabilistic perspective, we aim to model the predictive distribution because this expresses our uncertainty about the value of for each value of .
Evaluation
Although linear models have significant limitations as practical techniques for pattern recognition, particularly for problems involving input spaces of high dimen- sionality, they have nice analytical properties and form the foundation for more sophisticated models to be discussed in later chapters.
Linear Basis Function Models
The simplest linear model for regression is one that involves a linear combination of the input variables
where . This is often simply known as linear regression.Thekey property of this model is that it is a linear function of the parameters . It is also, however, a linear function of the input variables , and this imposes significant limitations on the model. We therefore extend the class of models by considering linear combinations of fixed nonlinear functions of the input variables, of the form
where are known as basis functions. By denoting the maximum value of the index j by M − 1, the total number of parameters in this model will be M.
The parameter allows for any fixed offset in the data and is sometimes called a bias parameter.It is often convenient to define an additional dummy ‘basis function so that
where and .
By using nonlinear basis functions, we allow the function to be a nonlinear function of the input vector .
The example of polynomial regression is a particular example of this model in which there is a single input variable , and the basis functions take the form of powers of x so that . One limitation of polynomial basis functions is that they are global functions of the input variable, so that changes in one region of input space affect all other regions. This can be resolved by dividing the input space up into regions and fit a different polynomial in each region, leading to spline functions.
Basis Function Set
There are many other possible choices for the basis functions, for example
where the govern the locations of the basis functions in input space, and the parameter governs their spatial scale.
Another possibility is the sigmoidal basis function of the form
where is the logistic sigmoid function defined by
Yet another possible choice of basis function is the Fourier basis, which leads to an expansion in sinusoidal functions. Each basis function represents a specific fre- quency and has infinite spatial extent. By contrast, basis functions that are localized to finite regions of input space necessarily comprise a spectrum of different spatial frequencies.
In many signal processing applications, it is of interest to consider ba- sis functions that are localized in both space and frequency, leading to a class of functions known as wavelets.
Most of the discussion in this chapter, however, is independent of the particular choice of basis function set, and so for most of our discussion we shall not specify the particular form of the basis functions.
Maximum likelihood and least squares
As before, we assume that the target variable t is given by a deterministic function with additive Gaussian noise so that
where is a zero mean Gaussian random variable with precision (inverse variance) . Thus we can write
Recall that, if we assume a squared loss function, then the optimal prediction, for a new value of x, will be given by the conditional mean of the target variable. In the case of a Gaussian conditional distribution of the form (3.1.8), the conditional mean will be simply
Note that the Gaussian noise assumption implies that the conditional distribution of t given is unimodal, which may be inappropriate for some applications.
Now consider a data set of inputs with corresponding target values . We group the target variables into a column vector that we denote by where the typeface is chosen to distinguish it from a single observation of a multivariate target, which would be denoted . Making the assumption that these data points are drawn independently from the distribution (3.1.8), we obtain the following expression for the likelihood function, which is a function of the adjustable parameters and , in the form
Note that in supervised learning problems such as regression (and classification), we are not seeking to model the distribution of the input variables.Thus will always appear in the set of conditioning variables, and so from now on we will drop the explicit from expressions such as in order to keep the notation uncluttered.Taking the logarithm of the likelihood function, and making use of the standard form for the univariate Gaussian, we have
where the sum-of-squares error function is defined by
Having written down the likelihood function, we can use maximum likelihood to determine and .
Consider first the maximization with respect to . As observed already before, we see that maximization of the likelihood function under a conditional Gaussian noise distribution for a linear model is equivalent to minimizing a sum-of-squares error function given by . The gradient of the log likelihood function (3.1.11) takes the form
Setting this gradient to zero gives
Solving for w we obtain
which are known as the normal equations for the least squares problem. Here is an N×M matrix, called the design matrix, whose element are given by , so that
The quantity is known as the Moore-Penrose pseudo-inverse of the matrix
It can be regarded as a generalization of the notion of matrix inverse to nonsquare matrices. Indeed, if is square aninvertible, then using the property we seet hat .
At this point, we can gain some insight into the role of the bias parameter . If we make the bias parameter explicit, then the error function (3.1.12) becomes
Setting the derivative with respect to equal to zero,, and solving for , we obtain
where we have defined
Thus the bias compensates for the difference between the averages (over the training set) of the target values and the weighted sum of the averages of the basis function values.
We can also maximize the log likelihood function (3.1.11) with respect to the noise precision parameter , giving
and so we see that the inverse of the noise precision is given by the residual variance of the target values around the regression function.
Geometry of least squares
See more detail picture of the geometry of least squares with Bing.com
Sequential learning
Batch techniques, such as the maximum likelihood solution (3.1.15), which involve processing the entire training set in one go, can be computationally costly for large data sets .If the data set is sufficiently large, it may be worthwhile to use sequential algorithms, also known as on-line algorithms, in which the data points are considered one at a time, and the model parameters up- dated after each such presentation. Sequential learning is also appropriate for real- time applications in which the data observations are arriving in a continuous stream, and predictions must be made before all of the data points are seen.
SGD
We can obtain a sequential learning algorithm by applying the technique of stochastic gradient descent, also known as sequential gradient descent, as follows. If the error function comprises a sum over data points , then after presentation of pattern n, the stochastic gradient descent algorithm updates the parameter vector using
where denotes the iteration number and is a learning rate patameter. The value of is initialized to some starting vector . For the case of the sum-of-squares error function (3.12), this gives
where . This is known as least-mean-squares or the LMS algorithm. The value of needs to be chosen with care to ensure that the algorithm converges
Regularized least squares
We have introduced the idea of adding a regularization term to an error function in order to control over-fitting, so that the total error function to be minimized takes the form
where is the regularization coefficient that controls the relative importance of the data-dependent error and the regularization term . One of the sim- plest forms of regularizer is given by the sum-of-squares of the weight vector ele- ments
If we also consider the sum-of-squares error function given by (3.1.12), then the total error function becomes
weight decay
This particular choice of regularizer is known in the machine learning literature as weight decay because in sequential learning algorithms, it encourages weight values to decay towards zero, unless supported by the data. In statistics, it provides an example of a parameter shrinkage method because it shrinks parameter values towards zero.It has the advantage that the error function remains a quadratic function of w, and so its exact minimizer can be found in closed form.
Specifically, setting the gradient of (3.1.24) with respect to w to zero, , and solving for w as before, we obtain
This represents a simple extension of the least-squares solution (3.1.15).
A more general regularizer is sometimes used, for which the regularized error takes the form
where corresponds to the quadratic regularizer (3.1.24).
LASSO
The case of is know as the lasso in the statistics literature. It has the property that if is sufficiently large, some of the coefficients are driven to zero, leading to a sparse model in which the corresponding basis functions play no role. To see this, we first note that minimizing (3.26) is equivalent to minimizing the unregularized sum-of-squares error (3.1.12) subject to the constraint
for an appropriate value of the parameter η, where the two approaches can be related using Lagrange multipliers.
Here is the visualaztion of the pictures Regularization lasso Picture from Bing.com
Multiple outputs
So far, we have considered the case of a single target variable t. In some applications, we may wish to predict K > 1 target variables, which we denote collectively by the target vector . This could be done by introducing a different set of basis functions for each component of t, leading to multiple, independent regression problems. However, a more interesting, and more common, approach is to use the same set of basis functions to model all of the components of the target vector so that
The Bias-Variance Decomposition
So far in our discussion of linear models for regression, we have assumed that the form and number of basis functions are both fixed. As we have seen, the use of maximum likelihood, or equivalently least squares, can lead to severe over-fitting if complex models are trained using data sets of limited size. However, limiting the number of basis functions in order to avoid over-fitting has the side effect of limiting the flexibility of the model to capture interesting and important trends in the data. Although the introduction of regularization terms can control over-fitting for models with many parameters, this raises the question of how to determine a suitable value for the regularization coefficient .
Seeking the solution that minimizes the regularized error function with respect to both the weight vector and the regularization coefficient is clearly not the right approach since this leads to the unregularized solution with .
In Section 1.6.5, when we discussed decision theory for regression problems, we considered various loss functions each of which leads to a corresponding optimal prediction once we are given the conditional distribution . A popular choice is the squared loss function, for which the optimal prediction is given by the conditional expectation, which we denote by and which is given by
At this point, it is worth distinguishing between the squared loss function arising from decision theory and the sum-of-squares error function that arose in the maximum likelihood estimation of model parameters.
We showed in Section 1.6.5 that the expected squared loss can be written in the form
Recall that the second term, which is independent of , arises from the intrinsic noise on the data and represents the minimum achievable value of the expected loss.
The first term depends on our choice for the function , and we will seek a solution for which makes this term a minimum.Because it is nonnegative, the smallest that we can hope to make this term is zero. If we had an unlimited supply of data (and unlimited computational resources), we could in principle find the regression function to any desired degree of accuracy, and this would represent the optimal choice for . However, in practice we have a data set D containing only a finite number N of data points, and consequently we do not know the regression function exactly.
Expected Loss
If we model the using a parametric function governed by a parameter vector , then from a Bayesian perspective the uncertainty in our model is expressed through a posterior distribution over . A frequentist treatment, however, involves making a point estimate of based on the data set , and tries instead to interpret the uncertainty of this estimate through the following thought experiment. Suppose we had a large number of data sets each of size and each drawn independently from the distribution . For any given data set , we can run our learning algorithm and obtain a prediction function . Different data sets from the ensemble will give different functions and consequently different values of the squared loss. The performance of a particular learning algorithm is then assessed by taking the average over this ensemble of data sets.
We now take the expectation of this expression with respect to D and note that the final term will vanish, giving
We see that the expected squared difference between and the regression function can be expressed as the sum of two terms.
The first term, called the squared bias, represents the extent to which the average prediction over all data sets differs from the desired regression function.
The second term, called the variance, measures the extent to which the solutions for individual data sets vary around their average, and hence this measures the extent to which the function is sensitive to the particular choice of data set.
We shall provide some intuition to support these definitions shortly when we consider a simple example.
expected loss = (bias)2 + variance + noise
Bayesian Linear Regression
[TODO]
Bayesian Model Comparison
[TODO]
The Evidence Approximation
[TODO]
Limitations of Fixed Basis Functions
Throughout this chapter, we have focussed on models comprising a linear combina- tion of fixed, nonlinear basis functions. We have seen that the assumption of linearity in the parameters led to a range of useful properties including closed-form solutions to the least-squares problem, as well as a tractable Bayesian treatment. Furthermore, for a suitable choice of basis functions, we can model arbitrary nonlinearities in the mapping from input variables to targets.
However
The difficulty stems from the assumption that the basis functions are fixed before the training data set is observed and is a manifestation of the curse of dimen- sionality discussed in Section 1.5. As a consequence, the number of basis functions needs to grow rapidly, often exponentially, with the dimensionality D of the input space.
Linear Models for Classification
We have explored a class of regression models having particularly simple analytical and computational properties. We now discuss an analogous class of models for solving classification problems.
GOAL
The goal in classification is to take an input vector and to assign it to one of K discrete classes where . In the most common scenario, the classes are taken to be disjoint, so that each input is assigned to one and only one class. The input space is thereby divided into decision regions whose boundaries are called decision boundaries or decision surfaces. we consider linear models for classification, by which we mean that the decision surfaces are linear functions of the input vector x and hence are defined by (D − 1)-dimensional hyperplanes within the D-dimensional input space.
Data sets whose classes can be separated exactly by linear decision surfaces are said to be linearly separable.
In the case of classification, there are various ways of using target values to represent class labels.
In the linear regression models considered in Chapter 3, the model prediction was given by a linear function of the parameters . In the simplest case, the model is also linear in the input variables and therefore takes the form , so that y is a real number. For classification problems, however, we wish to predict discrete class labels, or more generally posterior probabilities that lie in the range (0, 1). To achieve this, we consider a generalization of this model in which we transform the linear function of using a nonlinear function so that
In the machine learning literature is known as an activation function, whereas its inverse is called a link function in the statistics literature.The decision surfaces correspond to , so that and hence the deci- sion surfaces are linear functions of , even if the function is nonlinear.
Discriminant Functions
A discriminant is a function that takes an input vector and assigns it to one of classes, denoted . In this chapter, we shall restrict attention to linear discriminants, namely those for which the decision surfaces are hyperplanes. To simplify the discussion, we consider first the case of two classes and then investigate the extension to K > 2 classes.
Two classes
The simplest representation of a linear discriminant function is obtained by tak- ing a linear function of the input vector so that
where is called a weight vector, and is a bias (not to be confused with bias in the statistical sense). The negative of the bias is sometimes called a threshold. An input vector is assigned to class if and to class otherwise. The corresponding decision boundary is therefore defined by the relation ,
Reduction
with point line on the decision surface. then
that means and , so
1: the vector is orthogonal to every vector lying within the decision surface, determines the orientation of the decision surface.
2: bias parameter determines the location of the decision surface.
Multiple classes
Considering a single K-class discriminant comprising K linear functions of the form and then assigning a point to class if for all . The decision boundary between class and class is therefore given by and hence corresponds to a (D − 1)-dimensional hyperplane defined by
This has the same form as the decision boundary for the two-class case discussed in Section 4.1.1, and so analogous geometrical properties apply.
Least squares for classification
Each class is described by its own linear model so that , where . We can conveniently group these together using vector notation so that
where is a matrix whose column comprises the D + 1-dimensional vector and is the corresponding augmented input vector with a dummy input = 1. A new input is then assigned to the class for which the output is largest.
We now determine the parameter matrix by minimizing a sum-of-squares error function.
if we use a 1-of-K coding scheme for K classes, then the predictions made by the model will have the property that the elements of y(x) will sum to 1 for any value of x. However, this summation constraint alone is not sufficient to allow the model outputs to be interpreted as probabilities because they are not constrained to lie within the interval (0, 1).
insufficient
The least-squares approach gives an exact closed-form solution for the discrimi- nant function parameters. However, even as a discriminant function (where we use it to make decisions directly and dispense with any probabilistic interpretation) it suf- fers from some severe problems. We have already seen that least-squares solutions lack robustness to outliers, and this applies equally to the classification application.
Why
The failure of least squares should not surprise us when we recall that it cor- responds to maximum likelihood under the assumption of a Gaussian conditional distribution, whereas binary target vectors clearly have a distribution that is far from Gaussian. By adopting more appropriate probabilistic models, we shall obtain clas- sification techniques with much better properties than least squares.
Fisher’s linear discriminant
Perspective
One way to view a linear classification model is in terms of dimensionality reduction.
suppose we take the D-dimensional input vector x and project it down to one dimension using
If we place a threshold on y and classify as class C1, and otherwise class C2, then we obtain our standard linear classifier discussed in the previous section.
In general, the projection onto one dimension leads to a considerable loss of infor- mation, and classes that are well separated in the original D-dimensional space may become strongly overlapping in one dimension.However, by adjusting the components of the weight vector , we can select a projection that maximizes the class separation.
To begin with, consider a two-class problem in which there are N1 points of class C1 and N2 points of class C2, so that the mean vectors of the two classes are given by
The simplest measure of the separation of the classes, when projected onto , is the separation of the projected class means. This suggests that we might choose so as to maximize
where is the mean of the projected data from class Ck.
Problems
However, this expression can be made arbitrarily large simply by increasing the magnitude of . To solve this problem, we could contrain to have unit length, so that
There is still a problem with this approach that two classes are well separated in the original twodimensional space but that have considerable overlap when projected onto the line joining their means.This difficulty arises from the strongly nondiagonal covariances of the class distributions. The idea proposed by Fisher is to maximize a function that will give a large separation between the projected class means while also giving a small variance within each class, thereby minimizing the class overlap.
The projection formula (4.1.2) transforms the set of labelled data points in into a labelled set in the one-dimensional space . The within-class variance of the transformed data from class Ck is therefore given by
where . We can define the total within-class variance for the whole data set to be simply . The Fisher criterion is defined to be the ratio of the between-class variance to he within-class variance and is given by
Relation to least squares
The least-squares approach to the determination of a linear discriminant was based on the goal of making the model predictions as close as possible to a set of target values. By contrast, the Fisher criterion was derived by requiring maximum class separation in the output space. It is interesting to see the relationship between these two approaches. In particular, we shall show that, for the two-class problem, the Fisher criterion can be obtained as a special case of least squares.
So far we have considered 1-of-K coding for the target values. If, however, we adopt a slightly different target coding scheme, then the least-squares solution for the weights becomes equivalent to the Fisher solution.
Fisher’s discriminant for multiple classes
We now consider the generalization of the Fisher discriminant to K > 2 classes, and we shall assume that the dimensionality D of the input space is greater than the number K of classes.
These feature values can conveniently be grouped together to form a vector . Similarly, the weight vectors can be considered to be the columns of a matrix W, so that
Note that again we are not including any bias parameters in the definition of . The generalization of the within-class covariance matrix to the case of K classes follows
where
and is the number of patterns in class Ck.
The perceptron algorithm
Another example of a linear discriminant model is the perceptron of Rosenblatt (1962), which occupies an important place in the history of pattern recognition algorithms.It corresponds to a two-class model in which the input vector x is first transformed using a fixed nonlinear transformation to give a feature vector , and this is then used to construct a generalized linear model of the form
where the nonlinear activation function is given by a step function of the form
The vector will typically include a bias component . In earlier discussions of two-class classification problems, we have focussed on a target coding scheme in which , which is appropriate in the context of probabilistic models. For the perceptron, however, it is more convenient to use target values for class C1 and for class C2, which matches the choice of activation function.
The algorithm used to determine the parameters w of the perceptron can most easily be motivated by error function minimization. A natural choice of error func- tion would be the total number of misclassified patterns. However, this does not lead to a simple learning algorithm because the error is a piecewise constant function of w, with discontinuities wherever a change in w causes the decision boundary to move across one of the data points. Methods based on changing w using the gradi- ent of the error function cannot then be applied, because the gradient is zero almost everywhere.
We therefore consider an alternative error function known as the perceptron criterion. To derive this, we note that we are seeking a weight vector such that patterns in class C1 will have , whereas patterns in class C2 have . Using the target coding scheme it follows that we would like all patterns to satisfy . The perceptron criterion associates zero error with any pattern that is correctly classified, whereas for a misclassified pattern it tries to minimize the quantity . The perceptron criterion is therefore given by
where denotes the set of all misclassified patterns. The contribution to the error associated with a particular misclassified pattern is a linear function of in regions of space where the pattern is misclassified and zero in regions where it is correctly classified. The total error function is therefore piecewise linear.
We now apply the stochastic gradient descent algorithm to this error function. The change in the weight vector w is then given by
where is the learning rate parameter and is an integer that indexes the steps of the algorithm.
Probabilistic Generative Models
We turn next to a probabilistic view of classification and show how models with linear decision boundaries arise from simple assumptions about the distribution of the data.
Here we shall adopt a generative approach in which we model the class-conditional densities , as well as the class priors , and then use these to compute posterior probabilities through Bayes’ theorem.
Continuous inputs
Let us assume that the class-conditional densities are Gaussian and then explore the resulting form for the posterior probabilities. To start with, we shall assume that all classes share the same covariance matrix.
Maximum likelihood solution
Once we have specified a parametric functional form for the class-conditional densities , we can then determine the values of the parameters, together with the prior class probabilities , using maximum likelihood. This requires a data set comprising observations of along with their corresponding class labels.
Insufficient
This result is easily extended to the K class problem to obtain the corresponding maximum likelihood solutions for the parameters in which each class-conditional density is Gaussian with a shared covariance matrix. Note that the approach of fitting Gaussian distributions to the classes is not robust to outliers, because the maximum likelihood estimation of a Gaussian is not robust.
Discrete features
[Skip]
Exponential family
[Skip]
Probabilistic Discriminative Models
Softmax Transformation
For the two-class classification problem, we have seen that the posterior probability of class C1 can be written as a logistic sigmoid acting on a linear function of x, for a wide choice of class-conditional distributions . Similarly, for the multiclass case, the posterior probability of class Ck is given by a softmax transformation of a linear function of x. For specific choices of the class-conditional densities , we have used maximum likelihood to determine the parameters of the densities as well as the class priors and then used Bayes’ theorem to find the posterior class probabilities.
However, an alternative approach is to use the functional form of the generalized linear model explicitly and to determine its parameters directly by using maximum likelihood. We shall see that there is an efficient algorithm finding such solutions known as iterative reweighted least squares, or IRLS.
Fixed basis functions
[Skip]
Logistic regression
We begin our treatment of generalized linear models by considering the problem of two-class classification. In our discussion of generative approaches in Section 4.2, we saw that under rather general assumptions, the posterior probability of class C1 can be written as a logistic sigmoid acting on a linear function of the feature vector so that
with
Here is the logistic sigmoid function. In the terminology of statistics, this model is known as logistic regression, although it should be emphasized that this is a model for classification rather than regression.
For an M-dimensional feature space , this model has M adjustable parameters. By contrast, if we had fitted Gaussian class conditional densities using maximum likelihood, we would have used 2M parameters for the means and M(M + 1)/2 parameters for the (shared) covariance matrix. Together with the class prior , this gives a total of M (M + 5)/2 + 1 parameters, which grows quadratically with M , in contrast to the linear dependence on M of the number of parameters in logistic regression. For large values of M, there is a clear advantage in working with the logistic regression model directly.
Logistic Maximum Likelihoo
We now use maximum likelihood to determine the parameters of the logistic regression model. To do this, we shall make use of the derivative of the logistic sig- moid function, which can conveniently be expressed in terms of the sigmoid function itself
For a data set , where and , with n = , the likelihood function can be written
where and . As usual, we can define an error function by taking the negative logarithm of the likelihood, which gives the cross- entropy error function in the form
where and .Taking the gradient of the error function with respect to , , we obtain
where we have made use of (4.3.3.0). We see that the factor involving the derivative of the logistic sigmoid has cancelled, leading to a simplified form for the gradient of the log likelihood. In particular, the contribution to the gradient from data point n is given by the ‘error’ between the target value and the prediction of the model, times the basis function vector . Furthermore, comparison with (3.1.13) shows that this takes precisely the same form as the gradient of the sum-of-squares error function for the linear regression model.
data sets that are linearly separable and
It is worth noting that maximum likelihood can exhibit severe over-fitting for data sets that are linearly separable. This arises because the maximum likelihood so- lution occurs when the hyperplane corresponding to , equivalent to , separates the two classes and the magnitude of goes to infinity.
In this case, the logistic sigmoid function becomes infinitely steep in feature space, corresponding to a Heaviside step function, so that every training point from each class k is assigned a posterior probability .
Furthermore, there is typically a continuum of such solutions because any separating hyperplane will give rise to the same pos- terior probabilities at the training data points. Maximum likelihood provides no way to favour one such solution over another, and which solution is found in practice will depend on the choice of optimization algorithm and on the parameter initialization. Note that the problem will arise even if the number of data points is large compared with the number of parameters in the model, so long as the training data set is linearly separable. The singularity can be avoided by inclusion of a prior and finding a MAP solution for , or equivalently by adding a regularization term to the error function.
Iterative reweighted least squares
For logistic regression, there is no longer a closed-form solution, due to the nonlinearity of the logistic sigmoid function. However, the departure from a quadratic form is not substantial. To be precise, the error function is concave, as we shall see shortly, and hence has a unique minimum. Furthermore, the error function can be minimized by an efficient iterative technique based on the Newton-Raphson iterative optimization scheme, which uses a local quadratic approximation to the log likelihood function.
where H is the Hessian matrix whose elements comprise the second derivatives of with respect to the components of .
Let us first of all apply the Newton-Raphson method to the linear regression model with the sum-of-squares error function The gradient and Hessian of this error function are given by
where is the N × M design matrix, whose row is given by . The Newton-Raphson update then takes the form
which we recognize as the standard least-squares solution. Note that the error func- tion in this case is quadratic and hence the Newton-Raphson formula gives the exact solution in one step.
Now let us apply the Newton-Raphson update to the cross-entropy error function (4.3.4) or the logistic regression model. From (4.3.5) we see that the gradient and Hessian of this error function are given by
where we have made use of (4.3.3.0). Also, we have introduced the N × N diagonal matrix R with elements
We see that the Hessian is no longer constant but depends on through the weighting matrix R, corresponding to the fact that the error function is no longer quadratic. Using the property , which follows from the form of the logistic sigmoid function, we see that for an arbitrary vector , and so the Hessian matrix H is positive definite. It follows that the error function is a concave function of w and hence has a unique minimum.
The Newton-Raphson update formula for the logistic regression model then becomes
where z is an N-dimensional vector with elements
**IRLS: iterative reweighted least squares **
We see that the update formula (4.3.12) takes the form of a set of normal equations for a weighted least-squares problem. Because the weighing matrix R is not constant but depends on the parameter vector w, we must apply the normal equations iteratively, each time using the new weight vector w to compute a revised weighing matrix R. For this reason, the algorithm is known as iterative reweighted least squares, or IRLS (Rubin, 1983). As in the weighted least-squares problem, the elements of the diagonal weighting matrix R can be interpreted as variances because the mean and variance of t in the logistic regression model are given by
where we have used the property .In fact, we can interpret IRLS as the solution to a linearized problem in the space of the variable .The quantity , which corresponds to the element of , can then be given a simple interpretation as an effective target value in this space obtained by making a local linear approximation to the logistic sigmoid function around the current operating point
Multiclass logistic regression
In our discussion of generative models for multiclass classification, we have seen that for a large class of distributions, the posterior probabilities are given by a softmax transformation of linear functions of the feature variables, so that
where the ‘activations’ ak are given by
There we used maximum likelihood to determine separately the class-conditional densities and the class priors and then found the corresponding posterior probabilities using Bayes’ theorem, thereby implicitly determining the parameters . Here we consider the use of maximum likelihood to determine the parameters of this model directly. To do this, we will require the derivatives of with respect to all of the activations . These are given by
where are the elements of the identity matrix.
The likelihood function is then given by
where , and T is an N × K matrix of target variables with elements . Taking the negative logarithm then gives
which is known as the cross-entropy error function for the multiclass classification problem.
We now take the gradient of the error function with respect to one of the parameter vectors . Making use of the result (4.3.15.1) for the derivatives of the softmax function, we obtain
where we have made use of .
Once again, we see the same form arising for the gradient as was found for the sum-of-squares error function with the linear model and the cross-entropy error for the logistic regression model, namely the prod- uct of the error times the basis function . Again, we could use this to formulate a sequential algorithm in which patterns are presented one at a time, in which each of the weight vectors is updated using (3.1.20).
We have seen that the derivative of the log likelihood function for a linear regression model with respect to the parameter vector for a data point n took the form of the ‘error’ times the feature vector . Similarly, for the combination of logistic sigmoid activation function and cross-entropy error function (4.3.4), and for the softmax activation function with the multiclass cross-entropy error function (4.3.17), we again obtain this same simple form.
To find a batch algorithm, we again appeal to the Newton-Raphson update to obtain the corresponding IRLS algorithm for the multiclass problem. This requires evaluation of the Hessian matrix that comprises blocks of size M × M in which block j, k is given by
As with the two-class problem, the Hessian matrix for the multiclass logistic regres- sion model is positive definite and so the error function again has a unique minimum. Practical details of IRLS for the multiclass case can be found in Bishop and Nabney (2008).
Probit regression
[skip]
Canonical link functions
COMPARE
For the linear regression model with a Gaussian noise distribution, the error function, corresponding to the negative log likelihood, is given by (3.1.12). If we take the derivative with respect to the parameter vector of the contribution to the error function from a data point n, this takes the form of the ‘error’ times the feature vector , where .
Similarly, for the combination of the logistic sigmoid activation function and the cross-entropy error function (4.3.4), and for the softmax activation function with the multiclass cross-entropy error function (4.3.17), we again obtain this same simple form. We now show that this is a general result of assuming a conditional distribution for the target variable from the exponential family, along with a corresponding choice for the activation function known as the canonical link function.
[TODO]
finish the proof for the general graident of the error function.
The Laplace Approximation
In Section 4.5 we shall discuss the Bayesian treatment of logistic regression.
As we shall see, this is more complex than the Bayesian treatment of linear regression models, discussed in Sections 3.3 and 3.5. In particular, we cannot integrate exactly over the parameter vector since the posterior distribution is no longer Gaussian.
It is therefore necessary to introduce some form of approximation.
Later in the book we shall consider a range of techniques based on analytical approximations and numerical sampling.
Here we introduce a simple, but widely used, framework called the Laplace ap- proximation, that aims to find a Gaussian approximation to a probability density defined over a set of continuous variables.
Bayesian Logistic Regression
[Skip]
Neural Networks
We considered models for regression and classification that com- prised linear combinations of fixed basis functions. We saw that such models have useful analytical and computational properties but that their practical applicability was limited by the curse of dimensionality.
In order to apply such models to large- scale problems, it is necessary to adapt the basis functions to the data.
SVM
Support vector machines (SVMs) address this by first defining basis functions that are centred on the training data points and then selecting a subset of these during training. One advantage of SVMs is that, although the training involves nonlinear optimization, the objective function is convex, and so the solution of the optimization problem is relatively straightforward.
The number of basis functions in the resulting models is generally much smaller than the number of training points, although it is often still relatively large and typically increases with the size of the training set.
multilayer perceptron
An alternative approach is to fix the number of basis functions in advance but allow them to be adaptive, in other words to use parametric forms for the basis func- tions in which the parameter values are adapted during training.
The most successful model of this type in the context of pattern recognition is the feed-forward neural network, also known as the multilayer perceptron.
In fact, ‘multilayer perceptron’ is really a misnomer, because the model comprises multi- ple layers of logistic regression models (with continuous nonlinearities) rather than multiple perceptrons (with discontinuous nonlinearities).
VS Support Vector Machine
For many applications, the resulting model can be significantly more compact, and hence faster to evaluate, than a support vector machine having the same generalization performance.
We begin by considering the functional form of the network model, including the specific parameterization of the basis functions, and we then discuss the prob- lem of determining the network parameters within a maximum likelihood frame- work, which involves the solution of a nonlinear optimization problem.
This requires the evaluation of derivatives of the log likelihood function with respect to the net- work parameters.
1.we shall see how these can be obtained efficiently using the technique of error backpropagation.
2.We shall also show how the backpropagation framework can be extended to allow other derivatives to be evaluated, such as the Jacobian and Hessian matrices.
3. Next we discuss various approaches to regularization of neural network training and the relationships between them.
Feed-forward Network Functions
The linear models for regression and classification are based on linear combinations of fixed nonlinear basis functions and take the form
where is a nonlinear activation function in the case of classification and is the identity in the case of regression.
GOAL
Our goal is to extend this model by making the basis functions depend on parameters and then to allow these parameters to be adjusted, along with the coefficients , during training.
Neural networks use basis functions that follow the same form as (5.1.1), so that each basis function is itself a nonlinear function of a linear combination of the inputs, where the coefficients in the linear combination are adaptive parameters.
This leads to the basic neural network model, which can be described a series of functional transformations. First we construct M linear combinations of the input variables intheform
where and the superscript (1) indicates that the correspoding parameters are in the first layer of the network.We shall refer to the parameters as weights and the paramters as biases. The quantities are known as activations. Each of them is then transformed using a differentiable, nonlinear activation function to give
These quantities correspond to the outputs of the basis functions in (5.1.1) that, in the context of neural networks, are called hidden units. The nonlinear functions are generally chosen to be sigmoidal functions such as the logistic sigmoid or the ‘tanh’ function. These values are again linearly combined to give output unit activations
where , and K is the total number of outputs. This transformation corresponds to the second layer of the network.
Finally, the output unit activations are transformed using an appropriate activation function to give a set of network outputs . The choice of activation function is determined by the nature of the data and the assumed distribution of target variables and follows the same considerations as for linear models.
Thus for standard regression problems, the activation function is the identity so that . Similarly, for multiple binary classification problems, each output unit activation is transformed using a logistic sigmoid function so that
We can combine these various stages to give the overall network function that, for sigmoidal output unit activation functions, takes the form
where the set of all weight and bias parameters have been grouped together into a vector .
Thus the neural network model is simply a nonlinear function from a set of input variables to a set of output variables controlled by a vector of adjustable parameters.
The process of evaluating (5.1.6) can then be interpreted as a forward propagation of information through the network.
As discussed in Section 3.1, the bias parameters in (5.1.2) can be absorbed into the set of weight parameters by defining an additional input variable whose value is clamped at , so that (5.1.2) takes the form
We can similarly absorb the second-layer biases into the second-layer weights, so that the overall network function becomes
Skip-layer Connections
A generalization of the network architecture is to include skip-layer connections, each of which is associated with a corresponding adaptive parameter. For in a two-layer network these would go directly from inputs to outputs. In principle, a network with sigmoidal hidden units can always mimic skip layer con- nections (for bounded input values) by using a sufficiently small first-layer weight that, over its operating range, the hidden unit is effectively linear, and then com- pensating with a large weight value from the hidden unit to the output. In practice, however, it may be advantageous to include skip-layer connections explicitly.
Furthermore, the network can be sparse, with not all possible connections within a layer being present.
Because there is a direct correspondence between a network diagram and its mathematical function, we can develop more general network mappings by con- sidering more complex network diagrams. However, these must be restricted to a feed-forward architecture, in other words to one having no closed directed cycles, to ensure that the outputs are deterministic functions of the inputs.
Neural Network VS Multilayer Perceptron
The neural network is also known as the multilayer perceptron, or MLP. A key difference compared to the perceptron, however, is that the neural net- work uses continuous sigmoidal nonlinearities in the hidden units, whereas the per- ceptron uses step-function nonlinearities. This means that the neural network func- tion is differentiable with respect to the network parameters, and this property will play a central role in network training.
If the activation functions of all the hidden units in a network are taken to be linear, then for any such network we can always find an equivalent network without hidden units. This follows from the fact that the composition of successive linear transformations is itself a linear transformation. However, if the number of hidden units is smaller than either the number of input or output units, then the transforma- tions that the network can generate are not the most general possible linear trans- formations from inputs to outputs because information is lost in the dimensionality reduction at the hidden units. Each (hidden or output) unit in such a network computes a function given by
where the sum runs over all units that send connections to unit (and a bias parameter is included in the summation). For a given set of values applied to the inputs of the network, successive application of (5.1.9) allows the activations of all units in the network to be evaluated including those of the output units.
Weight-space symmetries
[Skip]
Network Training
So far, we have viewed neural networks as a general class of parametric nonlinear functions from a vector x of input variables to a vector y of output variables. A simple approach to the problem of determining the network parameters is to make an analogy with the discussion of polynomial curve fitting in Section 1.1, and therefore to minimize a sum-of-squares error function. Given a training set comprising a set of input vectors , where n = 1,…,N, together with a corresponding set of target vectors , we minimize the error function
Parameter optimization
We turn next to the task of finding a weight vector w which minimizes the chosen function . At this point, it is useful to have a geometrical picture of the error function, which we can view as a surface sitting over weight space as shown follow
First note that if we make a small step in weight space from to then the change in the error function is , where the vector points in the direction of greatest rate of increase of the error function. Because the error is a smooth continuous function of , its smallest value will occur at a point in weight space such that the gradient of the error function vanishes, so that
as otherwise we could make a small step in the direction of and thereby further reduce the error. Points at which the gradient vanishes are called stationary points, and may be further classified into minima, maxima, and saddle points.
Our goal is to find a vector w such that takes its smallest value. However, the error function typically has a highly nonlinear dependence on the weights and bias parameters, and so there will be many points in weight space at which the gradient vanishes (or is numerically very small). Indeed, from the discussion in Section 5.1.1 we see that for any point that is a local minimum, there will be other points in weight space that are equivalent minima. For instance, in a two-layer network with M hidden units, each point in weight space is a member of a family of equivalent points.
Furthermore, there will typically be multiple inequivalent stationary points and in particular multiple inequivalent minima. A minimum that corresponds to the smallest value of the error function for any weight vector is said to be a global minimum. Any other minima corresponding to higher values of the error function are said to be local minima. For a successful application of neural networks, it may not be necessary to find the global minimum (and in general it will not be known whether the global minimum has been found) but it may be necessary to compare several local minima in order to find a sufficiently good solution.
Because there is clearly no hope of finding an analytical solution to the equation we resort to iterative numerical procedures. The optimization of continuous nonlinear functions is a widely studied problem and there exists an extensive literature on how to solve it efficiently. Most techniques involve choosing some initial value for the weight vector and then moving through weight space in a succession of steps of the form
Different algorithms involve different choices for the weight vector update .
Many algorithms make use of gradient information and therefore require that, after each update, the value of is evaluated at the new weight
. In order to understand the importance of gradient information, it is useful to consider a local approximation to the error function based on a Taylor expansion.
Local quadratic approximation
Insight into the optimization problem, and into the various techniques for solving it, can be obtained by considering a local quadratic approximation to the error function.
Consider the Taylor expansion of around some point in weight space
where cubic and higher terms have been omitted. Here is defined to be the gradient of evaluated at
and the Hessian matrix has elements
From (5.2.2), the corresponding local approximation to the gradient is given by
For points that are sufficiently close to , these expressions will give reasonable approximations for the error and its gradient.
Consider the particular case of a local quadratic approximation around a point that is a minimum of the error function. In this case there is no linear term. As at , and (5.2.2) becomes
where the Hessian H is evaluated at . In order to interpret this geometrically, consider the eigenvalue equation for the Hessian matrix
where the eigenvectors form a complete orthonormal set so that .
We now expand as a linear combination of the eigenvectors in the form
This can be regarded as a transformation of the coordinate system in which the origin is translated to the point , and the axes are rotated to align with the eigenvectors. Then the error function to be written in the form
A matrix H is said to be positive definite if, and only if
Because the eigenvectors form a complete set, an arbitrary vector can be written in the form
then we have
and so H will be positive definite if, and only if, all of its eigenvalues are positive. In the new coordinate system, whose basis vectors are given by the eigenvectors , the contours of constant E are ellipses centred on the origin, as illustrated in follow. For a one-dimensional weight space, a stationary point w will be a minimum if
The corresponding result in D-dimensions is that the Hessian matrix, evaluated at , should be positive definite.
Use of gradient information
As we shall see in Section 5.3, it is possible to evaluate the gradient of an error function efficiently by means of the backpropagation procedure. The use of this gradient information can lead to significant improvements in the speed with which the minima of the error function can be located. We can see why this is so, as follows.
In the quadratic approximation to the error function the error surface is specified by the quantities b and H, which contain a total of independent elements (because the matrix H is symmetric), where is the dimensionality of (i.e., the total number of adaptive parameters in the network). The location of the minimum of this quadratic approximation therefore depends on parameters, and we should not expect to be able to locate the minimum until we have gathered independent pieces of information. If we do not make use of gradient information, we would expect to have to perform function evaluations, each of which would require steps. Thus, the computational effort needed to find the minimum using such an approach would be .
Now compare this with an algorithm that makes use of the gradient information. Because each evaluation of brings items of information, we might hope to find the minimum of the function in gradient evaluations. As we shall see, by using error backpropagation, each such evaluation takes only steps and so the minimum can now be found in steps. For this reason, the use of gradient information forms the basis of practical algorithms for training neural networks.
Gradient descent optimization
The simplest approach to using gradient information is to choose the weight update in (5.2.2.0) to comprise a small step in the direction of the negative gradient, so that
where the parameter is known as the learning rate.
After each such update, the gradient is re-evaluated for the new weight vector and the process repeated.
Note that the error function is defined with respect to a training set, and so each step requires that the entire training set be processed in order to evaluate .Techniques that use the whole data set at once are called batch methods. At each step the weight vector is moved in the direction of the greatest rate of decrease of the error function, and so this approach is known as gradient descent or steepest descent. Although such an approach might intuitively seem reasonable, in fact it turns out to be a poor algorithm, for reasons discussed in Bishop and Nabney (2008).
Error Backpropagation
Our goal in this section is to find an efficient technique for evaluating the gradient of an error function for a feed-forward neural network. We shall see that this can be achieved using a local message passing scheme in which information is sent alternately forwards and backwards through the network and is known as error backpropagation, or sometimes simply as backprop.
Evaluation of error-function derivatives
We now derive the backpropagation algorithm for a general network having ar- bitrary feed-forward topology, arbitrary differentiable nonlinear activation functions, and a broad class of error function. The resulting formulae will then be illustrated using a simple layered network structure having a single layer of sigmoidal hidden units together with a sum-of-squares error.
Many error functions of practical interest, for instance those defined by maxi- mum likelihood for a set of i.i.d. data, comprise a sum of terms, one for each data point in the training set, so that
Here we shall consider the problem of evaluating for one such term in the error function. This may be used directly for sequential optimization, or the results can be accumulated over the training set in the case of batch methods.
Consider first a simple linear model in which the outputs are linear combinations of the input variables so that
together with an error function that, for a particular input pattern n, takes the form
where , The gradient of this error function with respect to a weight is given by
which can be interpreted as a ‘local’ computation involving the product of an ‘error signal’ associated with the output end of the link and the variable xni associated with the input end of the link. In Section 4.3.2, we saw how a similar formula arises with the logistic sigmoid activation function together with the cross entropy error function, and similarly for the softmax activation function together with its matching cross-entropy error function.We shall now see how this simple result extends to the more complex setting of multilayer feed-forward networks.
In a general feed-forward network, each unit computes a weighted sum of its inputs of the form
where is the activation of a unit, or input, that sends a connection to unit , and is the weight associated with that connection.In Section 5.1, we saw that biases can be included in this sum by introducing an extra unit, or input, with activation fixed at +1.We therefore do not need to deal with biases explicitly. The sum in (5.3.5) is transformed by a nonlinear activation function to give the activation of unit in the form
Note that one or more of the variables in the sum in (5.3.5) could be an input, and similarly, the unit in (5.3.6) could be an output.
For each pattern in the training set, we shall suppose that we have supplied the corresponding input vector to the network and calculated the activations of all of the hidden and output units in the network by successive application of (5.3.5) and (5.3.6). This process is often called forward propagation because it can be regarded as a forward flow of information through the network.
Now consider the evaluation of the derivative of with respect to a weight . The outputs of the various units will depend on the particular input pattern n. However, in order to keep the notation uncluttered, we shall omit the subscript n from the network variables. First we note that depends on the weight only via the summed input to unit . We can therefore apply the chain rule for partial derivatives to give
We now introduce a useful notation
where the are often referred to as errors for reasons we shall see shortly. (5.3.5), we can write
with above, we then obtain
Equation (5.3.10) tells us that the required derivative is obtained simply by multiplying the value of for the unit at the output end of the weight by the value of z for the unit at the input end of the weight (where z = 1 in the case of a bias). Note that this takes the same form as for the simple linear model considered at the start of this section. Thus, in order to evaluate the derivatives, we need only to calculate the value of δj for each hidden and output unit in the network, and then apply (5.3.10).
As we have seen already, for the output units, we have
provided we are using the canonical link as the output-unit activation function. To evaluate the for hidden units, we again make use of the chain rule for partial derivatives
where the sum runs over all units to which unit sends connections. The arrangement of units and weights is illustrated as follow.

Note that the units labelled k could include other hidden units and/or output units. In writing down (5.3.12), we are making use of the fact that variations in give rise to variations in the error function only through variations in the variables .
backpropagation formula
If we now substitute the definition of given by (5.3.8) into (5.3.12), and make use of (5.3.5) and (5.3.6), we obtain the following backpropagation formula
which tells us that the value of for a particular hidden unit can be obtained by propagating the backwards from units higher up in the network
Note that the summation in (5.3.13) is taken over the first index on (corresponding to backward propagation of information through the network), whereas in the forward propagation equation (5.1.9) it is taken over the second index. Because we already know the values of the for the output units, it follows that by recursively applying (5.3.13) we can evaluate the for all of the hidden units in a feed-forward network, regardless of its topology.
Error Backpropagation
The backpropagation procedure can therefore be summarized as follows.
1: Apply an input vector to the network and forward propagate through the network using (5.3.5) and (5.3.6) to find the activations of all the hidden and output units.
2: Evaluate the for all the output units using (5.3.11).
3: Backpropagate the using (5.3.13) to obtain for each hidden unit in the
network.
4: Use (5.3.10) to evaluate the required derivatives.
For batch methods, the derivative of the total error E can then be obtained by repeating the above steps for each pattern in the training set and then summing over all patterns:
In the above derivation we have implicitly assumed that each hidden or output unit in the network has the same activation function . The derivation is easily generalized, however, to allow different units to have individual activation functions, simply by keeping track of which form of goes with which unit.
A simple example
[Skip]
Efficiency of backpropagation
ne of the most important aspects of backpropagation is its computational effi- ciency. To understand this, let us examine how the number of computer operations required to evaluate the derivatives of the error function scales with the total number of weights and biases in the network.A single evaluation of the error function (for a given input pattern) would require operations,for sufficiently large . This follows from the fact that, except for a network with very sparse connections, the number of weights is typically much greater than the number of units, and so the bulk of the computational effort in forward propagation is concerned with evaluat- ing the sums in (5.3.5), with the evaluation of the activation functions representing a small overhead. Each term in the sum in (5.3.5) requires one multiplication and one addition, leading to an overall computational cost that is .
An alternative approach to backpropagation for computing the derivatives of the error function is to use finite differences. This can be done by perturbing each weight in turn, and approximating the derivatives by the expression
In a software simulation, the accuracy of the approximation to the derivatives can be improved by making smaller, until numerical roundoff problems arise. The accuracy of the finite differences method can be improved significantly by using symmetrical central differences of the form
In this case, the corrections cancel, as can be verified by Taylor expansion on the right-hand side of (5.3.16), and so the residual corrections are . The number of computational steps is, however, roughly doubled compared with (5.3.15).
The main problem with numerical differentiation is that the highly desirable scaling has been lost.Each forward propagation requires steps, and there are weights in the network each of which must be perturbed individually, so that the overall scaling is .
However, numerical differentiation plays an important role in practice, because a comparison of the derivatives calculated by backpropagation with those obtained using central differences provides a powerful check on the correctness of any software implementation of the backpropagation algorithm. When training networks in prac- tice, derivatives should be evaluated using backpropagation, because this gives the greatest accuracy and numerical efficiency. However, the results should be compared with numerical differentiation using (5.3.16) for some test cases in order to check the correctness of the implementation.
The Jacobian matrix
We have seen how the derivatives of an error function with respect to the weights can be obtained by the propagation of errors backwards through the network. The technique of backpropagation can also be applied to the calculation of other deriva- tives. Here we consider the evaluation of the Jacobian matrix, whose elements are given by the derivatives of the network outputs with respect to the inputs
where each such derivative is evaluated with all other inputs held fixed. Jacobian matrices play a useful role in systems built from a number of distinct modules, as illustrated follow.
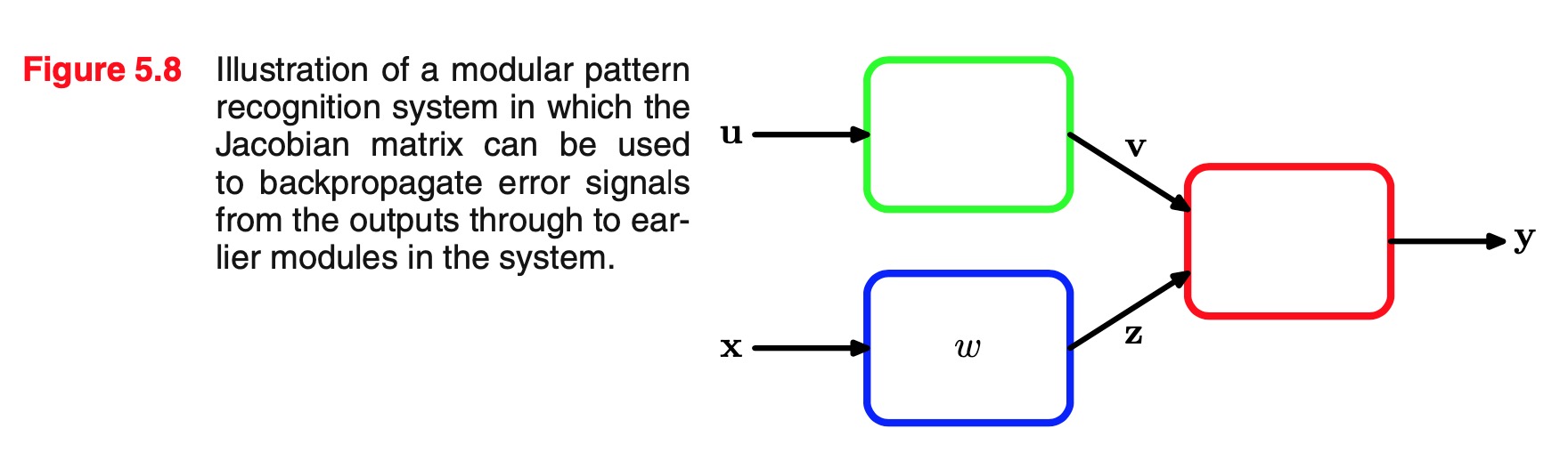
Each module can comprise a fixed or adaptive function, which can be linear or nonlinear, so long as it is differentiable. Suppose we wish to minimize an error function with respect to the parameter . The derivative of the error function is given by
in which the Jacobian matrix for the red module in Figure appears in the middle term.
Because the Jacobian matrix provides a measure of the local sensitivity of the outputs to changes in each of the input variables, it also allows any known errors associated with the inputs to be propagated through the trained network in order to estimate their contribution to the errors at the outputs, through the relation
which is valid provided the are small.
In general, the network mapping represented by a trained neural network will be nonlinear, and so the elements of the Jacobian matrix will not be constants but will depend on the particular input vector used. Thus (5.3.19) is valid only for small perturbations of the inputs, and the Jacobian itself must be re-evaluated for each new input vector.
The Jacobian matrix can be evaluated using a backpropagation procedure that is similar to the one derived earlier for evaluating the derivatives of an error function with respect to the weights. We start by writing the element Jki in the form
where we have made use of (5.3.5). The sum in (5.3.20) runs over all units j to which the input unit i sends connections (for example, over all units in the first hidden layer in the layered topology considered earlier).
We now write down a recursive backpropagation formula to determine the derivatives
where the sum runs over all units to which unit sends connections (corresponding to the first index of ).Again, we have made use of (5.3.5) and (5.3.6). This backpropagation starts at the output units for which the required derivatives can be found directly from the functional form of the output-unit activation function. For instance, if we have individual sigmoidal activation functions at each output unit, then
whereas for softmax outputs we have
We can summarize the procedure for evaluating the Jacobian matrix as follows. Apply the input vector corresponding to the point in input space at which the Jacobian matrix is to be found, and forward propagate in the usual way to obtain the activations of all of the hidden and output units in the network. Next, for each row k of the Jacobian matrix, corresponding to the output unit , backpropagate using the recursive relation (5.3.21), starting with (5.3.22) or (5.3.23), for all of the hidden units in the network.Finally, use (5.3.23) to do the backpropagation to the inputs. The Jacobian can also be evaluated using an alternative forward propagation formalism, which can be derived in an analogous way to the backpropagation approach given here.
Again, the implementation of such algorithms can be checked by using numeri- cal differentiation in the form
which involves 2D forward propagations for a network having D inputs.
The Hessian Matrix
We have shown how the technique of backpropagation can be used to obtain the first derivatives of an error function with respect to the weights in the network. Back- propagation can also be used to evaluate the second derivatives of the error, given by
Note that it is sometimes convenient to consider all of the weight and bias parameters as elements of a single vector, denoted , in which case the second derivatives form the elements of the Hessian matrix , where and is the total number of weights and biases. The Hessian plays an important role in many aspects of neural computing, including the following:
- Several nonlinear optimization algorithms used for training neural networks are based on considerations of the second-order properties of the error surface, which are controlled by the Hessian matrix
- The Hessian forms the basis of a fast procedure for re-training a feed-forward network following a small change in the training data
- The inverse of the Hessian has been used to identify the least significant weights in a network as part of network pruning algorithms
- The Hessian plays a central role in the Laplace approximation for a Bayesian neural network.Its inverse is used to determine the predic- tive distribution for a trained network, its eigenvalues determine the values of hyperparameters, and its determinant is used to evaluate the model evidence.
Various approximation schemes have been used to evaluate the Hessian matrix for a neural network. However, the Hessian can also be calculated exactly using an extension of the backpropagation technique.
An important consideration for many applications of the Hessian is the efficiency with which it can be evaluated. If there are parameters (weights and biases) in the network, then the Hessian matrix has dimensions and so the computational effort needed to evaluate the Hessian will scale like for each pattern in the data set. As we shall see, there are efficient methods for evaluating the Hessian whose scaling is indeed .
Diagonal approximation
Some of the applications for the Hessian matrix discussed above require the inverse of the Hessian, rather than the Hessian itself. For this reason, there has been some interest in using a diagonal approximation to the Hessian, in other words one that simply replaces the off-diagonal elements with zeros, because its inverse is trivial to evaluate. Again, we shall consider an error function that consists of a sum of terms, one for each pattern in the data set, so that . The Hessian can then be obtained by considering one pattern at a time, and then summing the results over all patterns. From (5.3.5), the diagonal elements of the Hessian, for pattern n, can be written
Using (5.3.5) and (5.3.6), the second derivatives on the right-hand side of (5.4.2) can be found recursively using the chain rule of differential calculus to give a backprop- agation equation of the form
If we now neglect off-diagonal elements in the second-derivative terms, we obtain
Note that the number of computational steps required to evaluate this approximation is , where is the total number of weight and bias parameters in the network, compared with for the full Hessian.
Ricotti et al. (1988) also used the diagonal approximation to the Hessian, but they retained all terms in the evaluation of and so obtained exact expres- sions for the diagonal terms. Note that this no longer has scaling. The major problem with diagonal approximations, however, is that in practice the Hessian is typically found to be strongly nondiagonal, and so these approximations, which are driven mainly be computational convenience, must be treated with care.
Outer product approximation
When neural networks are applied to regression problems, it is common to use a sum-of-squares error function of the form
where we have considered the case of a single output in order to keep the notation simple (the extension to several outputs is straightforward). We can then write the Hessian matrix in the form
If the network has been trained on the data set, and its outputs happen to be very close to the target values tn, then the second term in (5.4.6) will be small and can be neglected. More generally, however, it may be appropriate to neglect this term by the following argument.Recall from Section 1.6.5 that the optimal function that minimizes a sum-of-squares loss is the conditional average of the target data. The quantity is then a random variable with zero mean. If we assume that its value is uncorrelated with the value of the second derivative term on the right-hand side of (5.4.6), then the whole term will average to zero in the summation over .
By neglecting the second term in (5.4.6), we arrive at the Levenberg–Marquardt approximation or outer product approximation (because the Hessian matrix is built up from a sum of outer products of vectors), given by
where because the activation function for the output units is simply the identity. Evaluation of the outer product approximation for the Hessian is straightforward as it only involves first derivatives of the error function, which can be evaluated efficiently in steps using standard backpropagation. The elements of the matrix can then be found in steps by simple multiplication. It is important to emphasize that this approximation is only likely to be valid for a network that has been trained appropriately, and that for a general network mapping the second derivative terms on the right-hand side of (5.4.6) will typically not be negligible.
In the case of the cross-entropy error function for a network with logistic sigmoid output-unit activation functions, the corresponding approximation is given by
An analogous result can be obtained for multiclass networks having softmax output-unit activation functions.
Inverse Hessian
We can use the outer-product approximation to develop a computationally ef- ficient procedure for approximating the inverse of the Hessian (Hassibi and Stork, 1993). First we write the outer-product approximation in matrix notation as
where is the contribution to the gradient of the output unit activation arising from data point . We now derive a sequential procedure for building up the Hessian by including data points one at a time. Suppose we have already obtained the inverse Hessian using the first data points. By separating off the contribution from data point , we obtain
In order to evaluate the inverse of the Hessian, we now consider the matrix identity
where is the unit matrix, which is simply a special case of the Woodbury identity(C.7). If we now identify with and with , we obtain
In this way, data points are sequentially absorbed until and the whole data set has been processed. This result therefore represents a procedure for evaluating the inverse of the Hessian using a single pass through the data set. The initial matrix is chosen to be , where α is a small quantity, so that the algorithm actually finds the inverse of . The results are not particularly sensitive to the precise value of . Extension of this algorithm to networks having more than one output is straightforward.
We note here that the Hessian matrix can sometimes be calculated indirectly as part of the network training algorithm. In particular, quasi-Newton nonlinear opti- mization algorithms gradually build up an approximation to the inverse of the Hes- sian during training. Such algorithms are discussed in detail in Bishop and Nabney (2008).
Finite differences
As in the case of the first derivatives of the error function, we can find the second derivatives by using finite differences, with accuracy limited by numerical precision. If we perturb each possible pair of weights in turn, we obtain
Again, by using a symmetrical central differences formulation, we ensure that the residual errors are rather than . Because there are elements in the Hessian matrix, and because the evaluation of each element requires four forward propagations each needing operations (per pattern), we see that this approach will require operations to evaluate the complete Hessian. It therefore has poor scaling properties, although in practice it is very useful as a check on the software implementation of backpropagation methods.
A more efficient version of numerical differentiation can be found by applying central differences to the first derivatives of the error function, which are themselves calculated using backpropagation. This gives
Because there are now only weights to be perturbed, and because the gradients can be evaluated in steps, we see that this method gives the Hessian in operations.
Exact evaluation of the Hessian
So far, we have considered various approximation schemes for evaluating the Hessian matrix or its inverse. The Hessian can also be evaluated exactly, for a net- work of arbitrary feed-forward topology, using extension of the technique of back- propagation used to evaluate first derivatives, which shares many of its desirable features including computational efficiency (Bishop, 1991; Bishop, 1992). It can be applied to any differentiable error function that can be expressed as a function of the network outputs and to networks having arbitrary differentiable activation func- tions. The number of computational steps needed to evaluate the Hessian scales like . Similar algorithms have also been considered by Buntine and Weigend (1993).
Here we consider the specific case of a network having two layers of weights, for which the required equations are easily derived. We shall use indices and to denote inputs, indices and to denoted hidden units, and indices and to denote outputs. We first define
where is the contribution to the error from data point . The Hessian matrix for this network can then be considered in three separate blocks as follows.
- Both weights in the second layer:
- Both weights in the first layer:
- One weight in each layer:
Here is the element of the identity matrix. If one or both of the weights is a bias term, then the corresponding expressions are obtained simply by setting the appropriate activation(s) to 1. Inclusion of skip-layer connections is straightforward.
Fast multiplication by the Hessian
For many applications of the Hessian, the quantity of interest is not the Hessian matrix itself but the product of with some vector . We have seen that the evaluation of the Hessian takes operations, and it also requires storage that is . The vector that we wish to calculate, however, has only elements, so instead of computing the Hessian as an intermediate step, we can instead try to find an efficient approach to evaluating directly in a way that requires only operations.
To do this, we first note that
where denotes the gradient operator in weight space. We can then write down the standard forward-propagation and backpropagation equations for the evaluation of and apply (5.4.19) to these equations to give a set of forward-propagation and backpropagation equations for the evaluation of (Møller, 1993; Pearlmutter, 1994). This corresponds to acting on the original forward-propagation and backpropagation equations with a differential operator . Pearlmutter (1994) used the notation to denote the operator , and we shall follow this convention.The analysis is straightforward and makes use of the usual rules of differential calculus, together with the result
Regularization in Neural Networks
The number of input and outputs units in a neural network is generally determined by the dimensionality of the data set, whereas the number M of hidden units is a free parameter that can be adjusted to give the best predictive performance. Note that M controls the number of parameters (weights and biases) in the network, and so we might expect that in a maximum likelihood setting there will be an optimum value of M that gives the best generalization performance, corresponding to the optimum balance between under-fitting and over-fitting.
The generalization error, however, is not a simple function of M due to the presence of local minima in the error function.
Here we see the effect of choosing multiple random initializations for the weight vector for a range of values of M. The overall best validation set performance in this case occurred for a particular solution having .
here are, however, other ways to control the complexity of a neural network model in order to avoid over-fitting. From our discussion of polynomial curve fitting in Chapter 1, we see that an alternative approach is to choose a relatively large value for M and then to control complexity by the addition of a regularization term to the error function. The simplest regularizer is the quadratic, giving a regularized error of the form
This regularizer is also known as weight decay and has been discussed at length in Chapter 3. The effective model complexity is then determined by the choice of the regularization coefficient . As we have seen previously, this regularizer can be interpreted as the negative logarithm of a zero-mean Gaussian prior distribution over the weight vector .
Consistent Gaussian priors
One of the limitations of simple weight decay in the form (5.5.1) is that is inconsistent with certain scaling properties of network mappings.
[TODO]
Early stopping
An alternative to regularization as a way of controlling the effective complexity of a network is the procedure of early stopping. The training of nonlinear network models corresponds to an iterative reduction of the error function defined with re- spect to a set of training data. For many of the optimization algorithms used for network training, such as conjugate gradients, the error is a nonincreasing function of the iteration index. However, the error measured with respect to independent data, generally called a validation set, often shows a decrease at first, followed by an in- crease as the network starts to over-fit. Training can therefore be stopped at the point of smallest error with respect to the validation data set, in order to obtain a network having good generalization performance.
The behaviour of the network in this case is sometimes explained qualitatively in terms of the effective number of degrees of freedom in the network, in which this number starts out small and then to grows during the training process, corresponding to a steady increase in the effective complexity of the model. Halting training before a minimum of the training error has been reached then represents a way of limiting the effective network complexity.
In the case of a quadratic error function, we can verify this insight, and show that early stopping should exhibit similar behaviour to regularization using a sim- ple weight-decay term.
Invariances
In many applications of pattern recognition, it is known that predictions should be unchanged, or invariant, under one or more transformations of the input vari- ables. For example, in the classification of objects in two-dimensional images, such as handwritten digits, a particular object should be assigned the same classification irrespective of its position within the image (translation invariance) or of its size (scale invariance). Such transformations produce significant changes in the raw data, expressed in terms of the intensities at each of the pixels in the image, and yet should give rise to the same output from the classification system. Similarly in speech recognition, small levels of nonlinear warping along the time axis, which preserve temporal ordering, should not change the interpretation of the signal.
If sufficiently large numbers of training patterns are available, then an adaptive model such as a neural network can learn the invariance, at least approximately. This involves including within the training set a sufficiently large number of examples of the effects of the various transformations. Thus, for translation invariance in an im- age, the training set should include examples of objects at many different positions.
This approach may be impractical, however, if the number of training examples is limited, or if there are several invariants (because the number of combinations of transformations grows exponentially with the number of such transformations). We therefore seek alternative approaches for encouraging an adaptive model to exhibit the required invariances. These can broadly be divided into four categories:
1.The training set is augmented using replicas of the training patterns, trans- formed according to the desired invariances. For instance, in our digit recog- nition example, we could make multiple copies of each example in which the digit is shifted to a different position in each image.
2.A regularization term is added to the error function that penalizes changes in the model output when the input is transformed. This leads to the technique of tangent propagation
3.Invariance is built into the pre-processing by extracting features that are invari- ant under the required transformations. Any subsequent regression or classi- fication system that uses such features as inputs will necessarily also respect these invariances.
4.The final option is to build the invariance properties into the structure of a neu- ral network (or into the definition of a kernel function in the case of techniques such as the relevance vector machine). One way to achieve this is through the use of local receptive fields and shared weights, as discussed in the context of convolutional neural networks in Section 5.5.6.
Approach 1 is often relatively easy to implement and can be used to encourage com- plex invariances. For sequential training algorithms, this can be done by transforming each input pattern before it is presented to the model so that, if the patterns are being recycled, a different transformation (drawn from an appropriate distribution) is added each time. For batch methods, a similar effect can be achieved by replicating each data point a number of times and transforming each copy independently. The use of such augmented data can lead to significant improvements in generalization (Simard et al., 2003), although it can also be computationally costly.
Approach 2 leaves the data set unchanged but modifies the error function through the addition of a regularizer. In Section 5.5.5, we shall show that this approach is closely related to approach 2.
One advantage of approach 3 is that it can correctly extrapolate well beyond the range of transformations included in the training set. However, it can be difficult to find hand-crafted features with the required invariances that do not also discard information that can be useful for discrimination.
Tangent propagation
We can use regularization to encourage models to be invariant to transformations of the input through the technique of tangent propagation
Consider the effect of a transformation on a particular input vector . Provided the transformation is continuous (such as translation or rotation, but not mirror reflection for instance), then the transformed pattern will sweep out a manifold within the D-dimensional input space.
[TODO]
Training with transformed data
We have seen that one way to encourage invariance of a model to a set of transformations is to expand the training set using transformed versions of the original input patterns. Here we show that this approach is closely related to the technique of tangent propagation (Bishop, 1995b; Leen, 1995).
[TODO(With Tangent propagation)]
Convolutional networks
Another approach to creating models that are invariant to certain transformation of the inputs is to build the invariance properties into the structure of a neural net- work. This is the basis for the convolutional neural network (Le Cun et al., 1989; LeCun et al., 1998), which has been widely applied to image data.
Consider the specific task of recognizing handwritten digits. Each input image comprises a set of pixel intensity values, and the desired output is a posterior probability distribution over the ten digit classes. We know that the identity of the digit is invariant under translations and scaling as well as (small) rotations. Furthermore, the network must also exhibit invariance to more subtle transformations such as elastic deformations of the kind as follow. One simple approach would be to treat the image as the input to a fully connected network. Given a sufficiently large training set, such a network could in principle yield a good solution to this problem and would learn the appropriate invariances by example.
However, this approach ignores a key property of images, which is that nearby pixels are more strongly correlated than more distant pixels. Many of the modern approaches to computer vision exploit this property by extracting local features that depend only on small subregions of the image. Information from such features can then be merged in later stages of processing in order to detect higher-order features and ultimately to yield information about the image as whole. Also, local features that are useful in one region of the image are likely to be useful in other regions of the image, for instance if the object of interest is translated.
{kind=link}
The structure of a convolutional network
These notions are incorporated into convolutional neural networks through three mechanisms:
- local receptive fields
- weight sharing
- subsampling.
In the convolutional layer the units are organized into planes, each of which is called a feature map. Units in a feature map each take inputs only from a small subregion of the image, and all of the units in a feature map are constrained to share the same weight values. For instance, a feature map might consist of 100 units arranged in a 10 × 10 grid, with each unit taking inputs from a 5 × 5 pixel patch of the image. The whole feature map therefore has 25 adjustable weight parameters plus one adjustable bias parameter. Input values from a patch are linearly combined using the weights and the bias, and the result transformed by a sigmoidal nonlinearity using (5.1). If we think of the units as feature detectors, then all of the units in a feature map detect the same pattern but at different locations in the input image. Due to the weight sharing, the evaluation of the activations of these units is equivalent to a convolution of the image pixel intensities with a ‘kernel’ comprising the weight parameters. If the input image is shifted, the activations of the feature map will be shifted by the same amount but will otherwise be unchanged. This provides the basis for the (approximate) invariance of the network outputs to translations and distortions of the input image. Because we will typically need to detect multiple features in order to build an effective model, there will generally be multiple feature maps in the convolutional layer, each having its own set of weight and bias parameters.
The outputs of the convolutional units form the inputs to the subsampling layer of the network. For each feature map in the convolutional layer, there is a plane of units in the subsampling layer and each unit takes inputs from a small receptive field in the corresponding feature map of the convolutional layer. These units perform subsampling. For instance, each subsampling unit might take inputs from a 2 × 2 unit region in the corresponding feature map and would compute the average of those inputs, multiplied by an adaptive weight with the addition of an adaptive bias parameter, and then transformed using a sigmoidal nonlinear activation function. The receptive fields are chosen to be contiguous and nonoverlapping so that there are half the number of rows and columns in the subsampling layer compared with the convolutional layer. In this way, the response of a unit in the subsampling layer will be relatively insensitive to small shifts of the image in the corresponding regions of the input space.
In a practical architecture, there may be several pairs of convolutional and sub- sampling layers. At each stage there is a larger degree of invariance to input trans- formations compared to the previous layer. There may be several feature maps in a given convolutional layer for each plane of units in the previous subsampling layer, so that the gradual reduction in spatial resolution is then compensated by an increas- ing number of features. The final layer of the network would typically be a fully connected, fully adaptive layer, with a softmax output nonlinearity in the case of multiclass classification.
The whole network can be trained by error minimization using backpropagation to evaluate the gradient of the error function. This involves a slight modification of the usual backpropagation algorithm to ensure that the shared-weight constraints are satisfied. Due to the use of local receptive fields, the number of weights in the network is smaller than if the network were fully connected. Furthermore, the number of independent parameters to be learned from the data is much smaller still, due to the substantial numbers of constraints on the weights.
Soft weight sharing
One way to reduce the effective complexity of a network with a large number of weights is to constrain weights within certain groups to be equal. This is the technique of weight sharing that was discussed in Section 5.5.6 as a way of building translation invariance into networks used for image interpretation. It is only appli- cable, however, to particular problems in which the form of the constraints can be specified in advance. Here we consider a form of soft weight sharing (Nowlan and Hinton, 1992) in which the hard constraint of equal weights is replaced by a form of regularization in which groups of weights are encouraged to have similar values. Furthermore, the division of weights into groups, the mean weight value for each group, and the spread of values within the groups are all determined as part of the learning process.
Mixture Density Networks
[Skip]
Bayesian Neural Networks
[Skip]
Kernel Methods
Many linear parametric models can be re-cast into an equivalent ‘dual represen- tation’ in which the predictions are also based on linear combinations of a kernel function evaluated at the training data points. As we shall see, for models which are based on a fixed nonlinear feature space mapping φ(x), the kernel function is given by the relation
From this definition, we see that the kernel is a symmetric function of its arguments so that .
The kernel concept was introduced into the field of pattern recognition by Aizerman et al. (1964) in the context of the method of potential functions, so-called because of an analogy with electrostatics. Although neglected for many years, it was reintroduced into machine learning in the context of large-margin classifiers by Boser et al. (1992) giving rise to the technique of support vector machines.
The simplest example of a kernel function is obtained by considering the identity mapping for the feature space in (6.1.1) so that , in which case .We shall refer to this as the linear kernel.
Inner Product
The concept of a kernel formulated as an inner product in a feature space allows us to build interesting extensions of many well-known algorithms by making use of the kernel trick, also known as kernel substitution. The general idea is that, if we have an algorithm formulated in such a way that the input vector x enters only in the form of scalar products, then we can replace that scalar product with some other choice of kernel. For instance, the technique of kernel substitution can be applied to principal component analysis in order to develop a nonlinear variant of PCA
Dual Representations
Many linear models for regression and classification can be reformulated in terms of a dual representation in which the kernel function arises naturally. This concept will play an important role when we consider support vector machines in the next chapter.
[TODO]
Constructing Kernels
In order to exploit kernel substitution, we need to be able to construct valid kernel functions. One approach is to choose a feature space mapping and then use this to find the corresponding kernel.
[TODO]
Radial Basis Function Networks
Historically, radial basis functions were introduced for the purpose of exact function interpolation, which have the property that each basis function depends only on the radial distance (typically Euclidean) from a centre , so that
Given a set of input vectors along with corresponding target values , the goal is to find a smooth function that fits every target value exactly, so that for . This is achieved by expressing as a linear combination of radial basis functions, one centred on every data point
The values of the coefficients are found by least squares, and because there are the same number of coefficients as there are constraints, the result is a function that fits every target value exactly. In pattern recognition applications, however, the target values are generally noisy, and exact interpolation is undesirable because this corresponds to an over-fitted solution.
Gaussian Processes
[TODO]
Sparse Kernel Machines
In the previous chapter, we explored a variety of learning algorithms based on nonlinear kernels. One of the significant limitations of many such algorithms is that the kernel function must be evaluated for all possible pairs and of training points, which can be computationally infeasible during training and can lead to excessive computation times when making predictions for new data points. In this chapter we shall look at kernel-based algorithms that have sparse solutions, so that predictions for new inputs depend only on the kernel function evaluated at a subset of the training data points.
We begin by looking in some detail at the support vector machine (SVM), which became popular in some years ago for solving problems in classification, regression, and novelty detection.
convex optimization problem
An important property of support vector machines is that the determination of the model parameters corresponds to a convex optimization prob- lem, and so any local solution is also a global optimum.
Maximum Margin Classifiers [Support Vector Machine]
We begin our discussion of support vector machines by returning to the two-class classification problem using linear models of the form
where denotes a fixed feature-space transformation, and we have made the bias parameter b explicit.
Note that we shall shortly introduce a dual representation expressed in terms of kernel functions, which avoids having to work explicitly in feature space. The training data set comprises N input vectors , with corresponding target values where , and new data points are classified according to the sign of .
We shall assume for the moment that the training data set is linearly separable in feature space, so that by definition there exists at least one choice of the parameters and such that a function of the form (7.1.1) satisfies for points having and $y(\bold x_n) \lt 0 $ for points having ,so that
for all training data points.
Margin
There may of course exist many such solutions that separate the classes exactly. In Section 4.1.7, we described the perceptron algorithm that is guaranteed to find a solution in a finite number of steps. The solution that it finds, however, will be dependent on the (arbitrary) initial values chosen for and as well as on the order in which the data points are presented. If there are multiple solutions all of which classify the training data set exactly, then we should try to find the one that will give the smallest generalization error. The support vector machine approaches this problem through the concept of the margin, which is defined to be the smallest distance between the decision boundary and any of the samples, as illustrated follow.
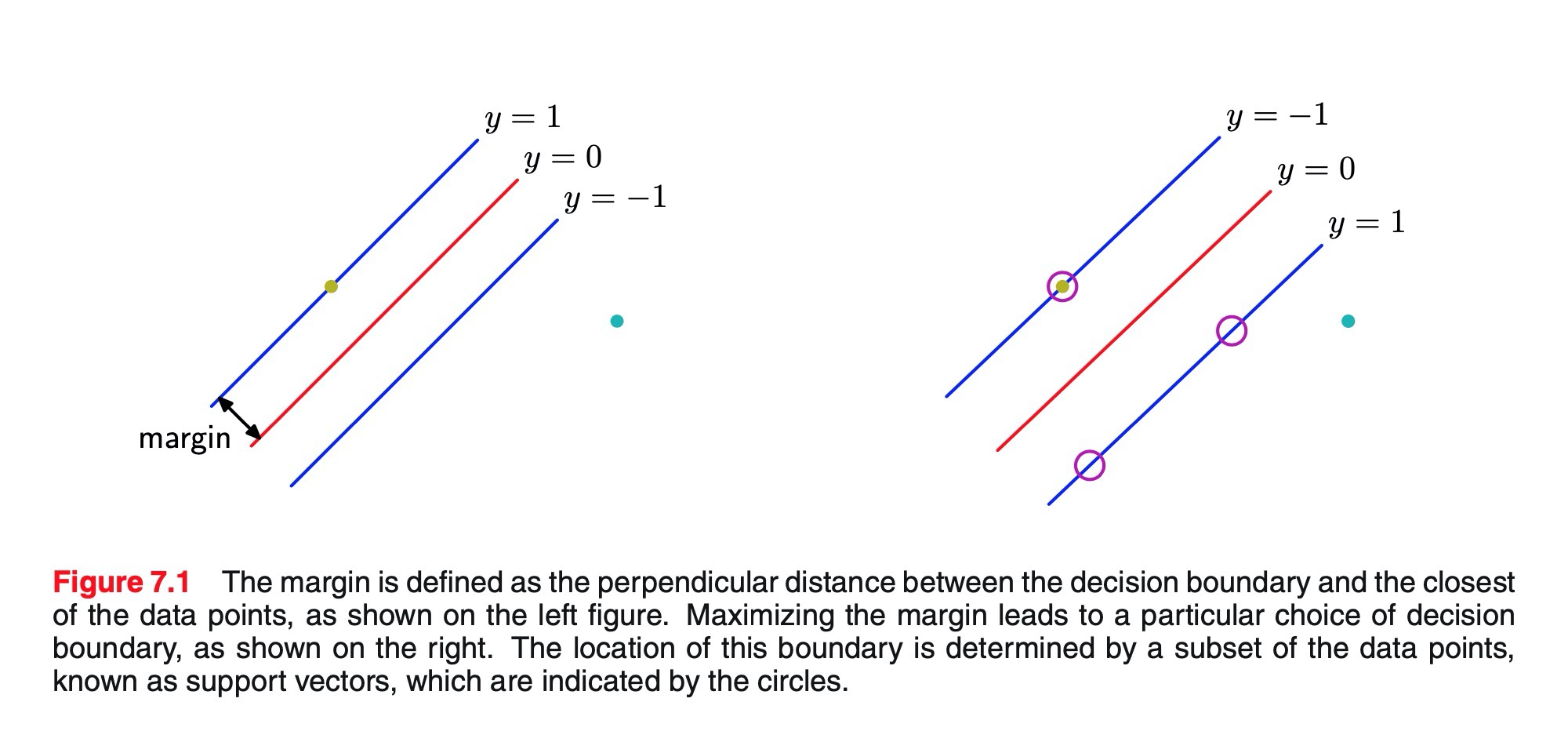
In support vector machines the decision boundary is chosen to be the one for which the margin is maximized. The maximum margin solution can be motivated using computational learning theory, also known as statistical learning theory. However, a simple insight into the origins of maximum margin has been given by Tong and Koller (2000) who consider a framework for classification based on a hybrid of generative and discriminative approaches. They first model the distribution over input vectors for each class using a Parzen density estimator with Gaussian kernels having a common parameter . Together with the class priors, this defines an optimal misclassification-rate decision boundary. However, instead of using this optimal boundary, they determine the best hyperplane by minimizing the probability of error relative to the learned density model. In the limit , the optimal hyperplane is shown to be the one having maximum margin. The intuition behind this result is that as is reduced, the hyperplane is increasingly dominated by nearby data points relative to more distant ones. In the limit, the hyperplane becomes independent of data points that are not support vectors.
The perpendicular distance of a point from a hyper-plane defined by where takes the form (7.1.1) is given by . Furthermore, we are only interested in solutions for which all data points are correctly classified, so that for all . Thus the distance of a point to the decision surface is given by
The margin is given by the perpendicular distance to the closest point from the data set, and we wish to optimize the parameters and in order to maximize this distance. Thus the maximum margin solution is found by solving
where we have taken the factor outside the optimization over because does not depend on . Direct solution of this optimization problem would be very complex, and so we shall convert it into an equivalent problem that is much easier to solve. To do this we note that if we make the rescaling and , then the distance from any point to the decision surface, given by , is unchanged. We can use this freedom to set
for the point that is closest to the surface. In this case, all data points will satisfy the constraints
This is known as the canonical representation of the decision hyperplane. In the case of data points for which the equality holds, the constraints are said to be active, whereas for the remainder they are said to be inactive.
By definition, there will always be at least one active constraint, because there will always be a closest point, and once the margin has been maximized there will be at least two active constraints. The optimization problem then simply requires that we maximize , which is equivalent to minimizing , and so we have to solve the optimization problem
subject to the constraints given by (7.1.5). The factor of 1/2 in (7.1.6) is included for later convenience.
This is an example of a quadratic programming problem in which we are trying to minimize a quadratic function subject to a set of linear inequality constraints. It appears that the bias parameter has disappeared from the optimization. However, it is determined implicitly via the constraints, because these require that changes to be compensated by changes to . We shall see how this works shortly.
Lagrange multipliers
In order to solve this constrained optimization problem, we introduce Lagrange multipliers , with one multiplier for each of the constraints in (7.1.5), giving the Lagrangian function
where . Note the minus sign in front of the Lagrange multiplier term, because we are minimizing with respect to and , and maximizing with respect to .
Setting the derivatives of with respect to and equal to zero, we obtain the following two conditions
Eliminating and from using these conditions then gives the dual representation of the maximum margin problem in which we maximize
with respect to subject to the constraints
Here the kernel function is defined by . Again, this takes the form of a quadratic programming problem in which we optimize a quadratic function of a subject to a set of inequality constraints. We shall discuss techniques for solving such quadratic programming problems next.
The solution to a quadratic programming problem in variables in general has computational complexity that is . In going to the dual formulation we have turned the original optimization problem, which involved minimizing (7.1.6) over variables, into the dual problem (7.1.10), which has variables. For a fixed set of basis functions whose number is smaller than the number of data points, the move to the dual problem appears disadvantageous. However, it allows the model to be reformulated using kernels, and so the maximum margin classifier can be applied efficiently to feature spaces whose dimensionality exceeds the number of data points, including infinite feature spaces. The kernel formulation also makes clear the role of the constraint that the kernel function be positive definite, because this ensures that the lagrangian furnction is bounded below, giving rise to a well-defined optimization problem.
In order to classify new data points using the trained model, we evaluate the sign of y(x) defined by (7.1.1). This can be expressed in terms of the parameters and the kernel function by substituting for using (7.1.8) to give
a constrained optimization of this form satisfies the Karush-Kuhn-Tucker (KKT) conditions, which in this case require that the following three properties hold
Thus for every data point, either or . Any data point for which will not appear in the sum in (7.1.12) and hence plays no role in making predictions for new data points. The remaining data points are called support vectors, and because they satisfy , they correspond to points that lie on the maximum margin hyperplanes in feature space, as illustrated above. This property is central to the practical applicability of support vector machines. Once the model is trained, a significant proportion of the data points can be discarded and only the support vectors retained.
Having solved the quadratic programming problem and found a value for , we can then determine the value of the threshold parameter by noting that any support vector satisfies . Using (7.1.12) this gives
where denotes the set of indices of the support vectors. Although we can solve this equation for using an arbitrarily chosen support vector , a numerically more stable solution is obtained by first multiplying through by , making use of , and then averaging these equations over all support vectors and solving for to give
where is the total number of support vectors.
For later comparison with alternative models, we can express the maximum-margin classifier in terms of the minimization of an error function, with a simple quadratic regularizer, in the form
where is a function that is zero if and otherwise and ensures that the constraints (7.1.5) are satisfied. Note that as long as the regularization parameter satisfies , its precise value plays no role.
Figure below shows an example of the classification resulting from training a support vector machine on a simple synthetic data set using a Gaussian kernel of the form
Although the data set is not linearly separable in the two-dimensional data space , it is linearly separable in the nonlinear feature space defined implicitly by the nonlinear kernel function. Thus the training data points are perfectly separated in the original data space.
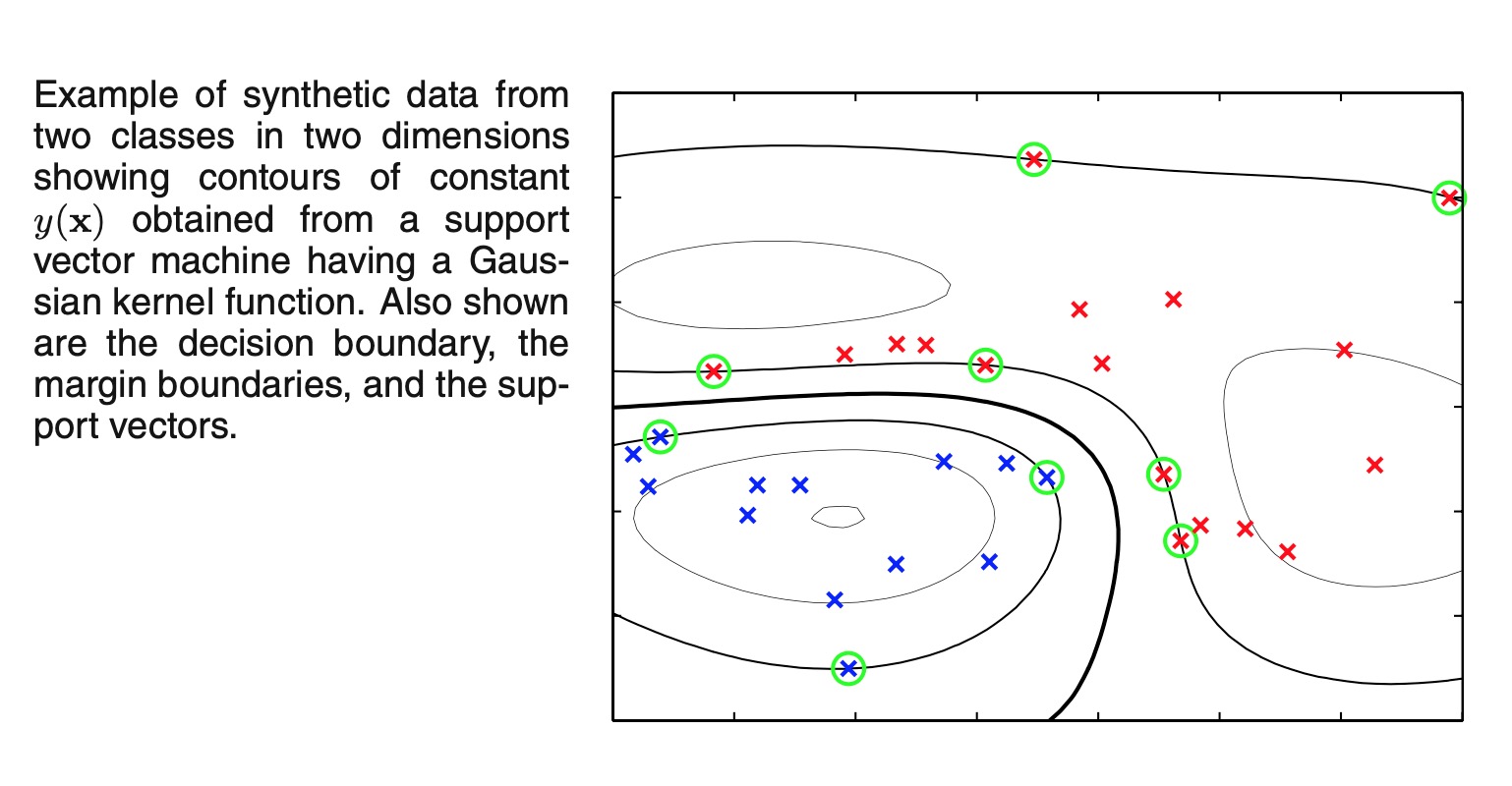
This example also provides a geometrical insight into the origin of sparsity in the SVM. The maximum margin hyperplane is defined by the location of the support vectors. Other data points can be moved around freely (so long as they remain out- side the margin region) without changing the decision boundary, and so the solution will be independent of such data points.
Overlapping class distributions
So far, we have assumed that the training data points are linearly separable in the feature space . The resulting support vector machine will give exact separation of the training data in the original input space , although the corresponding decision boundary will be nonlinear. In practice, however, the class-conditional distributions may overlap, in which case exact separation of the training data can lead to poor generalization.
We therefore need a way to modify the support vector machine so as to allow some of the training points to be misclassified. From (7.1.16) we see that in the case of separable classes, we implicitly used an error function that gave infinite error if a data point was misclassified and zero error if it was classified correctly, and then optimized the model parameters to maximize the margin. We now modify this approach so that data points are allowed to be on the ‘wrong side’ of the margin boundary, but with a penalty that increases with the distance from that boundary. For the subsequent optimization problem, it is convenient to make this penalty a linear function of this distance.
Slack Variables
To do this, we introduce slack variables, where with one slack variable for each training data point (Bennett, 1992; Cortes and Vapnik, 1995). These are defined by for data points that are on or inside the correct margin boundary and for other points. Thus a data point that is on the decision boundary will have , and points with will be misclassified. The exact classification constraints (7.1.5) are then replaced with
in which the slack variables are constrained to satisfy .
Data points for which are correctly classified and are either on the margin or on the correct side of the margin. Points for which lie inside the margin, but on the correct side of the decision boundary, and those data points for which lie on the wrong side of the decision boundary and are misclassified, as illustrated in figure below. This is sometimes described as relaxing the hard margin constraint to give a soft margin and allows some of the training set data points to be misclassified. Note that while slack variables allow for overlapping class distributions, this framework is still sensitive to outliers because the penalty for misclassification increases linearly with .
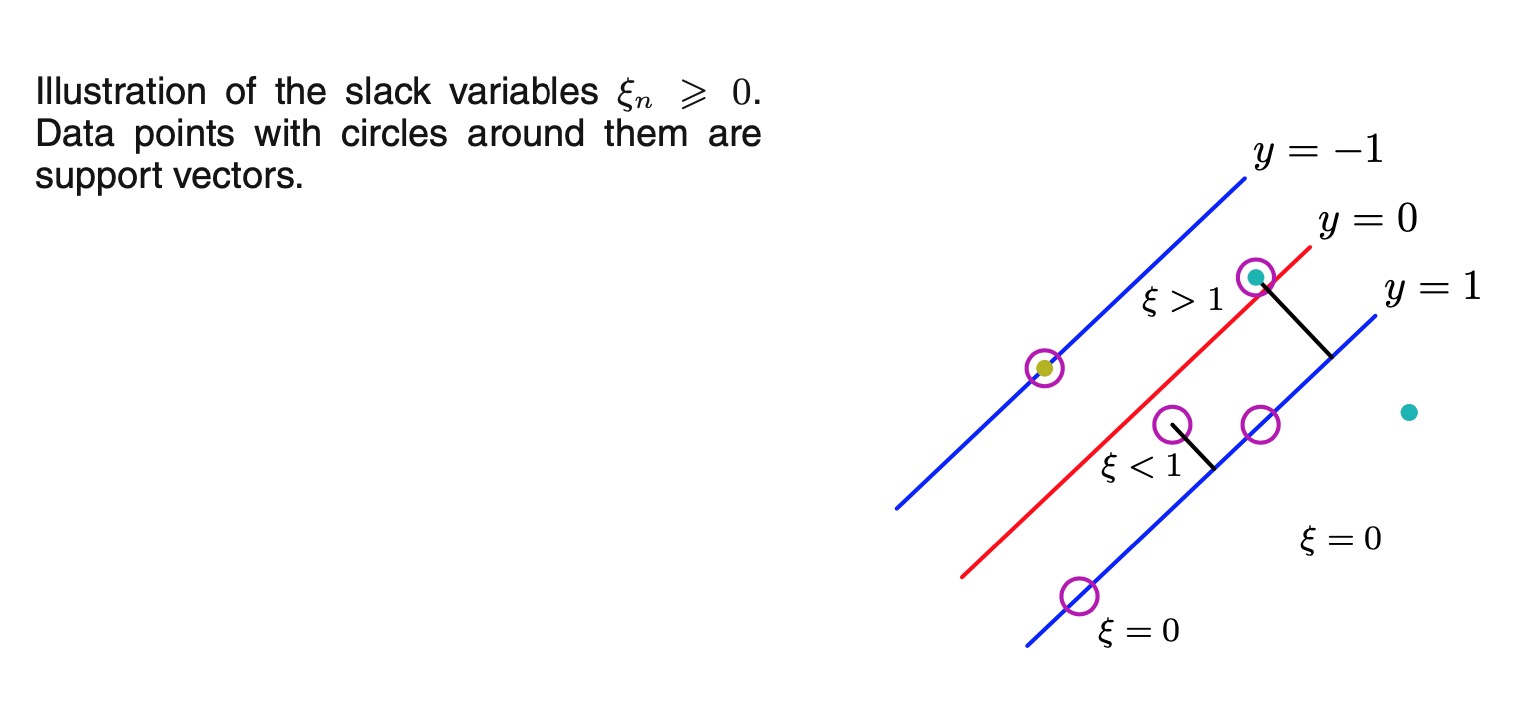
Our goal is now to maximize the margin while softly penalizing points that lie on the wrong side of the margin boundary. We therefore minimize
where the parameter controls the trade-off between the slack variable penalty and the margin. Because any point that is misclassified has , it follows that is an upper bound on the number of misclassified points.
The parameter C is therefore analogous to (the inverse of) a regularization coefficient because it controls the trade-off between minimizing training errors and controlling model complexity. In the limit , we will recover the earlier support vector machine for separable data.
We now wish to minimize (7.1.18) subject to the constraints (7.1.17) together with . The corresponding Lagrangian is given by
where and are Lagrange multipliers. The corresponding set of KKT conditions are given by
where .
We now optimize out , b, and making use of the definition (7.1,1) of to give
Using these results to eliminate , b, and from the Lagrangian, we obtain the dual Lagrangian in the form
which is identical to the separable case, except that the constraints are somewhat different. To see what these constraints are, we note that is required because these are Lagrange multipliers. Furthermore, (7.1.23) together with implies . We therefore have to minimize (7.1.24) with respect to the dual variables subject to
for , where (7.1.25) are known as box constraints. This again represents a quadratic programming problem. If we substitute (7.1.21) into (7.1.1), we see that predictions for new data points are again made by using (7.1.12).
Conclusion
We can now interpret the resulting solution. As before, a subset of the data points may have , in which case they do not contribute to the predictive model (7.1.12). The remaining data points constitute the support vectors. These have
and hence from (7.1.20) must satisfy
if , then (7.1.23) implies that , which from (7.1.20) requires and hence such points lie on the margin. Points with can lie inside the margin and can either be correctly classified if or misclassified if
To determine the parameter b in (7.1.1), we note that those support vectors for which have so that and hence will satisfy.
Again, a numerically stable solution is obtained by averaging to give
where denotes the set of indices of data points having .
Although predictions for new inputs are made using only the support vectors, the training phase (i.e., the determination of the parameters and b) makes use of the whole data set, and so it is important to have efficient algorithms for solving the quadratic programming problem.
We first note that the objective function is quadratic and so any local optimum will also be a global optimum provided the constraints define a convex region (which they do as a consequence of being linear).Direct solution of the quadratic programming problem us- ing traditional techniques is often infeasible due to the demanding computation and memory requirements, and so more practical approaches need to be found. The tech- nique of chunking (Vapnik, 1982) exploits the fact that the value of the Lagrangian is unchanged if we remove the rows and columns of the kernel matrix corresponding to Lagrange multipliers that have value zero. This allows the full quadratic pro- gramming problem to be broken down into a series of smaller ones, whose goal is eventually to identify all of the nonzero Lagrange multipliers and discard the others. Chunking can be implemented using protected conjugate gradients (Burges, 1998). Although chunking reduces the size of the matrix in the quadratic function from the number of data points squared to approximately the number of nonzero Lagrange multipliers squared, even this may be too big to fit in memory for large-scale appli- cations. Decomposition methods (Osuna et al., 1996) also solve a series of smaller quadratic programming problems but are designed so that each of these is of a fixed size, and so the technique can be applied to arbitrarily large data sets. However, it still involves numerical solution of quadratic programming subproblems and these can be problematic and expensive. One of the most popular approaches to training support vector machines is called sequential minimal optimization, or SMO (Platt, 1999). It takes the concept of chunking to the extreme limit and considers just two Lagrange multipliers at a time. In this case, the subproblem can be solved analyti- cally, thereby avoiding numerical quadratic programming altogether. Heuristics are given for choosing the pair of Lagrange multipliers to be considered at each step. In practice, SMO is found to have a scaling with the number of data points that is somewhere between linear and quadratic depending on the particular application.
inner product kernel
We have seen that kernel functions correspond to inner products in feature spaces that can have high, or even infinite, dimensionality. By working directly in terms of the kernel function, without introducing the feature space explicitly, it might there- fore seem that support vector machines somehow manage to avoid the curse of dimensionality.
This is not the case, however, because there are constraints amongst the feature values that restrict the effective dimensionality of feature space. To see this consider a simple second-order polynomial kernel that we can expand in terms of its components
This kernel function therefore represents an inner product in a feature space having six dimensions, in which the mapping from input space to feature space is described by the vector function . However, the coefficients weighting these different features are constrained to have specific forms. Thus any set of points in the original two-dimensional space would be constrained to lie exactly on a two-dimensional nonlinear manifold embedded in the six-dimensional feature space.
We have already highlighted the fact that the support vector machine does not provide probabilistic outputs but instead makes classification decisions for new input vectors. Veropoulos et al. (1999) discuss modifications to the SVM to allow the trade-off between false positive and false negative errors to be controlled. However, if we wish to use the SVM as a module in a larger probabilistic system, then probabilistic predictions of the class label t for new inputs x are required.
To address this issue, Platt (2000) has proposed fitting a logistic sigmoid to the outputs of a previously trained support vector machine. Specifically, the required conditional probability is assumed to be of the form
where is defined by (7.1.1). Values for the parameters A and B are found by minimizing the cross-entropy error function defined by a training set consisting of pairs of values and . The data used to fit the sigmoid needs to be independent of that used to train the original SVM in order to avoid severe over-fitting. This two-stage approach is equivalent to assuming that the output of the support vector machine represents the log-odds of belonging to class . Because the SVM training procedure is not specifically intended to encourage this, the SVM can give a poor approximation to the posterior probabilities (Tipping, 2001).
Relation to logistic regression
As with the separable case, we can re-cast the SVM for nonseparable distri- butions in terms of the minimization of a regularized error function. This will also allow us to highlight similarities, and differences, compared to the logistic regression model.
We have seen that for data points that are on the correct side of the margin boundary, and which therefore satisfy , we have , and for the remaining points we have . Thus the objective function (7.1.18) can be written (up to an overall multiplicative constant) in the form
where and is the hinge error function defined by
where denotes the positive part. The hinge error function, so-called because of its shape, is plotted as follow.
It can be viewed as an approximation to the misclassification error, i.e., the error function that ideally we would like to minimize, which is also shown in Figure
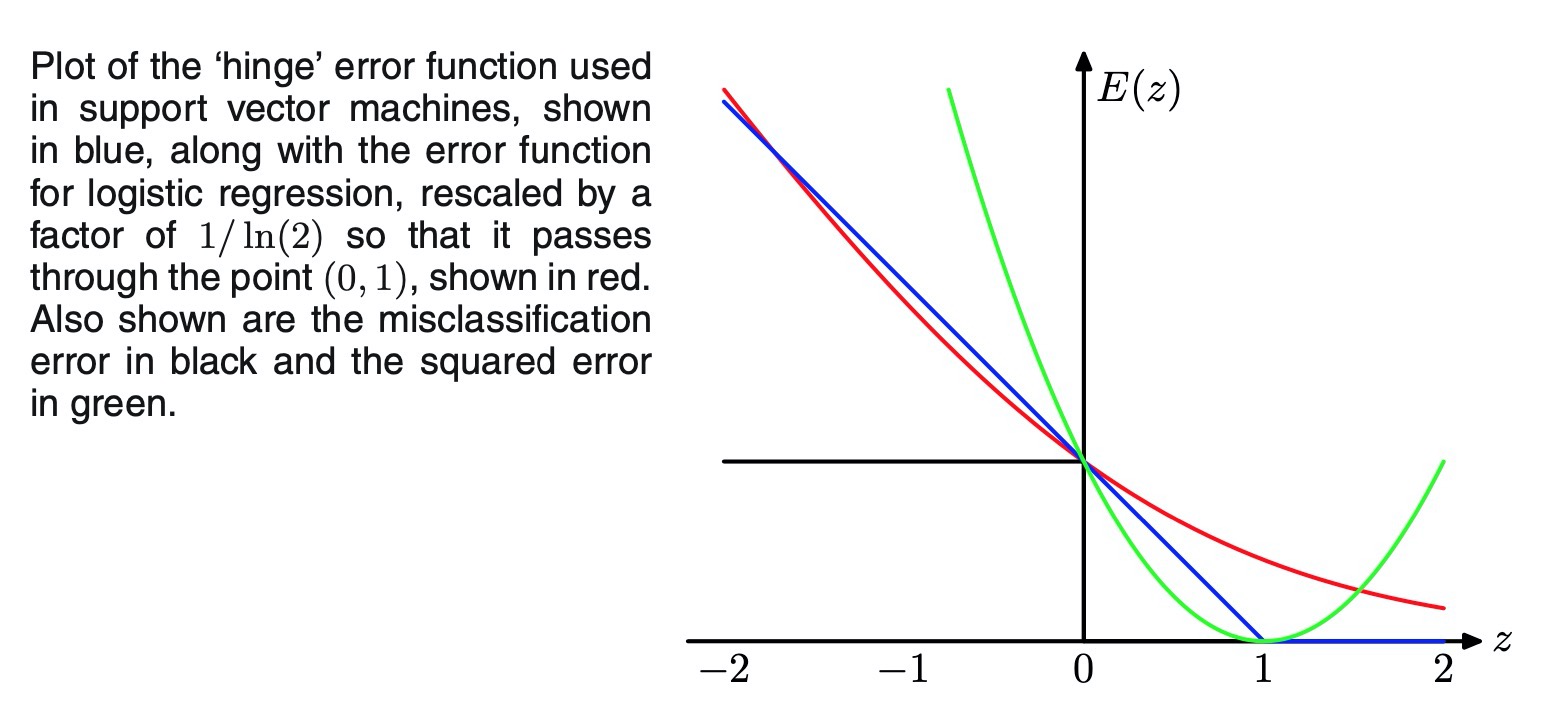
When we considered the logistic regression model in Section 4.3.2, we found it convenient to work with target variable . For comparison with the support vector machine, we first reformulate maximum likelihood logistic regression using the target variable .
To do this, we note that where is given by (7.1.1), and is the logistic sigmoid function. It follows that , where we have used the properties of the logistic sigmoid function, and so we can write
From this we can construct an error function by taking the negative logarithm of the likelihood function that, with a quadratic regularizer, takes the form
where
For comparison with other error functions, we can divide by so that the error function passes through the point (0, 1). This rescaled error function is also plotted in Figure above and we see that it has a similar form to the support vector error function. The key difference is that the flat region in leads to sparse solutions.
Error Function Comparison
Both the logistic error and the hinge loss can be viewed as continuous approx- imations to the misclassification error. Another continuous error function that has sometimes been used to solve classification problems is the squared error, which is again plotted in Figure above. It has the property, however, of placing increasing emphasis on data points that are correctly classified but that are a long way from the decision boundary on the correct side. Such points will be strongly weighted at the expense of misclassified points, and so if the objective is to minimize the mis- classification rate, then a monotonically decreasing error function would be a better choice.
Multiclass SVMs
The support vector machine is fundamentally a two-class classifier. In practice, however, we often have to tackle problems involving K > 2 classes. Various meth- ods have therefore been proposed for combining multiple two-class SVMs in order to build a multiclass classifier.
SVMs for regression
We now extend support vector machines to regression problems while at the same time preserving the property of sparseness.
In simple linear regression, we minimize a regularized error function given by
To obtain sparse solutions, the quadratic error function is replaced by an -insensitive error function (Vapnik, 1995), which gives zero error if the absolute difference between the prediction and the target t is less than where . A simple example of an -insensitive error function, having a linear cost associated with errors outside the insensitive region, is given by
and is illustrated in Figure follow
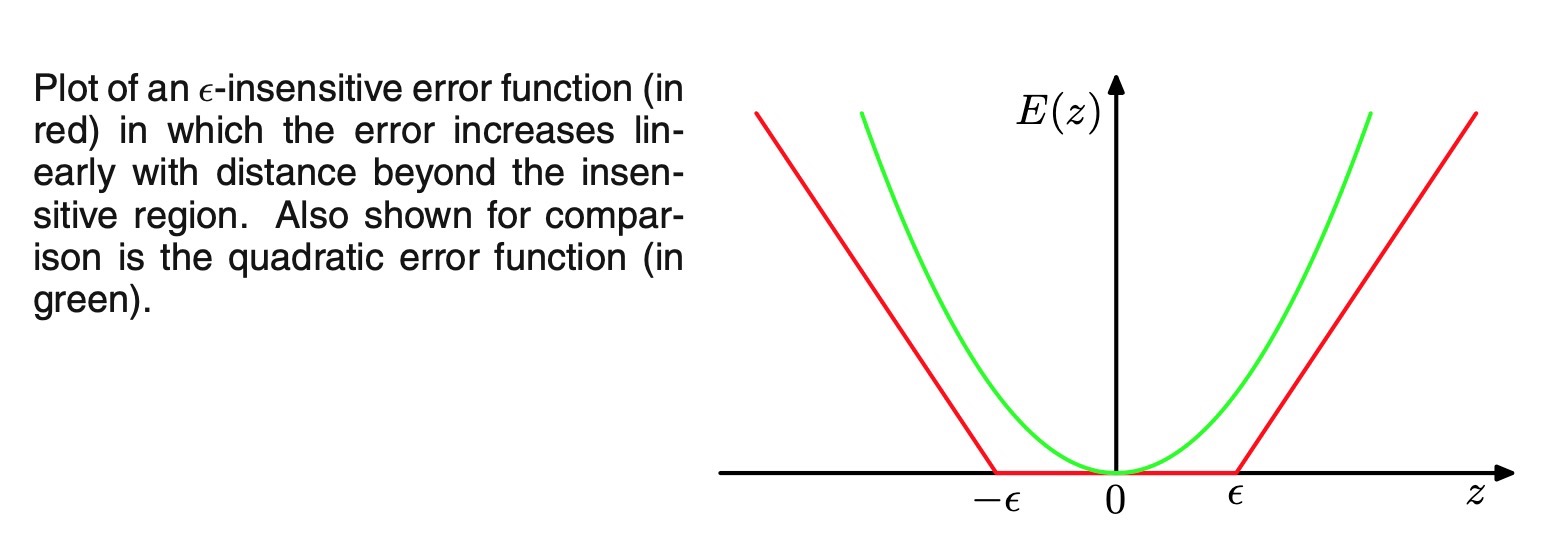
We therefore minimize a regularized error function given by
where is given by (7.1.1). By convention the (inverse) regularization parameter, denoted C, appears in front of the error term.
As before, we can re-express the optimization problem by introducing slack variables. For each data point , we now need two slack variables and , where corresponds to a point for which ,and corresponds to a point for which , as illustrated in Figure follow.
The condition for a target point to lie inside the -tube is that , where . Introducing the slack variables allows points to lie outside the tube provided the slack variables are nonzero, and the corresponding conditions are
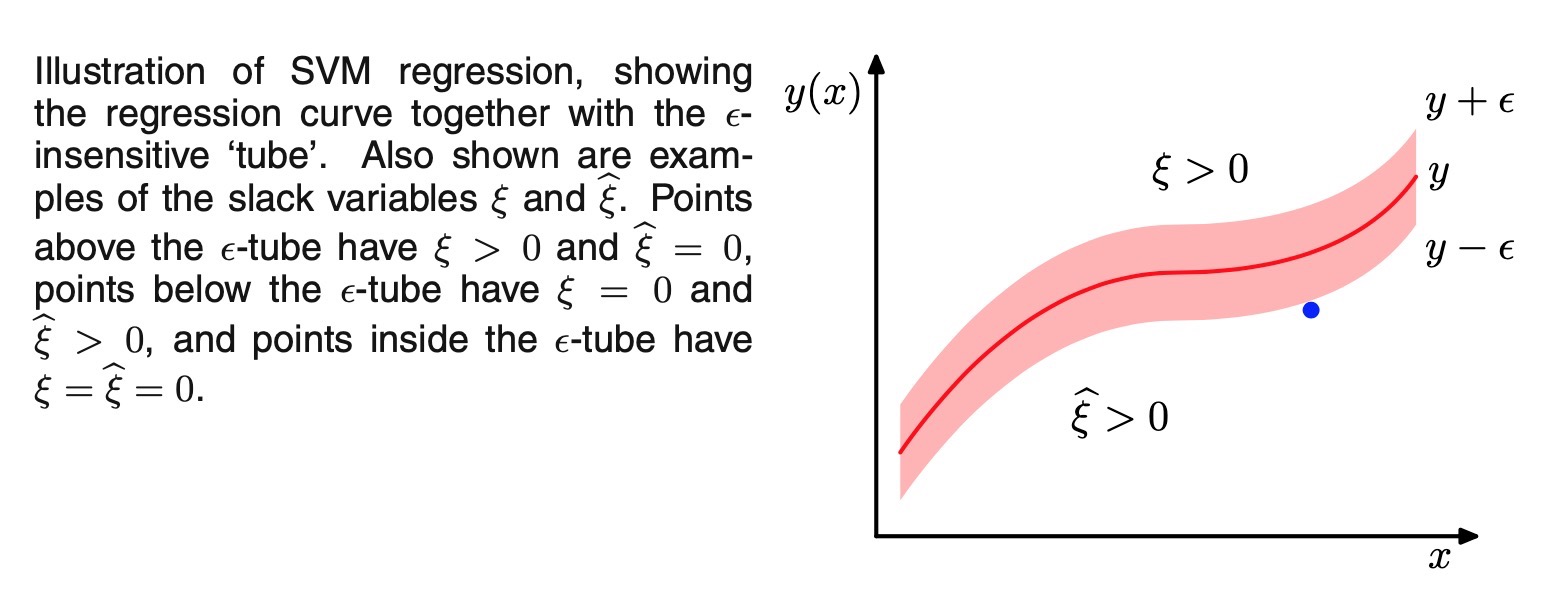
The error function for support vector regression can then be written as
which must be minimized subject to the constraints and and the (7.1.37).
This can be achieved by introducing Lagrange multipliers and optimizing the Lagrangian
We now substitute for y(x) using (7.1.1) and then set the derivatives of the Lagrangian with respect to , b, , and to zero, giving
Using these results to eliminate the corresponding variables from the Lagrangian, we see that the dual problem involves maximizing
with respect to and , where we have introduced the kernel .
Again, this is a constrained maximization, and to find the constraints we note that and are both required because these are Lagrange multipliers. Also and together with (7.1.42) and (7.1.43), require and , and so again we have the box constraints
together with the condition (7.1.41).
Substituting (7.1.40) into (7.1.1), we see that predictions for new inputs can be made
which is again expressed in terms of the kernel function.
The corresponding Karush-Kuhn-Tucker (KKT) conditions, which state that at
the solution the product of the dual variables and the constraints must vanish, are given by
From these we can obtain several useful results.
First of all, we note that a coefficient an can only be nonzero if ,which implies that the data point either lies on the upper boundary of the -tube () or lies above the upper boundary ().
Similarly, a nonzero value for an implies , and such points must lie either on or below the lower boundary of the -tube.
Furthermore, the two constraints and are incompatible, as is easily seen by adding them together and noting that and are nonnegative while is strictly positive, and so for every data point , either or (or both) must be zero.
The support vectors are those data points that contribute to predictions given by (7.1.46), in other words those for which either an or . These are points that lie on the boundary of the -tube or outside the tube. All points within the tube have . We again have a sparse solution, and the only terms that have to be evaluated in the predictive model (7.1.46) are those that involve the support vectors.
The parameter can be found by considering a data point for which , which from (7.1.47- line 3) must have , and from (7.1.47-line 1) must therefore satisfy . Using (7.1.1) and solving for , we obtain
where we have used (7.1.40). We can obtain an analogous result by considering a point for which . In practice, it is better to average over all such estimates of b.
Computational learning theory
[Skip]
Relevance Vector Machines
[TODO]
Graphical Models
We shall find it highly advantageous to augment the analysis using diagrammatic representations of probability distributions, called probabilistic graphical models. These offer several useful properties:
- They provide a simple way to visualize the structure of a probabilistic model and can be used to design and motivate new models.
- Insights into the properties of the model, including conditional independence properties, can be obtained by inspection of the graph.
- Complex computations, required to perform inference and learning in sophis- ticated models, can be expressed in terms of graphical manipulations, in which underlying mathematical expressions are carried along implicitly.
A graph comprises nodes (also called vertices) connected by links (also known as edges or arcs). In a probabilistic graphical model, each node represents a random variable (or group of random variables), and the links express probabilistic relationships between these variables. The graph then captures the way in which the joint distribution over all of the random variables can be decomposed into a product of factors each depending only on a subset of the variables.
We shall begin by discussing Bayesian networks, also known as directed graphical models, in which the links of the graphs have a particular directionality indicated by arrows. The other major class of graphical models are Markov random fields, also known as undirected graphical models, in which the links do not carry arrows and have no directional significance. Directed graphs are useful for expressing causal relationships between random variables, whereas undirected graphs are better suited to expressing soft con- straints between random variables. For the purposes of solving inference problems, it is often convenient to convert both directed and undirected graphs into a different representation called a factor graph.
Bayesian Networks
[TODO]
Conditional Independence
An important concept for probability distributions over multiple variables is that of conditional independence.
Markov Random Fields
We have seen that directed graphical models specify a factorization of the joint dis- tribution over a set of variables into a product of local conditional distributions. They also define a set of conditional independence properties that must be satisfied by any distribution that factorizes according to the graph. We turn now to the second ma- jor class of graphical models that are described by undirected graphs and that again specify both a factorization and a set of conditional independence relations.
A Markov random field, also known as a Markov network or an undirected graphical model (Kindermann and Snell, 1980), has a set of nodes each of which corresponds to a variable or group of variables, as well as a set of links each of which connects a pair of nodes. The links are undirected, that is they do not carry arrows. In the case of undirected graphs, it is convenient to begin with a discussion of conditional independence properties.
Inference in Graphical Models
We turn now to the problem of inference in graphical models, in which some of the nodes in a graph are clamped to observed values, and we wish to compute the posterior distributions of one or more subsets of other nodes.
we can exploit the graphical structure both to find efficient algorithms for inference, and to make the structure of those algorithms transparent. Specifically, we shall see that many algorithms can be expressed in terms of the propagation of local messages around the graph. In this section, we shall focus primarily on techniques for exact inference
Mixture Models and EM
If we define a joint distribution over observed and latent variables, the corresponding distribution of the observed variables alone is obtained by marginalization. This allows relatively complex marginal distributions over observed variables to be expressed in terms of more tractable joint distributions over the expanded space of observed and latent variables. The introduction of latent variables thereby allows complicated distributions to be formed from simpler components.
In this section, we shall see that mixture distributions, such as the Gaussian mixture discussed in Section 2.3.9, can be interpreted in terms of discrete latent variables. Continuous latent variables will form the subject of Section 12.
As well as providing a framework for building more complex probability dis- tributions, mixture models can also be used to cluster data. We therefore begin our discussion of mixture distributions by considering the problem of finding clusters in a set of data points, which we approach first using a nonprobabilistic technique called the K-means algorithm (Lloyd, 1982). Then we introduce the latent variable view of mixture distributions in which the discrete latent variables can be interpreted as defining assignments of data points to specific components of the mixture. A gen- eral technique for finding maximum likelihood estimators in latent variable models is the expectation-maximization (EM) algorithm. We first of all use the Gaussian mixture distribution to motivate the EM algorithm in a fairly informal way, and then we give a more careful treatment based on the latent variable viewpoint. We shall see that the K-means algorithm corresponds to a particular nonprobabilistic limit of EM applied to mixtures of Gaussians. Finally, we discuss EM in some generality.
Gaussian mixture models are widely used in data mining, pattern recognition, machine learning, and statistical analysis. In many applications, their parameters are determined by maximum likelihood, typically using the EM algorithm.
K-means Clustering
[TODO]
Mixtures of Gaussians
[TODO]
An Alternative View of EM
[TODO]
The EM Algorithm in General
[TODO]
Approximate Inference
[SKIP]
Sampling Methods
[VIP_TODO]
For most probabilistic models of practical interest, exact inference is intractable, and so we have to resort to some form of approximation. Here we consider approximate inference methods based on numerical sampling, also known as Monte Carlo techniques.
Although for some applications the posterior distribution over unobserved variables will be of direct interest in itself, for most situations the posterior distribution is required primarily for the purpose of evaluating expectations, for example in order to make predictions. The fundamental problem that we therefore wish to address in this chapter involves finding the expectation of some function f (z) with respect to a probability distribution p(z). Here, the components of z might comprise discrete or continuous variables or some combination of the two.
Thus in the case of continuous variables, we wish to evaluate the expectation
where the integral is replaced by summation in the case of discrete variables. This is illustrated schematically for a single continuous variable in Figure 11.1. We shall suppose that such expectations are too complex to be evaluated exactly using analyt- ical techniques.
Basic Sampling Algorithms
Markov Chain Monte Carlo
Gibbs Sampling
Slice Sampling
The Hybrid Monte Carlo Algorithm
Estimating the Partition Function
Continuous Latent Variables
[TODO_VIP]
Principal Component Analysis
Probabilistic PCA
Kernel PCA
Nonlinear Latent Variable Models
Sequential Data
[TODO_VIP]
Markov Models
Hidden Markov Models
Linear Dynamical Systems
Combining Models
[SKIP]